Методологический подход к определению влияния человеческого фактора на работоспособность информационных систем
Время на прочтение
12 мин
Количество просмотров 18K

В статье изложен методологический подход к определению степени влияния человеческого фактора на функционирование больших информационных систем.
Введение
Современные информационные технологии и инновационные компьютерные и телекоммуникационные аппаратно-программные решения позволяют по-новому подойти к проблемам создания, сопровождения и модернизации больших корпоративных информационных систем.
Рассматривая такие системы, нельзя не учитывать роль человека, для облегчения труда которого, собственно, и создаются подобные системы. Человеко-машинная система, в которой человек или группа людей взаимодействует с техническим устройством в процессе производства материальных ценностей, управления, обработки информации, выполняет свои задачи благодаря совместной работе устройств и людей, которые рассматриваются как неотъемлемые составляющие части всей системы. При этом следует отметить, что любая такая система является уязвимой в силу своей зависимости от множества разнородных факторов.
По данным за период с 1996 г. Корпорации по исследованиям в области планирования на случай возникновения чрезвычайной ситуации в банках МВФ 10% угроз отказов информационных систем исходит от обслуживающего персонала. По другим данным американских источников, в целом степень влияния человеческого фактора на информационные системы еще выше и составляет до 30%, причем до 18% из них приходится на небрежное и халатное отношение к обработке или вводу информации.
Не менее важен вопрос защиты информационных систем от угроз, которым они могут подвергаться, и участия человека в этом вопросе. Согласно одному из проводимых опросов, проводимых в 2005 году, в России самой серьезной угрозой названы непреднамеренные ошибки сотрудников [5].
Человеко-машинная система — не автомат, поэтому одним из решающих факторов, влияющих на работу системы, является непредсказуемый человеческий фактор, оценке роли и важности которого и посвящена данная работа.
1. Основные понятия и определения
Любая большая информационная система не может полностью работать в автоматическом режиме. Всегда найдутся операции, которые в силу своей специфики невозможно или слишком «дорого» автоматизировать. Чем больше таких операций, особенно в основной технологической цепочке работы информационной системы, тем более зависимой она становится от индивидуальных свойств человека. Отметим ряд типичных характеристик человека, взаимодействующего с информационной системой, от которых зависит и его способность принимать решения в штатных и аварийных ситуациях.
- способность к адаптации,
- способность к утомлению,
- способность к отдыху,
- возможность совершения ошибки,
- способность принимать решения,
- способность запоминания информации,
- способность переносить информационную перегрузку,
- способность к обучению [1].
Рассмотрим количественную оценку влияния человеческого фактора на такое важное свойство, как доступность (или, что то же самое, коэффициент готовности) информационной системы.
Коэффициент готовности
Кг – вероятность того, что система окажется в работоспособном состоянии в произвольный момент времени. Это комплексная характеристика безотказности и ремонтопригодности системы, которая характеризуется показателями ремонтопригодности: То – среднее время наработки на отказ и Тв – среднее время восстановления после отказа.
Коэффициент готовности определяется как: 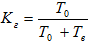
Доступность
(D) обычно в отличие от коэффициента готовности выражается в процентах, или D = Кг * 100 %.
Человеческий фактор влияет также на достоверность, своевременность и полноту обработки информации, вводимой и хранящейся в базе данных информационной системы. При длительном монотонном вводе данных, в процессе утомления человек начинает делать ошибки при вводе, пропускать данные, перестает укладываться во временные регламенты.
Учет такой характеристики, как способность к утомлению оценивается следующим образом. При работе в благоприятных условиях, средняя выработка в последние часы уменьшается на 6-7% за каждый час удлинения рабочего дня свыше 6 часов (т.е. за седьмой час производительность составляет 94%, за восьмой – 88%, за девятый – 81% и т.д.).
Степень влияния человеческого фактора на достоверность данных, вводимых в информационную систему при монотонном выполнении операции ввода, можно оценить, используя значения, приведенные в Таблице 1.
Таблица 1. Влияние человеческого фактора на достоверность ввода информации
| Время работы (часы работы) | ||||||
|---|---|---|---|---|---|---|
| 1-ый – 6-ой | 7-ой | 8-ой | 9-ый | 10-ый | 11-ый | |
| Производительность (% от нормы) | 100 | 94 | 88 | 81 | 74 | 67 |
| Процент безошибочности | 0,96 | 0,9 | 0,85 | 0,78 | 0,71 | 0,64 |
| Реальное время операции с учетом повторных работ (часов) |
6,25 | 1,11 | 1,18 | 1,28 | 1,4 | 1,56 |
| Достоверность результатов ввода (процент ошибок с учетом логических проверок и повторного ввода) |
0,999 | 0,996 | 0,994 | 0,991 | 0,988 | 0,985 |
| Верхняя граница достоверности | 0,9995 | 0,998 | 0,997 | 0,995 | 0,993 | 0,991 |
| Нижняя граница достоверности | 0,997 | 0,993 | 0,991 | 0,987 | 0,983 | 0,979 |
Одним из важных вопросов в обсуждаемой проблеме является вопрос «квалификации» сотрудника, обслуживающего информационную систему. Сотрудники с низкой квалификацией и новички должны обязательно проходить этапы обучения и тренировки работы с системой, которая, в свою очередь, должна быть хорошо документирована.
2. Методологический подход к определению влияния человеческого фактора на работоспособность информационной системы
Человек, как звено любой человеко-машинной системы, безусловно, влияет на показатели надежности и эффективности (полноты, достоверности, своевременности обработки информации) информационной системы в целом и ее отдельных подсистем и задач.Методология оценки влияния человеческого фактора на работу информационной системы является смешанной дисциплиной, в которой необходимо учитывать влияние ошибок человека на ее надежность, а также психологические особенности человека как звена это информационной системы.
Влияние человеческого фактора, а именно операторов, обслуживающего персонала сервисных центров и пр., на работу информационной системы может быть количественно определено степенью воздействия ошибок персонала на безопасность и производительность информационной системы.
Многие процессы в человеко-машинных системах содержат потенциальные возможности для ошибок персонала, в особенности в тех случаях, когда время, которым располагает оператор для принятия решений, ограничено. При этом вероятность того, что проблемы будут развиваться негативным образом, зачастую мала. Порой действия со стороны персонала ограничиваются возможностью предотвращения начальной неисправности, прогрессирующей в направлении аварийной ситуации.
Тем не менее, необходимо идентифицировать разнообразные типы ошибочных действий, которые могут иметь место, в том числе:
а) ошибка по оплошности, недосмотр, выразившийся в невыполнении требуемого действия информационной системы;
б) ошибка несоответствия, которая может предусматривать:
- положение, когда требуемое действие не выполняется должным образом (например, не выполнение регламента администрирования базы данных);
- действие, выполняемое слишком большим или слишком малым усилием, либо без требуемой точности (например, неточности при заполнении форм ввода, ошибки неточного ввода данных и т.д.);
- действие, выполняемое в неподходящее для него время (например, несвоевременный ввод информации, задержка обработки информации и т.д.);
- действие, выполняемое с нарушением очередности исполнения (например, подготовка итогового аналитического отчета при незавершенном процессе обработки данных);
в) лишнее действие, выполняемое вместо требуемого действия или в дополнение к нему (например, повторные вводы одних и тех же сведений, что может привести к расхождениям в сведениях или появлением дублирующих данных).
Степень влияния человеческого фактора на надежность системы можно оценить по вероятности проявления ошибок в процессе ручного ввода данных. Ошибка оператора всегда связана с неверной интерпретацией поступивших и анализируемых им данных. Считается, что для сложных технических приборов и сложных компьютерных задач вероятность ошибки может достигать 15%, для простых технических устройств и несложных компьютерных задач вероятность ошибки составляет от 1% до 5% [1].
Безошибочность действий оператора зависит от многих факторов:
- дефицит времени (частота совершения ошибок при обработке информации является логарифмической функцией скорости поступления информации);
- перегрузка информацией (количество ошибок возрастает при перегрузке, в частности, при увеличении числа источников информации);
- степень подготовки (более подготовленные специалисты совершают в среднем меньше ошибок);
- психологические особенности человека (кроме того, работа, выполняемая с интересом, как правило, менее ошибочна);
- «сенсорный голод» (увеличение частоты ошибок при длительном выполнении монотонной работы из-за малой нагрузки органов чувств).
Важную роль в вопросе уменьшении количества ошибок играет степень подготовленности оператора. Считается [1], что в процессе обучения частота возникновения ошибок имеет тенденцию к уменьшению, причем эту зависимость можно аппроксимировать формулой:
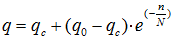
, где
- q – частота ошибок после обучения;
- q0 – начальное значение частоты ошибок (до обучения);
- qc – установившееся стационарное значение частоты ошибок (для обученных операторов);
- n – накопленная сумма операций ввода, выполненных оператором в предыдущих циклах обучения (работы);
- N – «постоянная обучения», характеризующая продолжительность обучения оператора.
При n = N, разность (q0> – qc) уменьшается на 63%. Считается [1], что значение qc достигается через 4 – 5 N. При этом если обозначить за n1 – количество вводов информации, при котором выполняется q = qc, то:

Полученное значение N определяет необходимое количество вводов информации, составляющее один цикл обучения (тренировки) работы с информационной системой.
По экспериментальным данным, полученным при отработке операторами зрительных сигналов [3], вычислены следующие значения перечисленных выше параметров:
- q0 = 0,27 (новички, не умеющие работать с информационной системой),
- qc = 0,018 (операторы, прошедшие 4 и более тренировок)
В предположении, что совсем не обученных работе с информационной системой операторов, как правило, нет, процент ошибок q0 = 0,27 не достигается. За максимальное значение может быть принят показатель q01 = 0,15 (см. [2]).
Тогда коэффициент учета ошибок этапа ручного ввода можно вычислить по формуле:
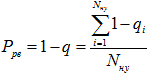
, где Pрв – вероятность безошибочности этапа ручного ввода оценивается для каждого ручного процесса отдельно; если процессы последовательные, коэффициенты перемножаются, т.е.

, где
- M – количество последовательных процессов ручного ввода,
- Nн.у.– количество операторов, по которым собрана статистика об ошибках.
Вероятность появления ошибки оператора существенно зависит от скорости поступления информации. Согласно [1], вероятность проявления ошибки в зависимости от скорости поступления информации V (бит/с) можно представить следующей формулой:
qрв = 9,7 10-4 V1,77
Важность задачи оценки влияния человеческого фактора может быть проиллюстрирована хотя бы аварийной ситуацией, имевшей место при эксплуатации одной из крупных распределенных информационных систем в августе 2005 года, когда ошибочные действия оператора привели к уничтожению рабочей базы данных, а ее восстановление заняло несколько дней. Ситуация была вызвана тем, что оператор в нарушение инструкции не создавал каждую неделю резервные копии базы данных, мотивируя это тем, операция резервного копирования требует длительного времени. Такого рода аварии (авторам известны более двух десятков подобных ситуаций, возникавших в разное время на реальных больших информационных систем) являются предостережением от тех оценок риска, которые концентрируют внимание исключительно на технических и программных средствах информационных систем и игнорируют ошибки персонала.
Кроме определения возможности возникновения катастрофических ситуаций вследствие влияния человеческого фактора, полезно определить ошибки, снижающие производительность, эффективность решения поставленной задачи в информационной системе.
Методологический подход к определению влияния человеческого фактора может включать в себя следующие этапы:
- анализ задачи или подсистемы информационной системы;
- определение степени загруженности задач и подсистем «ручными» операциями, выполняемыми персоналом;
- определение возможных ошибок персонала;
- количественное или качественное определение влияния человеческого фактора на надежность информационной системы и достоверность хранящейся в ней информации;
- рекомендации по автоматизации задач информационной системы, направленные на снижение влияния человеческого фактора.
На стадиях обследования «ручных» операций и выявления ошибок персонала идентифицируются и описываются возможные ошибочные действия при исполнении задачи. Определение ошибок персонала может включать выявление возможных последствий и причин ошибочных действий, а также предложение мер по снижению вероятности этой ошибки, совершенствованию перспектив для исправления и/или уменьшению последствий ошибочных действий. Результаты обследования «ручных» операций и рекомендации по их автоматизации, таким образом, обеспечивают ценный вклад в управление рисками в информационных системах даже в случае, если не проводится никакая количественная оценка влияния человеческого фактора.
Количественная оценка влияния человеческого фактора на надежность и эффективность информационной системы имеет целью оценить вероятности правильного выполнения той или иной задачи (P) или вероятности ошибочных действий (Q = 1 – P). Можно также предусматривать шаги по оценке вероятности или частоты определенных последовательностей нежелательных событий или нежелательных исходов.
Вероятность правильного выполнения оператором своей задачи Pрв во время выполнения ручной операции с обязательной проверкой в зависимости от степени подготовленности к работе с информационной системой, составляет
0,985 <= Pрв <= 0,999
или в среднем Pрв = 0,995
Другими словами, вероятность безошибочного выполнения ручной операции человеком (Pрв) будет находиться в диапазоне от 0,985 до 0,999 в зависимости от квалификации, степени утомления, степени перегруженности работой и пр. Вероятность совершения ошибки (Qрв) будет находиться в диапазоне от 0,001 до 0,015 (от 0,1% до 1,5% вводимых данных). Более полную зависимость Pрв от длительности выполнения монотонной работы можно посмотреть в Таблице 1.
Для ручных операций ввода данных, выполняемых в сложной задаче (большая информационная нагрузка, сложный интерфейс) без контрольной проверки, значения Pрв будут лежать в диапазоне от 0,85 до 0,982 [1, 2]. Иными словами, вероятность совершения ошибки (Qрв) будет находиться в диапазоне от 0,018 до 0,15 (от 1,8% до 15%). В простых задачах Qрв будет находиться в диапазоне от 0,01 до 0,05 (от 1% до 5%) .
В целом же для информационной системы и ее основных частей важно выявить степень зависимости ее отдельных задач и подсистем от операций, выполняемых «вручную», определить, можно ли автоматизировать ручные операции. Для операций, которые по каким-то причинам автоматизировать трудно (принципиальная невозможность, дороговизна работ по автоматизации), необходимо разработать организационные или другие меры, снижающие возможность влияния индивидуальных свойств человека на работу информационной системы (документирование, обучение, разработка кратких памяток и аварийных инструкций).
Основной возможностью снизить влияние человеческого фактора на систему, является автоматизация операций в системе, максимальное сокращение обязательных операций, выполняемых человеком.
Безусловно, имеются операции, которые автоматизировать невозможно или дорого по затратам ресурсов (например, не автоматизируемая семантическая операция и др.), но в этом случае, как правило, можно принять организационные и другие меры для снижения влияния человеческого фактора.
В случае отсутствия данных для точного определения уровня автоматизации можно использовать грубую качественную оценку степени загруженности задачи «ручными» операциями: «очень высокая», «высокая», «средняя», «низкая», а также оценку хорошо это или плохо для данной задачи или подсистемы. Предлагаемые оценки характеризуются оценкой процента выполняемых в задаче ручных операций, а также трудоемкостью ввода данных, сложностью работы с пользовательским интерфейсом, темпом выполнения работы.
Применение математического аппарата оценки достоверности данных в зависимости от ошибок ручного ввода, приведенного в [2], позволяет составить таблицу зависимости ошибок ручного ввода от степени загруженности задачи «ручными» операциями (см. Таблица 2). Вероятность ввода ошибочных сведений лежит в указанном диапазоне и зависит от квалификации оператора, степени усталости и скорости ввода информации.
В таблице, приведенной ниже, показана оценка возможного ошибочного ввода данных, в зависимости от внешних условий.
Таблица 2. Примерный процент сведений, содержащих ошибки в зависимости от степени загруженности задачи ручными операциями
| Степень загруженности задачи ручными операциями | Оценка процента ошибок ввода данных Qрв * | |
|---|---|---|
| Ручная операция выполнена с проверкой | Ручная операция выполнена без проверки | |
| Низкая | 0,0001 – 0,003 (0,01 – 0,3 %) |
0,01 – 0,05 (1 – 5 %) |
| Средняя | 0,001 – 0,010 (0,1 – 1,0 %) |
0,02 – 0,10 (2 – 10 %) |
| Высокая | 0,001 – 0,015 (0,1 – 1,5 %) |
0,02 – 0,12 (2 – 12 %) |
| Очень высокая | 0,003 – 0,022 (0,3 – 2,2 %) |
0,05 – 0,15 (5 – 15 %) |
* без учета влияния утомления на результаты работы
В свою очередь степень загруженности задачи (подсистемы) ручными операциями предлагается оценить следующим образом (см. Таблица 3). Таблицы ячейки заполняются по следующему принципу: в зависимости от оценки, указанной в заголовке колонки №3, строки колонки 3 заполняются нулем или единицей. Тогда последняя строка, содержащая сумму всех предыдущих, характеризует степень загруженности задачи ручными операциями.
Таблица 3. Оценка степени загруженности задачи ручными операциями
| № | Характеристика | Оценка: высокая – 1, низкая – 0 |
|---|---|---|
| 1 | Оценка количества выполняемых в задаче ручных операций | 0 или 1 |
| 2 | Трудоемкость ввода данных | 0 или 1 |
| 3 | Сложность работы с пользовательским интерфейсом | 0 или 1 |
| 4 | Темп выполнения «ручной» работы | 0 или 1 |
| 5 | Итого (степень загруженности): | 1 – Низкая 2 – Средняя 3 – Высокая 4 – Очень высокая |
Если каждую подсистему или задачу системы проанализировать согласно вышеприведенному алгоритму и заполнить для нее Таблицу 3, то можно оценить влияние человеческого фактора в рамках конкретной задачи (подсистемы) на достоверность вводимых данных (см. Таблица 2) и на показатели надежности системы в целом.
Используя данные, приведенные в Таблице 1, можно определить процент ошибок с учетом утомления человека в зависимости от времени работы.
Таким образом, приведенный выше методологический подход позволяет проводить оценку степени влияния человеческого фактора как для информационной системы в целом, так и для ее отдельных функций и подзадач используя данные, которые легко получить, не прибегая к методам статистического исследования.
Заключение
Общепризнано, что основные проблемы создания и внедрения информационных технологий в больших организационных системах сопряжены с влиянием человеческого фактора. [4] Более того, можно смело утверждать, что отсутствие оценки влияния этого показателя при проведении работ по анализу надежности, эффективности, целостности информационных систем, снижает точность получаемого результата.
Литература
- Дружинин Г.В. Человек в моделях технологий. Часть I: Свойства человека в технологических системах. – М.: МИИТ. 1996 – 124 с.
- Акимова Г.П., Соловьев А.В. Методология оценки надежности иерархических информационных систем. // Системный подход к управлению информацией. / Труды ИСА РАН. Т. 23. М.: КомКнига, 2006. С. 18 – 47.
- Цибулевский И.Е. Ошибочные реакции человека-оператора. – М.: Сов. Радио, 1979 – 208 с.
- Киреенко В.Е. Человеческий фактор корпоративных информационных систем (на примере Томского горисполкома). — Вестник Томского государственного университета №275, апрель 2002 г.
- Ветлугин К. Человеческий фактор. Computerworld №11, 2006
Вопрос 7. Достоверность обработки информации
при последовательном соединении операций техпроцессов.
Рассмотрим одну операцию техпроцесса —
1 операция (ручная (*) или машинная (**))
 обработка
обработка
информации:
•
ввод с клавиатуры в машину (*)
•
операция передачи данных
•
обработка завпроса в БД (**) ….
Дано:
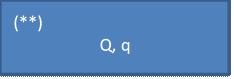
Q — кол-во
символов обрабат на операции (набор символов ![]() )
)
![]()
q -вероятность ошибки а 1
символ (см. таблицы)
Найти:
Вероятность того, что отсутствуют ошибки после выполнения операции
Решение:
Ручная обработка
A (нет ошибки) = (нет ош.1, нет ош.2, нет
ош.3, … нет ош.Q)
( )
( ) ( ) ( ) ( )

Q →∞ вероятность ошибки стремится к 1
Машинная обработка
Эмпирическая формула для расчета
вероятности отсутствия ошибки
![]()
•
t — время решения задачи
•
![]() – интенсивность отказов
– интенсивность отказов
•
10![]() – интенсивность сбоев
– интенсивность сбоев
Если t →∞ больше вероятность того, что
возникает ошибка (код надо делать маленький)
Последовательное соединение операций техпроцесса обработки
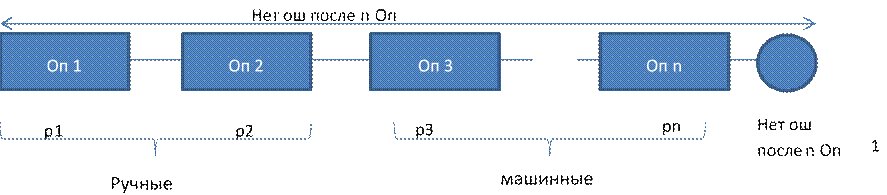
Операции
могут быть как ручные, так и машинные
Рассмотрим
событие
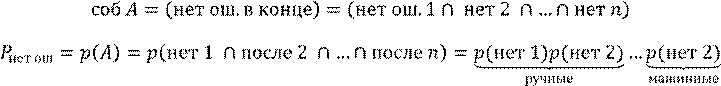

Должно
быть задано требование на вероятность отсутствия ошибки в конце техпроцесса.
Т.е. допустимая. Если фактическое значение меньше допустимого, то надо вводить
методы контроля и коррекции ошибок, например, … . Вводить на тех местах, где
наименьшее.
Параллельно-последовательное соединение операций техпроцесса обработки
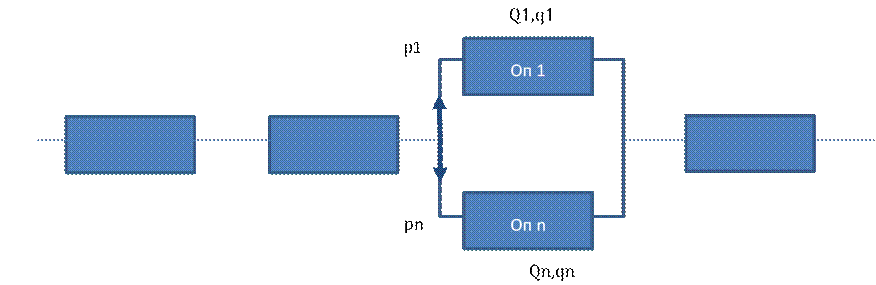
Рассмотрим
случай, где 2 операции параллельно. Рассмотрим событие А – нет ошибки
![]()
По формуле полной вероятность ![]()
![]()
Для n
элементов сумма n штук.
При
последовательно параллельном
![]()
2
В любой информационной системе задача состоит в
достижении максимальной достоверности передачи информации. Достоверность
информации определяется как степень адекватного отображения информацией
объективно существующих явлений, событий или процессов.
Достоверность связана с вероятностью возникновения
ошибок. Под ошибкой понимается случайное событие — искажение информации,
которое может быть обнаружено и зарегистрировано с определенной вероятностью.
Для расчета достоверности применяются различные
математические и логические приемы выявления ошибок, включаемые в компьютерные
программы, а также многократное повторение передачи одинаковых данных.
Для
проекта №1:
Требуется
рассчитать достоверность информации для задачи ввода информации о клиенте в
базу данных оператором. Достоверность информации должна быть не меньше 0,999
после каждого техпроцесса рассматриваемой задачи.
Изобразим
схему внесения информации в БД:

Рис.2.4.1
Схема внесения информации в БД
1) Вероятность
искажения информации при ручном вводе с клавиатуры ![]()
2)
Вероятность обнаружения ошибки оператором при самоконтроле ![]()
3)
Интенсивность сбоев сервера БД ![]()
4)
Интенсивность сбоев ЛВС ![]()
5) Объем
вводимых символов:
Таблица
2.4.1 Объем вводимых символов
|
Наименование поля |
Длина, байт |
|
Код клиента |
10 |
|
Имя |
20 |
|
Фамилия |
30 |
|
Отчество |
30 |
|
Номер телефона |
15 |
|
Адрес |
45 |
|
Итого |
150 |
Примем Q = 170 (с
учетом преамбулы, адреса получателя и отправителя, поля контрольной суммы).
1.
Пропускная
способность сегмента 100 BaseTX – 95 мбит/с
2. Пропускная
способность коммутатора HP 2530-48G — 104
Гбит/сек
3.
Доступ
к жесткому диску 8,5 мс
4.
Скорость
записи 500 Мбит/с
1) Сделаем
расчет достоверности для ручной операции ввода сведений о новом клиенте.
Вероятность искажения информации после
выполнения ручной операции ввода при условии независимой посимвольной обработки
определяется как:
![]() ,
,
Где qi
– вероятность искажения единицы обрабатываемой информации,
Qi – объем единиц
обрабатываемой информации.
![]()
Достоверность
обработки информации в таком случае:
![]() 0,84359306
0,84359306
![]()
Введем схему контроля ошибок при ручном
вводе:
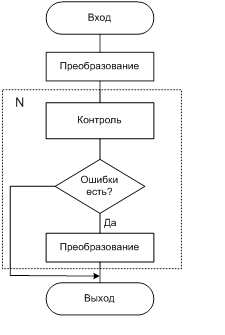
Рис.2.4.2
Схема контроля ошибок при ручном вводе
Тогда
полная вероятность поступления искаженного символа данных на выход алгоритма
вычисляется по формуле умножения вероятностей:
k –
вероятность обнаружения ошибки при контроле,
r –
вероятность внесения ошибки после выполнения корректирующей операции,
N – количество операций контроля
![]()
![]()
![]() 0,031406513
0,031406513
![]() 0,968593487
0,968593487
![]()
![]() 0,006306428
0,006306428
![]() 0,993693572
0,993693572
![]()
![]() 0,001266331
0,001266331
![]() 0,998733669
0,998733669
![]()
![]() 0,000254279
0,000254279
![]() 0,999745721
0,999745721
Таким образом, для достижения допустимого значения достоверности
0,999 операции ввода данных с клавиатуры применим четырехкратный контроль.
2) Передача
данных по ЛВС
Уточним модель
достоверности для операции передачи информации по ЛВС:
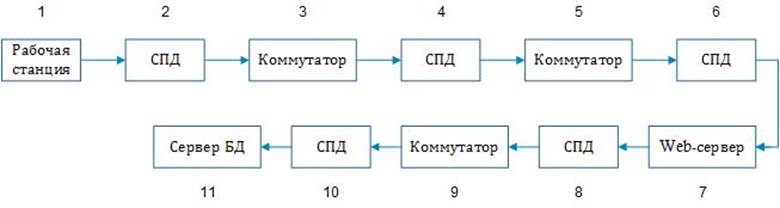
Рис.2.4.3
Модель достоверности для операции передачи информации по ЛВС
В
случае машинной обработки информации применяется эмпирическая формула для
расчета вероятности отсутствия ошибки после операции:
p
= e-10λt
где 10λ – интенсивность сбоев технических
устройств;
t — время обработки.
Рассчитаем время t передачи пакета длиной
170 байт = 1360 бит по узлам сети:
100Base-TX = 1360 бит / 100
Мбит/с = 13,6*10-6 с
HP 2530-48G= 1360 бит
/ 104 Гбит/с = 0,013*10-6 с
Web-сервер = 0,0015 с
t = 13,6*10-6
+ 0,013*10-6 + 13,6*10-6 + 0,013*10-6
+ 13,6*10-6 + 0,0015
+ 13,6*10-6 + 0,013*10-6
+ 13,6*10-6 = 0,001568039
с
λ = 0,001 1/час = 0,001/3600с
= 2,78*10-7 1/с
P2
= e^(-10
* 2,78*10-7 * 0,001568039)![]()
3)
Уточним модель достоверности
для операции сохранения информации на сервере БД:
10*![]() –
–
интенсивность сбоев технических устройств,
t –
время обработки.
![]() =
= ![]() 1/час =
1/час = ![]() /3600с = 1,06*10-8
/3600с = 1,06*10-8
1/с
T = Tдост + Tзаписи = 8,5*10-3 с + 3600 бит / 500*106
бит/с = 0,0085 c
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
В стандартном процессе обработки данных имеется ряд источников ошибок:
-
ошибки
в первичных данных (ошибки измерений,
сбои информационно – измерительных
систем) — намеренный ввод неправильных
сведений в оперативном режиме, сокращение
текста при вводе данных операторами,
ошибки в данных, полученных путем
обмена, ввод ошибочных данных клиентами,
использование различных форматов
данных в разных системах; -
ошибки,
возникающие в процессе эксплуатации
технологий обработки данных; -
ошибки,
связанные со сбоями вычислительной
техники, программных средств.
Ошибки
вычислительной техники на несколько
порядков менее вероятны, чем ошибки при
занесении данных на носитель. Ошибки в
первичных данных возникают из-за
несовершенства измерительных систем,
средств регистрации и передачи информации.
В результате могут появиться значения
параметров, выходящие за физически
допустимые пределы, ошибки в кодировании
значений ключевых характеристик,
появление двух одинаковых экземпляров
свойств объекта и др.
Можно
выделить четыре категории ошибок
(http://www.dwinfocenter.org/errors.html):
неполные данные, неправильные данные,
непонятные данные, непоследовательные
данные.
Неполные
данные –
т.е. в них имеются отсутствующие записи.
Чаще всего возникает по причине сбоев
в системах сбора данных. Сюда же относятся
отсутствующие
поля – задача
сбора данных решалась частным образом
– хотелось как можно быстрее создать
БД, при этом не думали о будущем. Записи
или поля которые при проектировании не
предусматривались, то есть это был
небрежный проект, без предварительного
исследования источников данных и
информационных потребностей пользователей.
Неправильные
данные — то
есть данные, имеющие ошибки, связаны с:
-
неправильным
применением кодов
— это обычно происходит, когда используются
старые протоколы обработки данных,
исторические данные; -
неправильными
расчетами, агрегацией — эта
ситуация возникает при загрузке уже
ранее вычисленных данных (необходимо
иметь исходные данные для проверки
результатов расчетов); -
ошибочным
вводом информации в источнике данных
– это связано с плохими формами ввода
(последовательность записи года, месяца,
дня в дате, плохое качество бумажного
источника, др.), здесь необходимы более
жесткие системы контроля ввода данных.
Непонятные
данные связаны с:
-
неправильным
парсингом кодов
– это плохо составленный алгоритм
конвертирования кодов или плохое
соответствие двух классификаторов; -
хранением
значений атрибутов в разных полях
— это ситуация, где источник передает
данные по различным каналам связи, на
различных носителях и форматах; -
дупликацией
данных —
возникает в пределах одной системы, а
особенно при объединении разных
источников информации; -
непродуманным
использованием схем форматирования,
чтобы уменьшить использование памяти,
например, можно хранить число в виде 4
байт, а можно сохранить в виде двух
байт, но при этом это число не может
превышать значение 32000,
другой пример, хранение цифровых данных
сначала в символьном виде, а затем в
виде числа – при преобразовании могут
исчезнуть значащие нули; -
применением
неизвестных кодов
– при анализе БД, можно найти неизвестные
значения кодов – это или ошибка при
вводе данных или ошибка в алгоритме
конвертирования – включен не тот код; -
ошибками
несовместимости
– эта категория охватывает наиболее
широкий диапазон проблем, это связано
с единицами измерения, ошибками в
представлении даты и времени,
непоследовательном использовании
различных кодов, др.; -
различными
кодами с одним тем же значением атрибута
– используются
два разных классификатора для одного
объекта; -
непоследовательными
именами и адресами
— это случай различных кодов с одним и
тем же значением, например, при изменении
названия организации можно вести новый
код, а можно создать таблицу «Жизненный
цикл изменения кодов».
Непоследовательные
данные
связаны с:
-
непоследовательными
правилами
получения
вычисленных
характеристик
– это когда значения поля вычисляются
неодинаково по разным формулам, в
зависимости от района, метода; -
непоследовательной
агрегацией данных
— это случай использования различных
правил при вычислении одних и тех же
статистических характеристик в
различных ситуациях, например, в области
исследования климата принят одинаковый
период обобщения данных (30 лет, каждые
5 лет производится пересчет); -
использованием
неодинаковых атомарных единиц
представления данных
– это бывает при использовании разных
моделей данных; -
разными
единицами оценки объемов данных в
логических единицах
— это случай разного использования
единиц хранения атомарной информации; -
непоследовательным
использованием атрибута
– например, можно в поле адрес хранить
всю информацию о клиенте, а можно
отдельно улицу, дом, почтовый индекс,
город, регион, страна, второй случай
более правильный; -
непоследовательной
датой — это
случай непоследовательного использования
атрибута, когда сливаются данные из
двух систем, в которых различная политика
использования дат (дата ввода измерения,
дата ввода в систему, дата передачи); -
непоследовательным
использованием пространства памяти,
пустых значений и так далее,
например, чтобы отмечать отсутствующие
измерения, забракованные или вычисленные
значения, необходимо иметь признак
качества для каждого такого значения
атрибута; -
отсутствием
ссылочной целостности
— может привести к ошибкам в значениях
одних и тех же атрибутов в разных
таблицах; -
не
синхронизированной агрегацией
— некоторая суммарная информация может
быть получена независимо в различных
таблицах, например, среднемесячное
значение можно получить путем агрегации
срочных значений, а можно на основе
среднесуточных значений; -
сложностью
ведения хранилища данных — увеличивается
геометрически со временем –
уходят
специалисты, которые знали данные,
алгоритмы и проблемы БД.
БД
представляют сложные человеко-машинные
системы, реальная достоверность сбора
первичной информации в которых
определяется как надежность работы
технических систем, так и ошибками,
вносимыми операторами. Основными
причинами
искажений
в процессе создания БД являются:
-
отсутствие
или неточность инструкции и стандартов
работы; -
несовершенство
или отсутствие макетов таблиц –
документов, нечеткость заполнения
первичных документов, смятие или
загрязненность первичных (машинных)
документов; -
сложность
применяемых классификаторов и форм
занесения данных, несоответствие макета
первичного документа форме ввода данных
на компьютере; -
недостаточная
квалификация оператора, недобросовестное
отношение к работе – небрежность,
невнимательность, халатность; -
неточность
в документации; -
плохая
организация хранения и учета носителей
информации; -
преднамеренное
искажение информации в корыстных целях; -
недостаточная
сознательность, безразличие и
безответственность в работе; -
организационные
недостатки в работе оператора –
отсутствие постоянного закрепленного
рабочего места, совместительство,
нарушения или отсутствие графика
работы, отвлечение на другие работы; -
обезличка
в работе и отсутствие контроля; -
отсутствие
морального и материального стимулирования
хорошей работы; -
низкая
трудовая дисциплина; -
неритмичность
в работе (много потерь времени на этап
врабатываемости); -
завышенный
темп работы, усталость, возбужденное
или угнетенное состояние оператора; -
недостатки
в организации рабочего места (плохое
освещение, шум), неудобная конструкция
рабочего места, плохая регулировка и
настройка (где лежит документ и
клавиатура); -
недостаточная
автоматизация ввода данных; -
сбои
измерительной системы (неправильная
работа датчика – погрешность измерения,
приближенная запись) и ЭВМ при вводе
данных (залипание клавиш; некачественность,
физический износ и старение технического
носителя; нарушение работоспособности
из-за климатических и механических
воздействий, флуктуации напряжения
питающей сети); -
сбои
аппаратуры при обработке данных
(ошибочное вычисление значения); -
искажения
в процессе передачи данных по каналам
связи (наводки и помехи атмосферного
и производственного характера, шум и
частотные искажения в каналах связи); -
ошибки в алгоритмах
и программах; -
форматные
ошибки (изменение формата атрибута,
количества байт, добавление или пропуск
символа, появление запрещенных символов
в атрибуте, сдвиг атрибутов, нарушающих
шаблон сообщения, пропуск или появление
дополнительных служебных символов,
изменение количества реквизитов).
Средняя
вероятность ошибки при вводе информации
с клавиатуры находится в диапазоне
(0.5-1.5) 10 -3
ошибок / символ.
Методы
контроля данных
Процесс
управления качеством данных можно
разделить на следующие этапы:
– определение
качества исходных данных;
– определение
правил обеспечения качества этих данных;
– разработка
процессов очистки данных;
– внедрение этих
процессов;
– контроль
данных.
Для
этапа исследования можно использовать
средства профилирования – они осуществляют
быстрый анализ данных во всех исходных
системах, выдавая заключение и предлагая
инструкции по построению обработки
данных. Определение и построение правил
обеспечения качества данных крайне
важно для стандартизации, сравнения и
консолидации данных.
Проверка
качества данных становится отдельным
этапом работ при загрузке БД. Обеспечение
качества данных – нетривиальная задача.
Основными методами контроля являются:
-
самоконтроль;
-
дублирование
операций (или части операций) при вводе
информации (двойной ввод); -
применение
помехоустойчивых кодов, базирующихся
на использовании признаков делимости
чисел (четность, нечетность) запрещении
использования некоторых символов,
введение избыточной информации в
передаваемые данные; -
осуществление
программно-логического контроля
(совместимость, непротиворечивость,
нахождение в некотором заданном
интервале значений, дополнение атрибутов
до заданного формата поля, контроль
существования значения атрибута,
сравнение из различных источников).
Для
сведения к минимуму потерь от случайных
искажений требуется создавать или
использовать уже готовые программы:
-
ведения
системного журнала СУБД, подробно
фиксирующего каждую операцию над БД
(описание транзакции, адреса компьютера,
пользователя, время, тип и адрес изменения
данных, значение данных до и после
выполнения транзакции); -
контроля
достоверности, использующие соответствующие
методы контроля данных; -
отката,
создания контрольных точек и повторного
исполнения транзакции, вызвавшей
искажение БД.
Учитывая
характер наиболее массовых ошибок,
целесообразно предусматривать три
категории алгоритмов качества данных
на каждом этапе преобразования информации:
-
контроль
соблюдения форматов записи данных на
носитель (синтаксический контроль); -
контроль
числовых значений параметров и ключевых
характеристик измерений при вводе
данных (семантический контроль); -
контроль
выходной информации из БД (прагматический
контроль).
Синтаксический
– это по существу контроль достоверности
данных, не затрагивающий содержательного
смыслового аспекта информации. Предметом
этого контроля являются контроль
форматов представления данных, шаблонов
и масок ввода данных, наличия атрибутов
(их номенклатуры), порядка следования,
наличие служебных признаков в структуре
сообщения, упорядоченности данных,
появления запрещенных символов,
комбинаций, полноты поступления первичной
информации и сопровождающих ее метаданных.
Семантический
контроль оценивает смысловое содержание
информации, его логичность,
непротиворечивость, диапазон возможных
значений параметров (предельные значения,
область значений), динамику их изменения,
возможных отклонений. Примером
семантического контроля могут служить
переписные листы населения, где двухлетний
мальчик показан женатым, а девятилетний
ребенок — грамотным.
Прагматический
контроль определяет потребительскую
ценность (полезность) информации для
пользователя, своевременность и
актуальность данных, их полноту и
доступность. Реализуется экспертной и
социологической оценкой данных.
При создании БД
очень часто используют средства очистки.
К сожалению, такой подход, позволяет
удалить только ошибочные данные. Средства
очистки данных выполняют базовые функции
контроля данных:
-
проверка
значений атрибутов БД на пределы
допустимого диапазона; -
проверка
орфографии; -
проверка
стандартных сокращений; -
поиск
неверных кодов.
По
назначению
контроль различается на профилактический,
рабочий и генезисный. Профилактический
– тестовый контроль надо проводить как
можно чаще, включать во все этапы
переработки. Рабочий контроль —
диагностический
(проверка работоспособности системы)
устанавливает места и причины
неисправности. Генезисный
контроль проводится для выяснения
технического состояния системы в прошлые
моменты времени с целью определения
причин сбоев и отказов системы, имевших
место в прошлом, сбор статистических
данных об ошибках, их характере – типах
ошибок, величине, последствиях этих
ошибок для пользователя.
По
способу реализации
контроль может быть организационный,
программный, аппаратный и комбинированный.
Организационный
контроль представляет собой комплекс
мероприятий, предназначенный для
выявления ошибок на всех этапах
переработки данных с участием человека.
Методами организационного контроля
являются разработка нормативных
документов, обучение, выборочная
проверка, контроль комплектности
документов, сроков и условий передачи
документов, условий и длительности
хранения технических носителей данных,
кондиционности бланков (носителей) и
качества их заполнения и визуальный
осмотр. Необходимо обеспечить правильный
подбор и обучение персонала, на который
будут возложены проведение наблюдения,
систематический контроль за ходом
наблюдений, широкая разъяснительная
работа. Следует предусмотреть
соответствующие меры во избежание
сознательного искажения фактов, приписок
и т.д., что является не только нарушением
государственной дисциплины, но и прямым
преступлением, наносящим вред интересам
дела.
Программный
контроль основан на программировании
логических методов проверки достоверности
данных. Примерами логического контроля
являются:
-
наличие
связей между отдельными измеряемыми
показателями, например, влажность,
измеренная и вычисленная по значениям
сухого и смоченного термометра; -
сравнение
с измеренными параметрами на соседнем
приборе, станции; -
экстраполяция
значений во времени, статистический
прогноз; -
интерполяция
данных между двумя измеренными значениями
во времени или пространстве; -
счетный
контроль заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Аппаратный
контроль – контроль значений параметров
на этапе измерений, включается в платы,
служащие для преобразования данных из
физических значений в натуральные
(сопротивление в температуру,
электропроводность в соленость воды,
и т.д.).
По
степени выявления и корректировки
ошибок контроль делится на:
-
обнаруживающий,
фиксирующий только сам факт наличия
или отсутствия ошибки; -
локализующий,
позволяющий определить и место ошибки,
например, искаженный символ, атрибут,
др.; -
исправляющий,
выполняющий функции обнаружения,
локализации и исправления ошибки.
Примерами
исправляющих методов являются:
-
анализ
текста свободного формата
для выявления в данных имен и адресов
позволяет идентифицировать компонент
имени, должности, организации и адреса
даже в случае непоследовательно
введенных данных (стандартизация слов,
связанных с описанием организации,
позволяет программе полностью проверить
данные об организации, включая сокращения,
и стандартизировать описание организации
в едином согласованном формате); -
стандартизация
представления значений некоторых полей
— данные
имен и адресов могут вводиться в
различных форматах, многие из которых
вполне грамматически корректны.
Например, «Улица», «Ул.» и «Ул»
обозначают одно и то же очевидное
понятие в составе адреса, существуют
и другие стандарты для этих и других
подобных случаев, программы стандартизации
трансформируют такие поля в согласованный
набор обозначений; -
проверка
допустимости — средства
распознавания допустимых международных
и национальных адресов, проверяют
допустимость адресных данных.
Оформление
результатов контроля данных
Данные
наблюдения считаются принятыми, если
они прошли контроль и, если потребовалось,
в них внесены исправления. Основными
показателями
качества контроля данных
являются:
-
экономические
– материальные, трудовые и временные
затраты на контроль; -
технико–эксплуатационные
– алгоритмическая сложность контроля,
вид и величина получаемой избыточности,
точность и надежность контроля,
универсальность — возможность использовать
на различных этапах технологического
процесса переработки данных, при решении
различных задач, обработки различных
видов данных; -
системные
– удобство работы, наглядность и форма
представления результатов, требования
к квалификации и количеству операторов,
конфигурация компьютера, необходимое
программное обеспечение.
С
целью унификации и стандартизации
методов контроля данных для международного
обмена данными разрабатываются
Руководства по алгоритмам и процедурам
контроля данных, представляемых в
систему международного обмена данными.
В них рассматриваются алгоритмы и
процедуры «базового» или общего
контроля, которые в максимальной степени
беспристрастны и опираются на общеизвестные
физические законы и не допускающие
множества толкований логических
категорий.
Как
бы тщательно ни был составлен инструментарий
наблюдения, проведен инструктаж
исполнителей, материалы измерения
всегда нуждаются в контроле. Прежде
всего, проверяется полнота охвата
наблюдениями. С этой целью производится
сверка данных по спискам, пересчитываются
заполненные документы. Одновременно
на этой стадии проверяется полнота
заполнения форм отчетности, анкет и
т.д.
Содержанием
контроля данных является выполнение
комплекса проверок, позволяющих убедиться
в общей пригодности данных для решения
различных научных и производственных
задач.
Проблема
контроля данных очень сложная и требует
отдельного рассмотрения в зависимости
от специфики конкретного вида данных.
Контроль данных на технических носителях
состоит из трех этапов:
-
контроль
сопроводительных документов и форматов
записи (тестирование носителя данных,
получение контрольных распечаток); -
проверка
соответствия полноты и содержания
массивов программе наблюдений; -
контроль
значений физических параметров и
характеристик пространственно-временного
размещения наблюдений (проверка
упорядоченности данных, полноты
наблюдений, реальности данных, соблюдения
физических законов, проверка на
статистические критерии, закономерностей
изменения данных в пространстве и во
времени).
Подготовка
данных к обмену представляет собой
передачу сведений о контроле и калибровке
измерительных приборов, о массиве
данных, об оценке его качества. Выполнение
всех этих этапов контроля позволяет
повысить качество обмениваемых комплектов
данных.
Данные,
представляемые в обмен, должны быть
снабжены сопроводительной документацией,
содержащей описание структуры данных,
сведения об источниках данных. Ключевые
характеристики в БД должны содержать
сведения о пространственно – временных
координатах каждого измерения, типе
платформ, размерностях параметров,
используемых методах измерений, типах
приборов, а сами результаты измерений
и определений должны быть исправлены
инструментальными поправками. Значения
параметров должны быть приведены с
точностью, соответствующей паспортным
характеристикам измерительных систем
и возможностям аналитических методов
определений.
Каждому
измеренному, определенному или
вычисленному параметру после контроля
должен быть присвоен признак качества,
не менее трех градаций – значение
достоверно, сомнительно и забраковано.
Для данных о природной среде используются
следующие градации:
0
– величина не вызывают сомнений;
1
– величина восстановлена;
2
– величина сомнительна;
3
– величина забракована;
4
— наблюдения не проводились;
5
– явление отсутствует;
6
– величина сомнительна по применяемым
алгоритмам контроля;
7-8
–резерв;
9
– контроль качества не проводился.
На
основе анализа статистики этих признаков
качества делается вывод о качестве
всего массива данных. Для обозначения
качества БД рекомендуется использовать
следующие коды:
0 все данные
не вызывают сомнений;
-
небольшая
часть данных сомнительна (0-10%), но может
быть использована; -
существенная
часть данных сомнительна (10-50%), но может
быть использована; -
более
половины данных сомнительны (50-80%), но
могут быть использованы; -
почти
все данные сомнительны (80-100%), но могут
быть использованы; -
небольшая
часть данных сомнительна (0-10%), но не
может быть использована; -
существенная
часть данных сомнительна (10-50%), но не
может быть использована; -
более
половины данных сомнительны (50-80%), но
не могут быть использованы; -
резерв;
-
информация
о качестве массива данных отсутствует.
Организация
работ по повышению качества данных
Соседние файлы в папке Lektsii
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Способ повышения достоверности информации
При передаче информации простым безызбыточным кодом достоверность приема в основном определяется типом канала и видом помех в нем. В большинстве случаев получающаяся достоверность недостаточна. Ее необходимо повысить, чтобы вероятность ошибочного приема сообщения потребителем была намного меньше, чем вероятность ошибок в сообщении без принятия специальных мер.
Один из путей повышения достоверности — применение избыточного кода. Все известные избыточные коды можно использовать в следующих режимах?
а) исправление ошибок;
б) обнаружение ошибок;
в) исправление и обнаружение ошибок.
Режим исправления ошибок обычно применяется в том случае, когда в канале связи имеют место независимые ошибки или короткие пачки ошибок [22, 127]. Исправление же пачек ошибок, веса которых соизмеримы с длиной кодовой комбинации, приводит к неоправданным затратам оборудования на кодирующие и декодирующие устройства.
Коды, предназначенные для исправления ошибок, даже при относительно высокой избыточности могут обеспечить исправление ошибок, вес которых численно не превышает 20—25% длины, кодовой комбинации, тогда как даже при биномиальном распределении наиболее часты ошибки с весом, близким к 50% длины кодовой комбинации. Поэтому при необходимости непосредственного исправления целесообразны лишь методы, которые позволяют отделить проверочные импульсы от информационных на время, превышающее, вероятную длину пачки ошибок.
Повышение достоверности с помощью кодов, предназначенных для обнаружения ошибок, достигается введением обратного канала связи. В этом случае принятая по прямому каналу кодовая комбинация анализируется, чтобы определить, принадлежит ли она к числу разрешенных комбинаций. Разрешенная комбинация поступает потребителю после отбрасывания проверочных разрядов. В случае обнаружения ошибки по обратному каналу посылается сигнал запроса, по которому передающее устройство повторяет передачу информации. В силу этого передающее устройство должно хранить информацию об отправленных сигналах в течение времени, достаточного для анализа комбинации приемным устройством и получения возможного запроса об ошибках.
Системы с обратным каналом называют системами с обратной связью. По своей природе они адаптивны,
так как число повторений зависит от состояния канала связи и автоматически поддерживается на уровне, необходимом для надежного прохождения сообщений.
Большинство специалистов [15, 18, 19, 22, 23, 27, 32, 35, 40, 44, 55, 59, 60] считают, что наиболее рациональны такие системы передачи информации, в которых избыточные коды используются для обнаружения ошибок. Они обладают следующими преимуществами:
а) обнаруживающая способность кода при одной и той же избыточности всегда выше исправляющей [5, 6, 16, 18, 27, 41, 74];
б) число логических операций, которое должно выполняться декодером для обнаружения ошибок, значительно меньше числа необходимых операций для их исправления.
Единственный недостаток систем с обратной связью — уменьшение скорости передачи информации.
Однако это заметно только при плохих состояниях канала связи. Если состояние канала связи характеризуется таким распределением групп ошибок, когда вероятность появления коротких и весьма длинных ошибок существенно больше вероятности появления других групп, эффективно использование режима с исправлением ошибок малой кратности и обнаружением остальных ошибок [72, 73].
Таким образом, выбор метода повышения достоверности передачи информации зависит от многих факторов: требуемой достоверности приема, допустимой скорости передачи, вида ошибок в канале связи и т. д.
В работе [84] найден критерий эффективности метода повышения достоверности:

В этом выражении  — выигрыш в защите от
— выигрыш в защите от
ошибок, где  вероятность ошибки в сообщении без избыточности;
вероятность ошибки в сообщении без избыточности;  вероятность ошибки в сообщении с избыточностью;
вероятность ошибки в сообщении с избыточностью;  избыточность, где
избыточность, где  информационная избыточность;
информационная избыточность;  схемная избыточность,
схемная избыточность,  суммарная скорость передачи информации;
суммарная скорость передачи информации;  полезная скорость ввода информации (без избыточности) потребителю;
полезная скорость ввода информации (без избыточности) потребителю;  весовой коэффициент, приводящий информационную и схемную избыточности к эквивалентным технико-экономическим показателям;
весовой коэффициент, приводящий информационную и схемную избыточности к эквивалентным технико-экономическим показателям;  объем аппаратуры передачи информации и аппаратуры повышения достоверности в эквивалентных единицах (число элементов со своими весовыми коэффициентами);
объем аппаратуры передачи информации и аппаратуры повышения достоверности в эквивалентных единицах (число элементов со своими весовыми коэффициентами);  объем аппаратуры передачи информации без применения мер повышения достоверности.
объем аппаратуры передачи информации без применения мер повышения достоверности.
Информационная избыточность  выражается по-разному для различных методов повышения достоверности. Для кодов, исправляющих ошибки,
выражается по-разному для различных методов повышения достоверности. Для кодов, исправляющих ошибки,

Для систем с обнаружением ошибки и последующим переспросом

Второй множитель (5.25) означает, что из любых  сообщений
сообщений  передаются с ошибками, а значит, повторяются, т. е. избыточность увеличивается.
передаются с ошибками, а значит, повторяются, т. е. избыточность увеличивается.
Сравним использование кода Хэмминга (7,4) с исправлением одиночных ошибок и того же кода для обнаружения двойных ошибок с переспросом, если вероятность сбоя одиночного символа 
При биноминальном характере распределения ошибок

а) для случая исправления

б) для случая обнаружения

Схемная избыточность зависит от объема устройств. Примем 184]  для случая исправления ошибок,
для случая исправления ошибок,  для случая их обнаружения. Тогда
для случая их обнаружения. Тогда

Вероятность ошибки в сообщении без избыточности

Вероятность ошибки в сообщении с использованием кода  исправляющего одну ошибку,
исправляющего одну ошибку,

 Вероятность ошибки при использовании этого же кода для обнаружения двойных ошибок из (5.11) с учетом (3.35)
Вероятность ошибки при использовании этого же кода для обнаружения двойных ошибок из (5.11) с учетом (3.35)

Находим выигрыш в защите от ошибок

Критерий эффективности 
Таким образом, в данном случае использование  -кода Хэмминга в режиме обнаружения ошибок гораздо целесообразнее, чем в режиме исправления.
-кода Хэмминга в режиме обнаружения ошибок гораздо целесообразнее, чем в режиме исправления.
Источник
Принципы повышения достоверности информации
Сложные АСОИУ содержат значительное количество источников и получателей информации, связанных между собой каналами ее передачи и обработки.
Надежность таких систем во многом определяется достоверностью сбора, обработки, передачи, хранения и представления информации.
Методы повышения достоверности информации как при передаче, так и при переработке основаны на введении информационного, алгоритмического или аппаратного резерва: применении кодов с обнаружением и исправлением искажений, методов оптимального резервирования ТС, методов функционального контроля, методов оценки достоверности входной информации.
В настоящее время в теории передачи информации, и в теории надежности получены важные результаты, позволяющие проектировать системы с высокими показателями, помехоустойчивости. Российские ученые (В.А.Котельников, В.И.Сидоров, Б.С.Сотсков, Н.А.Железнов, Л.М.Финк, Г.А.Шастова, Б.С.Флейшман, И.А.Ушаков, Л.Ф.Бородин, И.Б.Герцбах, Ю.П.Солалович, С.И.Самойленко, М.С.Пинстер, Н.Д.Путинцев и др.) внесли значительный вклад в теорию повышения достоверности передачи и переработки информации.
В работах по теории информации рассматриваются задачи передачи и приема недостоверной информации абсолютно надежной системой, а в работах по надежности рассматриваются отказы и сбои в ТС безотносительно к информационным процессам в ней. В практике АСОИУ недостоверная информация передается и обрабатывается в не надежных системах.
Решение этой проблемы путем использования комплексного подхода к помехоустойчивости и надежности систем было впервые предложено профессором Н.А.Железновым в 1966-68 годах.
Комплексное исследование проблемы повышения достоверности обработки информации в сложных системах возможно, при использовании следующих принципов:
1.Системности — для повышения достоверности должны быть учтены все основные причины искажений информации, выдаваемой системой, независимо от их причин возникновения в процессе переработки информации. Принцип системности требует рассмотрения и сравнения между собой способов и повышения достоверности информации.
2. Экономичности — способы повышения достоверности, применяемые в системе, должны сравниваться и не только по вкладу в повышение результирующего показателя достоверности, но и по затратам, необходимым для реализации этих способов;
3. Равнопрочности — затраты на повышение достоверности в системе должны распределяться так, чтобы максимально улучшать показатели достоверности выходной информации. Принцип равнопрочности не допускает завышения одних характеристик системы, влияющих на достоверность по отношению к другим.
Причинами снижения достоверности выходной информации могут быть:
— воздействие помех при передаче, хранении и переработке информации;
— отказы и сбои в работе ТС;
— структурные и алгоритмические ошибки;
— использование недостоверных входных данных;
— ошибки человека как звена системы.
Одним из основных условий функционирования системы является достоверность переработки информации. Вот почему к числу первоочередных проблем, подлежащих исследованию при оценке функционирования систем, относится проблема исследования достоверности обрабатываемой информации.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Источник
Способы повышения достоверности
Требование достоверности данных является существенным для любой системы управления, но для автоматизированной системы оно становится просто жизненно необходимым. Это объясняется большим объемом обрабатываемых данных и широким использованием технических средств. Если в системах, с ручной обработкой данных руководитель любого подразделения в принципе имеет возможность проверить работу каждого сотрудника, то при использовании ЭВМ подобная проверка практически исключена. Это обстоятельство порождает много проблем самого различного свойства, важнейшей среди которых является необходимость повышения достоверности данных.
Все методы контроля и повышения достоверности при автоматизированной обработке данных можно разделить на три группы:
— системные или организационные;
Методы первой группы применимы как при ручной, так и при автоматизированной обработке данных, остальные относятся к автоматизированной обработке.
К системным методам относится выбор и применение наиболее рациональных методов обработки данных и контроля их достоверности, а также оптимизация структуры обработки. Это означает, что должен быть определен оптимальный вариант распределения пунктов обработки и контроля данных, четко установлены их функции и связь между ними. Особое внимание должно уделяться точкам стыка между подразделениями или организациями, где возрастает возможность утери части информации.
Рациональные методы обработки данных включают в себя использование специальных приемов, ускоряющих обработку и уменьшающих возможность ошибок, в том числе заранее подготовленных расчетных таблиц с готовыми итогами, графиков и номограмм. При массовой обработке однотипных документов удобны шаблоны — маски, выделяющие из документа, места с данными, подлежащими обработке, и закрывающие все остальное. Иногда такой шаблон наносится непосредственно на документ при типографской подготовке соответствующего бланка. Полезно использование цвета — печать разнотипных документов на бумаге разного цвета, нанесение различных цветных полос и т. д.
К системно-организационным относят также мероприятия, направленные на поддержание характеристик используемого оборудования в заданных пределах и повышение культуры обработки данных. Сюда входи г определение сроков проверок и профилактических ремонтов оборудования, быстрое обнаружение неисправностей и ввод оборудования в строй, своевременная замена физически и морально устаревшего оборудования, создание условий работы персонала, направленных на повышение качества обработки, снижение уровня шума, оптимальное освещение рабочего места, создание спокойной обстановки для работы, и т. п.
При разработке системы рассматривают такие вопросы, как сроки и методы хранения исходных данных, возможность восстановления утерянных или испорченных в процессе обработки данных, оптимальные размеры единовременно обрабатываемой пачки данных, необходимое число копий, процедуры доступа к документам и промежуточным данным и т. д. Должен быть предусмотрен постоянный контроль качества работы операторов, особенно при первичной обработке данных.
Программные методы повышения достоверности обработки информации состоят в том, что при составлении процедур обработки данных на ЭВМ предусматривают дополнительные операции, имеющие математическую или логическую связь с основным алгоритмом расчета. Сравнение результатов этих дополнительных операций с результатами основной обработки данных дает возможность установить с определенной вероятностью наличие или отсутствие ошибок. На основании этого сравнения появляется, кроме того, возможность исправления обнаруженной ошибки.
Некоторые из программных методов повышения достоверности применимы также при ручной обработке данных.
Широкое распространение получили счетные методы контроля.
Контроль методом двойного или обратного счета состоит в повторном решении задачи одновременно или последовательно во времени и сравнении полученных результатов. Если они совладают, задача считается решенной правильно. При обратном счете решают задачу «наоборот», получая исходные данные из результатов расчета и сравнивая их с теми, которые были использованы при первоначальном решении задачи.
Контроль по методу «усеченного алгоритма» заключается в дополнительном решении задачи упрощенным, приближенным методом в сравнении полученных результатов. Полученная разница должна находиться в пределах, заранее обусловленных точностью приближенного решения.
Большое распространение получил метод «контрольных сумм», особенно для проверки правильности ввода данных в ЭВМ. Для этого заранее подсчитывают любым способом сумму чисел определенной группы данных. Полученное значение суммы вводят в ЭВМ вместе с этой группой данных. Затем ЭВМ повторяет суммирование, сопоставляет свой результат с введенным. При этом смысловое значение суммируемых данных не имеет никакого значения, суммирование осуществляется совершенно формально, например, по столбцу или по строке, независимо от их содержания.
Балансовые методы контроля заключаются в сопоставлении результатов решения нескольких этапов задачи или нескольких задач, например, сопоставлении суммарных доходов и расходов, если заранее известно, что эти суммы должны совпадать.
Существует большая группа методов контроля, использующих избыточность информации. К ним относятся методы, основанные на сопоставлении данных, полученных из различных источников или вновь полученных, с уже хранящимися в памяти. Распространен также метод избыточных или контрольных цифр либо разрядов. С помощью специальных не слишком сложных расчетов для каждого числа или группы чисел подсчитывается контрольная цифра, которая вводится в ЭВМ вместе с этим числом или группой чисел. ЭВМ выполняет аналогичный расчет и сравнивает полученную цифру с контрольной.
Логические методы контроля основаны на некоторых характеристиках решаемых задач. Например, если решается задача для определенного класса объектов — распределение заказов на некоторый вид продукции, обработка статистических данных по отдельной республике или краю и т. п., то каждый вновь рассматриваемый объект проверяется на принадлежность к атому классу. К логическим методам относится также экспертная оценка получаемых данных, когда специалист дает заключение о реальной возможности такого решения. Несмотря на то, что метод является очень приближенным, он позволяет отбросить явно негодные результаты, появляющиеся при случайных грубых искажениях нормального хода расчета.
Значительная часть ошибок, вызванных нарушениями работы оборудования, обнаруживается аппаратными методами. Эти методы обладают большими возможностями, чем программные, выполняя почти все то же функции и некоторые дополнительные, Аппаратными методами ошибки обнаруживаются ближе к месту их возникновения, чем программными, поэтому аппаратное обнаружение ошибок используется для представления обслуживающему персоналу ЭВМ более точной информации об искажениях, вызванных неисправностью.
Программными методами целесообразнее осуществить защиту программистов и операторов ЭВМ от ошибок, которые труднее обнаружить аппаратными методами.
В отличие от программных методов, когда контроль ошибок осуществляется периодически, аппаратные методы обеспечивают непрерывный контроль и указывают ошибку в момент ее появления. При использовании аппаратного метода возрастают затраты на разработку и реализацию в ЭВМ средств обнаружения ошибок, однако программные методы также требуют затрат на подготовку или отладку соответствующих программ или их частей и периодического их выполнения.
Чтобы достичь заданной или максимально возможной достоверности, обычно используется не один какой-либо метод, а комбинация нескольких. Выбор наилучшей комбинации методов зависит не только от требований достоверности, но и от ограничений на затраты времени, труда и денег. Однако никакие соображения экономии средств не могут служить основанием для отказа от контроля достоверности. Без такого контроля система может оказаться полностью неработоспособной. В то же время следует помнить, что обеспечение такой вероятности ошибок, чтобы один ошибочный знак приходился на 1 млн. или более правильных, увеличивает суммарные затраты па разработку системы на 50÷100%
Источник
В стандартном процессе обработки данных имеется ряд источников ошибок:
-
ошибки
в первичных данных (ошибки измерений,
сбои информационно – измерительных
систем) — намеренный ввод неправильных
сведений в оперативном режиме, сокращение
текста при вводе данных операторами,
ошибки в данных, полученных путем
обмена, ввод ошибочных данных клиентами,
использование различных форматов
данных в разных системах; -
ошибки,
возникающие в процессе эксплуатации
технологий обработки данных; -
ошибки,
связанные со сбоями вычислительной
техники, программных средств.
Ошибки
вычислительной техники на несколько
порядков менее вероятны, чем ошибки при
занесении данных на носитель. Ошибки в
первичных данных возникают из-за
несовершенства измерительных систем,
средств регистрации и передачи информации.
В результате могут появиться значения
параметров, выходящие за физически
допустимые пределы, ошибки в кодировании
значений ключевых характеристик,
появление двух одинаковых экземпляров
свойств объекта и др.
Можно
выделить четыре категории ошибок
(http://www.dwinfocenter.org/errors.html):
неполные данные, неправильные данные,
непонятные данные, непоследовательные
данные.
Неполные
данные –
т.е. в них имеются отсутствующие записи.
Чаще всего возникает по причине сбоев
в системах сбора данных. Сюда же относятся
отсутствующие
поля – задача
сбора данных решалась частным образом
– хотелось как можно быстрее создать
БД, при этом не думали о будущем. Записи
или поля которые при проектировании не
предусматривались, то есть это был
небрежный проект, без предварительного
исследования источников данных и
информационных потребностей пользователей.
Неправильные
данные — то
есть данные, имеющие ошибки, связаны с:
-
неправильным
применением кодов
— это обычно происходит, когда используются
старые протоколы обработки данных,
исторические данные; -
неправильными
расчетами, агрегацией — эта
ситуация возникает при загрузке уже
ранее вычисленных данных (необходимо
иметь исходные данные для проверки
результатов расчетов); -
ошибочным
вводом информации в источнике данных
– это связано с плохими формами ввода
(последовательность записи года, месяца,
дня в дате, плохое качество бумажного
источника, др.), здесь необходимы более
жесткие системы контроля ввода данных.
Непонятные
данные связаны с:
-
неправильным
парсингом кодов
– это плохо составленный алгоритм
конвертирования кодов или плохое
соответствие двух классификаторов; -
хранением
значений атрибутов в разных полях
— это ситуация, где источник передает
данные по различным каналам связи, на
различных носителях и форматах; -
дупликацией
данных —
возникает в пределах одной системы, а
особенно при объединении разных
источников информации; -
непродуманным
использованием схем форматирования,
чтобы уменьшить использование памяти,
например, можно хранить число в виде 4
байт, а можно сохранить в виде двух
байт, но при этом это число не может
превышать значение 32000,
другой пример, хранение цифровых данных
сначала в символьном виде, а затем в
виде числа – при преобразовании могут
исчезнуть значащие нули; -
применением
неизвестных кодов
– при анализе БД, можно найти неизвестные
значения кодов – это или ошибка при
вводе данных или ошибка в алгоритме
конвертирования – включен не тот код; -
ошибками
несовместимости
– эта категория охватывает наиболее
широкий диапазон проблем, это связано
с единицами измерения, ошибками в
представлении даты и времени,
непоследовательном использовании
различных кодов, др.; -
различными
кодами с одним тем же значением атрибута
– используются
два разных классификатора для одного
объекта; -
непоследовательными
именами и адресами
— это случай различных кодов с одним и
тем же значением, например, при изменении
названия организации можно вести новый
код, а можно создать таблицу «Жизненный
цикл изменения кодов».
Непоследовательные
данные
связаны с:
-
непоследовательными
правилами
получения
вычисленных
характеристик
– это когда значения поля вычисляются
неодинаково по разным формулам, в
зависимости от района, метода; -
непоследовательной
агрегацией данных
— это случай использования различных
правил при вычислении одних и тех же
статистических характеристик в
различных ситуациях, например, в области
исследования климата принят одинаковый
период обобщения данных (30 лет, каждые
5 лет производится пересчет); -
использованием
неодинаковых атомарных единиц
представления данных
– это бывает при использовании разных
моделей данных; -
разными
единицами оценки объемов данных в
логических единицах
— это случай разного использования
единиц хранения атомарной информации; -
непоследовательным
использованием атрибута
– например, можно в поле адрес хранить
всю информацию о клиенте, а можно
отдельно улицу, дом, почтовый индекс,
город, регион, страна, второй случай
более правильный; -
непоследовательной
датой — это
случай непоследовательного использования
атрибута, когда сливаются данные из
двух систем, в которых различная политика
использования дат (дата ввода измерения,
дата ввода в систему, дата передачи); -
непоследовательным
использованием пространства памяти,
пустых значений и так далее,
например, чтобы отмечать отсутствующие
измерения, забракованные или вычисленные
значения, необходимо иметь признак
качества для каждого такого значения
атрибута; -
отсутствием
ссылочной целостности
— может привести к ошибкам в значениях
одних и тех же атрибутов в разных
таблицах; -
не
синхронизированной агрегацией
— некоторая суммарная информация может
быть получена независимо в различных
таблицах, например, среднемесячное
значение можно получить путем агрегации
срочных значений, а можно на основе
среднесуточных значений; -
сложностью
ведения хранилища данных — увеличивается
геометрически со временем –
уходят
специалисты, которые знали данные,
алгоритмы и проблемы БД.
БД
представляют сложные человеко-машинные
системы, реальная достоверность сбора
первичной информации в которых
определяется как надежность работы
технических систем, так и ошибками,
вносимыми операторами. Основными
причинами
искажений
в процессе создания БД являются:
-
отсутствие
или неточность инструкции и стандартов
работы; -
несовершенство
или отсутствие макетов таблиц –
документов, нечеткость заполнения
первичных документов, смятие или
загрязненность первичных (машинных)
документов; -
сложность
применяемых классификаторов и форм
занесения данных, несоответствие макета
первичного документа форме ввода данных
на компьютере; -
недостаточная
квалификация оператора, недобросовестное
отношение к работе – небрежность,
невнимательность, халатность; -
неточность
в документации; -
плохая
организация хранения и учета носителей
информации; -
преднамеренное
искажение информации в корыстных целях; -
недостаточная
сознательность, безразличие и
безответственность в работе; -
организационные
недостатки в работе оператора –
отсутствие постоянного закрепленного
рабочего места, совместительство,
нарушения или отсутствие графика
работы, отвлечение на другие работы; -
обезличка
в работе и отсутствие контроля; -
отсутствие
морального и материального стимулирования
хорошей работы; -
низкая
трудовая дисциплина; -
неритмичность
в работе (много потерь времени на этап
врабатываемости); -
завышенный
темп работы, усталость, возбужденное
или угнетенное состояние оператора; -
недостатки
в организации рабочего места (плохое
освещение, шум), неудобная конструкция
рабочего места, плохая регулировка и
настройка (где лежит документ и
клавиатура); -
недостаточная
автоматизация ввода данных; -
сбои
измерительной системы (неправильная
работа датчика – погрешность измерения,
приближенная запись) и ЭВМ при вводе
данных (залипание клавиш; некачественность,
физический износ и старение технического
носителя; нарушение работоспособности
из-за климатических и механических
воздействий, флуктуации напряжения
питающей сети); -
сбои
аппаратуры при обработке данных
(ошибочное вычисление значения); -
искажения
в процессе передачи данных по каналам
связи (наводки и помехи атмосферного
и производственного характера, шум и
частотные искажения в каналах связи); -
ошибки в алгоритмах
и программах; -
форматные
ошибки (изменение формата атрибута,
количества байт, добавление или пропуск
символа, появление запрещенных символов
в атрибуте, сдвиг атрибутов, нарушающих
шаблон сообщения, пропуск или появление
дополнительных служебных символов,
изменение количества реквизитов).
Средняя
вероятность ошибки при вводе информации
с клавиатуры находится в диапазоне
(0.5-1.5) 10 -3
ошибок / символ.
Методы
контроля данных
Процесс
управления качеством данных можно
разделить на следующие этапы:
– определение
качества исходных данных;
– определение
правил обеспечения качества этих данных;
– разработка
процессов очистки данных;
– внедрение этих
процессов;
– контроль
данных.
Для
этапа исследования можно использовать
средства профилирования – они осуществляют
быстрый анализ данных во всех исходных
системах, выдавая заключение и предлагая
инструкции по построению обработки
данных. Определение и построение правил
обеспечения качества данных крайне
важно для стандартизации, сравнения и
консолидации данных.
Проверка
качества данных становится отдельным
этапом работ при загрузке БД. Обеспечение
качества данных – нетривиальная задача.
Основными методами контроля являются:
-
самоконтроль;
-
дублирование
операций (или части операций) при вводе
информации (двойной ввод); -
применение
помехоустойчивых кодов, базирующихся
на использовании признаков делимости
чисел (четность, нечетность) запрещении
использования некоторых символов,
введение избыточной информации в
передаваемые данные; -
осуществление
программно-логического контроля
(совместимость, непротиворечивость,
нахождение в некотором заданном
интервале значений, дополнение атрибутов
до заданного формата поля, контроль
существования значения атрибута,
сравнение из различных источников).
Для
сведения к минимуму потерь от случайных
искажений требуется создавать или
использовать уже готовые программы:
-
ведения
системного журнала СУБД, подробно
фиксирующего каждую операцию над БД
(описание транзакции, адреса компьютера,
пользователя, время, тип и адрес изменения
данных, значение данных до и после
выполнения транзакции); -
контроля
достоверности, использующие соответствующие
методы контроля данных; -
отката,
создания контрольных точек и повторного
исполнения транзакции, вызвавшей
искажение БД.
Учитывая
характер наиболее массовых ошибок,
целесообразно предусматривать три
категории алгоритмов качества данных
на каждом этапе преобразования информации:
-
контроль
соблюдения форматов записи данных на
носитель (синтаксический контроль); -
контроль
числовых значений параметров и ключевых
характеристик измерений при вводе
данных (семантический контроль); -
контроль
выходной информации из БД (прагматический
контроль).
Синтаксический
– это по существу контроль достоверности
данных, не затрагивающий содержательного
смыслового аспекта информации. Предметом
этого контроля являются контроль
форматов представления данных, шаблонов
и масок ввода данных, наличия атрибутов
(их номенклатуры), порядка следования,
наличие служебных признаков в структуре
сообщения, упорядоченности данных,
появления запрещенных символов,
комбинаций, полноты поступления первичной
информации и сопровождающих ее метаданных.
Семантический
контроль оценивает смысловое содержание
информации, его логичность,
непротиворечивость, диапазон возможных
значений параметров (предельные значения,
область значений), динамику их изменения,
возможных отклонений. Примером
семантического контроля могут служить
переписные листы населения, где двухлетний
мальчик показан женатым, а девятилетний
ребенок — грамотным.
Прагматический
контроль определяет потребительскую
ценность (полезность) информации для
пользователя, своевременность и
актуальность данных, их полноту и
доступность. Реализуется экспертной и
социологической оценкой данных.
При создании БД
очень часто используют средства очистки.
К сожалению, такой подход, позволяет
удалить только ошибочные данные. Средства
очистки данных выполняют базовые функции
контроля данных:
-
проверка
значений атрибутов БД на пределы
допустимого диапазона; -
проверка
орфографии; -
проверка
стандартных сокращений; -
поиск
неверных кодов.
По
назначению
контроль различается на профилактический,
рабочий и генезисный. Профилактический
– тестовый контроль надо проводить как
можно чаще, включать во все этапы
переработки. Рабочий контроль —
диагностический
(проверка работоспособности системы)
устанавливает места и причины
неисправности. Генезисный
контроль проводится для выяснения
технического состояния системы в прошлые
моменты времени с целью определения
причин сбоев и отказов системы, имевших
место в прошлом, сбор статистических
данных об ошибках, их характере – типах
ошибок, величине, последствиях этих
ошибок для пользователя.
По
способу реализации
контроль может быть организационный,
программный, аппаратный и комбинированный.
Организационный
контроль представляет собой комплекс
мероприятий, предназначенный для
выявления ошибок на всех этапах
переработки данных с участием человека.
Методами организационного контроля
являются разработка нормативных
документов, обучение, выборочная
проверка, контроль комплектности
документов, сроков и условий передачи
документов, условий и длительности
хранения технических носителей данных,
кондиционности бланков (носителей) и
качества их заполнения и визуальный
осмотр. Необходимо обеспечить правильный
подбор и обучение персонала, на который
будут возложены проведение наблюдения,
систематический контроль за ходом
наблюдений, широкая разъяснительная
работа. Следует предусмотреть
соответствующие меры во избежание
сознательного искажения фактов, приписок
и т.д., что является не только нарушением
государственной дисциплины, но и прямым
преступлением, наносящим вред интересам
дела.
Программный
контроль основан на программировании
логических методов проверки достоверности
данных. Примерами логического контроля
являются:
-
наличие
связей между отдельными измеряемыми
показателями, например, влажность,
измеренная и вычисленная по значениям
сухого и смоченного термометра; -
сравнение
с измеренными параметрами на соседнем
приборе, станции; -
экстраполяция
значений во времени, статистический
прогноз; -
интерполяция
данных между двумя измеренными значениями
во времени или пространстве; -
счетный
контроль заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Аппаратный
контроль – контроль значений параметров
на этапе измерений, включается в платы,
служащие для преобразования данных из
физических значений в натуральные
(сопротивление в температуру,
электропроводность в соленость воды,
и т.д.).
По
степени выявления и корректировки
ошибок контроль делится на:
-
обнаруживающий,
фиксирующий только сам факт наличия
или отсутствия ошибки; -
локализующий,
позволяющий определить и место ошибки,
например, искаженный символ, атрибут,
др.; -
исправляющий,
выполняющий функции обнаружения,
локализации и исправления ошибки.
Примерами
исправляющих методов являются:
-
анализ
текста свободного формата
для выявления в данных имен и адресов
позволяет идентифицировать компонент
имени, должности, организации и адреса
даже в случае непоследовательно
введенных данных (стандартизация слов,
связанных с описанием организации,
позволяет программе полностью проверить
данные об организации, включая сокращения,
и стандартизировать описание организации
в едином согласованном формате); -
стандартизация
представления значений некоторых полей
— данные
имен и адресов могут вводиться в
различных форматах, многие из которых
вполне грамматически корректны.
Например, «Улица», «Ул.» и «Ул»
обозначают одно и то же очевидное
понятие в составе адреса, существуют
и другие стандарты для этих и других
подобных случаев, программы стандартизации
трансформируют такие поля в согласованный
набор обозначений; -
проверка
допустимости — средства
распознавания допустимых международных
и национальных адресов, проверяют
допустимость адресных данных.
Оформление
результатов контроля данных
Данные
наблюдения считаются принятыми, если
они прошли контроль и, если потребовалось,
в них внесены исправления. Основными
показателями
качества контроля данных
являются:
-
экономические
– материальные, трудовые и временные
затраты на контроль; -
технико–эксплуатационные
– алгоритмическая сложность контроля,
вид и величина получаемой избыточности,
точность и надежность контроля,
универсальность — возможность использовать
на различных этапах технологического
процесса переработки данных, при решении
различных задач, обработки различных
видов данных; -
системные
– удобство работы, наглядность и форма
представления результатов, требования
к квалификации и количеству операторов,
конфигурация компьютера, необходимое
программное обеспечение.
С
целью унификации и стандартизации
методов контроля данных для международного
обмена данными разрабатываются
Руководства по алгоритмам и процедурам
контроля данных, представляемых в
систему международного обмена данными.
В них рассматриваются алгоритмы и
процедуры «базового» или общего
контроля, которые в максимальной степени
беспристрастны и опираются на общеизвестные
физические законы и не допускающие
множества толкований логических
категорий.
Как
бы тщательно ни был составлен инструментарий
наблюдения, проведен инструктаж
исполнителей, материалы измерения
всегда нуждаются в контроле. Прежде
всего, проверяется полнота охвата
наблюдениями. С этой целью производится
сверка данных по спискам, пересчитываются
заполненные документы. Одновременно
на этой стадии проверяется полнота
заполнения форм отчетности, анкет и
т.д.
Содержанием
контроля данных является выполнение
комплекса проверок, позволяющих убедиться
в общей пригодности данных для решения
различных научных и производственных
задач.
Проблема
контроля данных очень сложная и требует
отдельного рассмотрения в зависимости
от специфики конкретного вида данных.
Контроль данных на технических носителях
состоит из трех этапов:
-
контроль
сопроводительных документов и форматов
записи (тестирование носителя данных,
получение контрольных распечаток); -
проверка
соответствия полноты и содержания
массивов программе наблюдений; -
контроль
значений физических параметров и
характеристик пространственно-временного
размещения наблюдений (проверка
упорядоченности данных, полноты
наблюдений, реальности данных, соблюдения
физических законов, проверка на
статистические критерии, закономерностей
изменения данных в пространстве и во
времени).
Подготовка
данных к обмену представляет собой
передачу сведений о контроле и калибровке
измерительных приборов, о массиве
данных, об оценке его качества. Выполнение
всех этих этапов контроля позволяет
повысить качество обмениваемых комплектов
данных.
Данные,
представляемые в обмен, должны быть
снабжены сопроводительной документацией,
содержащей описание структуры данных,
сведения об источниках данных. Ключевые
характеристики в БД должны содержать
сведения о пространственно – временных
координатах каждого измерения, типе
платформ, размерностях параметров,
используемых методах измерений, типах
приборов, а сами результаты измерений
и определений должны быть исправлены
инструментальными поправками. Значения
параметров должны быть приведены с
точностью, соответствующей паспортным
характеристикам измерительных систем
и возможностям аналитических методов
определений.
Каждому
измеренному, определенному или
вычисленному параметру после контроля
должен быть присвоен признак качества,
не менее трех градаций – значение
достоверно, сомнительно и забраковано.
Для данных о природной среде используются
следующие градации:
0
– величина не вызывают сомнений;
1
– величина восстановлена;
2
– величина сомнительна;
3
– величина забракована;
4
— наблюдения не проводились;
5
– явление отсутствует;
6
– величина сомнительна по применяемым
алгоритмам контроля;
7-8
–резерв;
9
– контроль качества не проводился.
На
основе анализа статистики этих признаков
качества делается вывод о качестве
всего массива данных. Для обозначения
качества БД рекомендуется использовать
следующие коды:
0 все данные
не вызывают сомнений;
-
небольшая
часть данных сомнительна (0-10%), но может
быть использована; -
существенная
часть данных сомнительна (10-50%), но может
быть использована; -
более
половины данных сомнительны (50-80%), но
могут быть использованы; -
почти
все данные сомнительны (80-100%), но могут
быть использованы; -
небольшая
часть данных сомнительна (0-10%), но не
может быть использована; -
существенная
часть данных сомнительна (10-50%), но не
может быть использована; -
более
половины данных сомнительны (50-80%), но
не могут быть использованы; -
резерв;
-
информация
о качестве массива данных отсутствует.
Организация
работ по повышению качества данных
Соседние файлы в папке Lektsii
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Подборка по базе: численные методы задачи.docx, Современные носители информации.docx, Презентация к лекции — Методы физического воспитания.pptx, АНАЛИЗ ОРГАНИЗАЦИИ И МЕТОДЫ СОВЕРШЕНСТВОВАНИЯ МАРКЕТИНГОВОЙ ДЕЯ, П.З. Методы принятия управленческих решений .docx, 3.5 Активные методы обучения детей с ОВЗ.pptx, Методы получения первичной информации.docx, Электронные измерительные приборы и датчики информации. Специали, 0. Методика по практике ПМ.02 Хранение, передача и публикация ци, Математические методы.pdf
Тема: Вероятностные методы в обработке информации
Содержание
Введение 3
1.Обработка данных как информационный процесс 4
2.Вероятностные модели информационных открытых систем 7
Заключение 15
Список использованной литературы 16
Введение
Вероятностные методы служат одним из наиболее эффективных инструментов анализа и разработки современных информационно-телекоммуникационных систем и технологий обработки сигналов самой различной природы. Они буквально пронизывают современные отрасли знания, адекватно описывая многие физические и технологические процессы. Соответственно каждый научный работник и разработчик современной аппаратуры должен владеть как основами теории вероятности, так и современными вероятностными методами описания окружающего мира, получившими развитие в последние десятилетия.
Теория аномальных диффузионных процессов, является одним из таких – актуальных – направлений теории вероятностей. Дело в том, что хаотическое поведение природных объектов и технических систем часто демонстрирует отклонение от хорошо известного гауссова сценария поведения случайных процессов. Поэтому научному работнику и инженеру необходимо знать методы вероятностного описания аномальных хаотических явлений, такие как негауссовы предельные вероятностные распределения и аномальная диффузия, для которых нарушены условия применимости закона больших чисел и центральной предельной теоремы.
Не менее важные для разработчиков и пользователей информационно-телекоммуникационных систем, вопросы статистики потоков событий. Обсуждаются различия вероятностных свойств случайных интервалов, обусловленные различием способов измерения потоков событий.
Вероятностные методы решения задач, а также проведение наиболее перспективной технической политики в области создания новых информационных технологий и аппаратно-программных средств передачи и обработки данных были бы наиболее плодотворны, если бы опирались на общую теорию информационных систем. Пока не представляется возможным рассматривать эту теорию как сложившееся научное направление и ожидать в ближайшем будущем подробное и всеобъемлющее ее изложение. С другой стороны, бурный научно-технический прогресс в информатизации общества диктует необходимость формирования и развития этой теории.
Целью данного реферата является изучение вероятностных методов в обработке информации.
-
Обработка данных как информационный процесс
Обработка информации — преобразование информации из одного вида в другой, осуществляемое по строгим формальным правилам. Обработка информации по принципу «черного ящика» — процесс, в котором пользователю важна и необходима лишь входная и выходная информация, но правила, по которым происходит преобразование, его не интересуют и не принимаются во внимание.
Обработка информации — процесс планомерного изменения ее содержания или формы представления. Можно выделить несколько типов таких процессов: обработка, связанная с получением новой информации, нового содержания знаний, например, следователь по некоторому набору улик находит преступника; обработка, связанная с изменением формы, но не изменяющая содержания; например, перевод текста с одного языка на другой; сюда же можно отнести и структурирование данных (расположение данных в алфавитном порядке, группировка по признакам, табличное представление и т.п.); поиск информации в массиве, таком как телефонный справочник, словарь, расписание поездов и т.д.; если информация структурирована, то поиск осуществляется быстрее.
Обработка информации производится в соответствии с определенными правилами человеком или автоматическим устройством. Такой порядок называется алгоритмом в честь средневекового арабского математика Аль-Хорезми. Он один из первых детально исследовал наборы инструкций, описывающих порядок действий исполнителя для достижения некоторого результата.
Обработка информации — третий вид информационных процессов. Вот хорошо вам знакомый пример — решение математической задачи: даны значения длин двух катетов прямоугольного треугольника, нужно определить его третью сторону — гипотенузу. Чтобы решить задачу, ученик кроме исходных данных должен знать математическое правило, с помощью которого можно найти решение. В данном случае это теорема Пифагора: «квадрат гипотенузы равен сумме квадратов катетов». Применяя эту теорему, получаем искомую величину. Здесь обработка заключается и том, что новые данные получаются путем вычислений, выполненных над исходными данными.
Вычисление — лишь один из вариантов обработки информации. Новую информацию можно вывести не только путем математических расчетов. Вспомните истории Шерлока Холмса, героя книг Конан Дойля. Имея в качестве исходной информации часто очень запутанные показания свидетелей и косвенные улики, Холмс с помощью логических рассуждений прояснял всю картину событий и разоблачал преступника. Логические рассуждения — это еще один способ обработки информации.
Процесс обработки информации не всегда связан с получением каких-то новых сведений. Например, при переводе текста с одного языка на другой происходит обработка информации, изменяющая ее форму, но не содержание.
К этому же виду обработки относится кодирование информации.
Кодирование — это преобразование представления информации из одной символьной формы в другую, удобную для ее хранения, передачи или обработки.
Особенно широко понятие кодирования стало употребляться с развитием технических средств хранения, передачи и обработки информации (телеграф, радио, компьютеры). Например, в начале XX века телеграфные сообщения кодировались и передавались с помощью азбуки Морзе. Иногда кодирование производится в целях засекречивания содержания текста. В таком случае его называют шифрованием.
Еще одной разновидностью обработки информации является ее сортировка (иногда говорят — упорядочение). Например, вы решили записать адреса и телефоны всех своих одноклассников на отдельные карточки. В каком порядке нужно сложить эти карточки, чтобы затем было удобно искать среди них нужные сведения? Скорее всего, вы сложите их в алфавитном порядке по фамилиям. В информатике организация данных по какому-либо правилу, связывающему ее в единое целое, называется структурированием.
Процесс получения исходного сообщения из закодированного называют декодированием сообщения. Декодирование сообщений происходит, когда мы читаем вслух напечатанный текст, исполняем музыкальное произведение по нотам, расшифровываем сообщения, определяем по штрих-коду страну, в которой изготовлен товар, и т. п.
Для декодирования сообщения, закодированного шифром Цезаря со сдвигом на 4 буквы вправо, нужно каждую букву закодированного сообщения заменить другой, расположенной в алфавите на 4 позиции слева от заданной. Таким образом, декодировав сообщение «итефян ийса», получим «добрый день».
Кодирование и декодирование сообщений — это примеры процессов обработки данных.
Кодирование сообщения — это процесс замены одной последовательности сигналов, которой подано сообщение, другой последовательностью сигналов. Кодирование сообщений выполняется с целью их хранения, передачи, обработки, защиты. Для кодирования сообщений определяют набор сигналов, которые будут использованы для замены сигналов заданного сообщения, и правила, по которым происходит эта замена.
Декодирование сообщения — это процесс получения исходного сообщения из закодированного. Кодирование и декодирование сообщений — это примеры процессов обработки данных. Обработка информации производится в соответствии с определенными правилами некоторым субъектом или объектом (например, человеком или автоматическим устройством). Будем его называть исполнителем обработки информации.
Исполнитель обработки, взаимодействуя с внешней средой, получает из нее входную информацию, которая подвергается обработке. Результатом обработки является выходная информация, передаваемая внешней среде. Таким образом, внешняя среда выступает в качестве источника входной информации и потребителя выходной информации.
Обработка информации происходит по определенным правилам, известным исполнителю. Правила обработки, представляющие собой описание последовательности отдельных шагов обработки, называются алгоритмом обработки информации.
Исполнитель обработки должен иметь в своем составе обрабатывающий блок, который назовем процессором, и блок памяти, в котором сохраняются как обрабатываемая информация, так и правила обработки (алгоритм). Все сказанное схематически представлено на рисунке 1.

Рис. 1. Схема обработки информации
Схема, представленная на рисунке 1, — это общая схема обработки информации, не зависящая от того, кто (или что) является исполнителем обработки: живой организм или техническая система. Именно такая схема реализована техническими средствами в компьютере. Поэтому можно сказать, что компьютер является технической моделью «живой» системы обработки информации. В его состав входят все основные компоненты системы обработки: процессор, память, устройства ввода, устройства вывода.
Входная информация, представленная в символьной форме (знаки, буквы, цифры, сигналы), называется входными данными. В результате обработки исполнителем получаются выходные данные. Входные и выходные данные могут представлять собой множество величин — отдельных элементов данных. Если обработка заключается в математических вычислениях, то входные и выходные данные — это множества чисел. На следующем рисунке X: {x1, x2, …, xn} обозначает множество входных данных, а Y: {y1,y2, …, ym} — множество выходных данных:

Рис. 2. Схема обработки данных
Обработка заключается в преобразовании множества X в множество Y: P(X) ![]() Y
Y
Здесь Р обозначает правила обработки, которыми пользуется исполнитель. Если исполнителем обработки информации является человек, то правила обработки, по которым он действует, не всегда формальны и однозначны. Человек часто действует творчески, не формально. Даже одинаковые математические задачи он может решать разными способами. Работа журналиста, ученого, переводчика и других специалистов — это творческая работа с информацией, которая выполняется ими не по формальным правилам.
-
Вероятностные модели информационных открытых систем
Рассмотрим основные вероятностные модели порождения нечисловых данных. А именно, дихотомических данных, результатов парных сравнений, бинарных отношений, рангов, объектов общей природы.
Дихотомические данные. Рассмотрим базовую вероятностную модель дихотомических данных — бернуллиевский вектор (в терминологии энциклопедии — люсиан), т.е. конечную последовательность ![]() независимых испытаний Бернулли
независимых испытаний Бернулли ![]() , для которых
, для которых ![]() и
и![]()
![]()
![]() причем вероятности pi могут быть различны.
причем вероятности pi могут быть различны.
Бернуллиевские вектора часто применяются при практическом использовании эконометрических методов. Так, они использованы для описания равномерно распределенных случайных толерантностей. Как известно, толерантность на множестве из m элементов можно задать симметричной матрицей ||![]() || из 0 и 1, на главной диагонали которой стоят 1. Тогда случайная толерантность описывается распределением m(m-1)/2 дихотомических случайных величин
|| из 0 и 1, на главной диагонали которой стоят 1. Тогда случайная толерантность описывается распределением m(m-1)/2 дихотомических случайных величин ![]()
![]() а для равномерно распределенной толерантности эти случайные величины, как можно доказать, оказываются независимыми и принимают значения 0 и 1 с равными вероятностями 1/2. Записав элементы
а для равномерно распределенной толерантности эти случайные величины, как можно доказать, оказываются независимыми и принимают значения 0 и 1 с равными вероятностями 1/2. Записав элементы ![]() задающей такую толерантность матрицы в строку, получим бернуллиевский вектор с k=m(m-1)/2 и pi = 1/2,
задающей такую толерантность матрицы в строку, получим бернуллиевский вектор с k=m(m-1)/2 и pi = 1/2, ![]()
В связи с оцениванием по статистическим данным функции принадлежности нечеткой толерантности в 1970-е годы была построена теория случайных толерантностей с такими независимыми ![]() что вероятности
что вероятности ![]() произвольны. Случайные множества с независимыми элементами использовались как общий язык для описания парных сравнений и случайных толерантностей. В некоторых публикациях термин «люсиан» применялся как сокращение для выражения «случайные множества с независимыми элементами». Был выявлен ряд областей, в которых полезен математический аппарат решения различных статистических задач, связанных с бернуллиевскими векторами. Перечислим эти области, включая ранее названные: анализ случайных толерантностей; случайные множества с независимыми элементами; обработка результатов независимых парных сравнений; статистические методы анализа точности и стабильности технологического процесса, а также анализ и синтез планов статистического приемочного контроля; обработка маркетинговых и социологических анкет; обработка социально-психологических и медицинских данных, в частности, ответов на психологические тесты типа MMPI, топографических карт и т.д.
произвольны. Случайные множества с независимыми элементами использовались как общий язык для описания парных сравнений и случайных толерантностей. В некоторых публикациях термин «люсиан» применялся как сокращение для выражения «случайные множества с независимыми элементами». Был выявлен ряд областей, в которых полезен математический аппарат решения различных статистических задач, связанных с бернуллиевскими векторами. Перечислим эти области, включая ранее названные: анализ случайных толерантностей; случайные множества с независимыми элементами; обработка результатов независимых парных сравнений; статистические методы анализа точности и стабильности технологического процесса, а также анализ и синтез планов статистического приемочного контроля; обработка маркетинговых и социологических анкет; обработка социально-психологических и медицинских данных, в частности, ответов на психологические тесты типа MMPI, топографических карт и т.д.
Распределение бернуллиевского вектора Х полностью описывается вектором ![]() ,т.е. нечетким подмножеством множества {1,2,…,k}. Действительно, для любого детерминированного вектора
,т.е. нечетким подмножеством множества {1,2,…,k}. Действительно, для любого детерминированного вектора ![]() из 0 и 1 имеем
из 0 и 1 имеем ![]() где h(x,p)=p при х = 1 и h(х,р)=1 — р при х=0.
где h(x,p)=p при х = 1 и h(х,р)=1 — р при х=0.
Теперь можно уточнить способы использования люсианов в прикладной статистике. Бернуллиевскими векторами можно моделировать: результаты статистического контроля (0 — годное изделие, 1 — дефектное); результаты маркетинговых и социологических опросов (0 — опрашиваемый выбрал первую из двух подсказок, 1 — вторую; распределение посторонних включений в материале (0 — нет включения в определенном объеме материала, 1 — есть); результаты испытаний и анализов (0 — нет нарушений требований нормативно-технической документации, 1 — есть такие нарушения); процессы распространения, например, пожаров (0 — нет загорания, 1 — есть); технологические процессы (0 — процесс находится в границах допуска, 1 — вышел из них); ответы экспертов (опрашиваемых) о сходстве объектов (проектов, образцов) и т.д.
Парные сравнения. Общую модель парных сравнений опишем согласно монографии Г. Дэвида. Предположим, что t объектов ![]() сравниваются попарно каждым из nэкспертов. Всего возможных пар для сравнения имеется
сравниваются попарно каждым из nэкспертов. Всего возможных пар для сравнения имеется ![]() Эксперт с номером
Эксперт с номером ![]() делает
делает ![]() повторных сравнений для каждой из s возможностей. Пусть
повторных сравнений для каждой из s возможностей. Пусть ![]() i,j=1,2,…,t,
i,j=1,2,…,t, ![]()
![]() =1,2,…,n;
=1,2,…,n; ![]() =1,2,…,
=1,2,…, ![]() , — случайная величина, принимающая значение 1 или 0 в зависимости от того, предпочитает ли эксперт
, — случайная величина, принимающая значение 1 или 0 в зависимости от того, предпочитает ли эксперт ![]() объект Ai или объект Aj в
объект Ai или объект Aj в ![]() -м сравнении двух объектов. Предполагается, что все сравнения проводятся независимо друг от друга, так что случайные величины
-м сравнении двух объектов. Предполагается, что все сравнения проводятся независимо друг от друга, так что случайные величины ![]() независимы в совокупности, если не считать того, что
независимы в совокупности, если не считать того, что ![]()
![]() Положим
Положим ![]() Ясно, что описанная модель парных сравнений представляет собой частный случай бернуллиевского вектора. В этой модели число наблюдений равно числу неизвестных параметров, поэтому для получения статистических выводов необходимо наложить априорные условия на
Ясно, что описанная модель парных сравнений представляет собой частный случай бернуллиевского вектора. В этой модели число наблюдений равно числу неизвестных параметров, поэтому для получения статистических выводов необходимо наложить априорные условия на ![]() , например:
, например: ![]() (нет эффекта от повторений);
(нет эффекта от повторений); ![]() (нет эффекта от повторений и от экспертов).
(нет эффекта от повторений и от экспертов).
Теорию независимых парных сравнений целесообразно разделить на две части — непараметрическую, в которой статистические задачи ставятся непосредственно в терминах ![]() , и параметрическую, в которой вероятности
, и параметрическую, в которой вероятности ![]() выражаются через меньшее число иных параметров. Ряд результатов непараметрической теории парных сравнений непосредственно вытекает из теории бернуллиевских векторов.
выражаются через меньшее число иных параметров. Ряд результатов непараметрической теории парных сравнений непосредственно вытекает из теории бернуллиевских векторов.
В параметрической теории парных сравнений наиболее популярна так называемая линейная модель, в которой предполагается , что каждому объекту Ai можно сопоставить некоторую «ценность» Vi так, что вероятность предпочтения ![]() (т.е. предполагается дополнительно, что эффект от повторений и от экспертов отсутствует) выражается следующим образом:
(т.е. предполагается дополнительно, что эффект от повторений и от экспертов отсутствует) выражается следующим образом:
![]() (1)
(1)
где H(x) — функция распределения, симметричная относительно 0, т.е.
![]() (2)
(2)
при всех x.
Широко применяются модели Терстоуна — Мостеллера и Брэдли — Терри, в которых H(х)- соответственно функции нормального и логистического распределений. Поскольку функцияФ(х) стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1 и функция ![]() стандартного логистического распределения удовлетворяют соотношению
стандартного логистического распределения удовлетворяют соотношению ![]() то для обоснованного выбора по статистическим данным между моделями Терстоуна-Мостеллера и Брэдли-Терри необходимо не менее тысячи наблюдений.
то для обоснованного выбора по статистическим данным между моделями Терстоуна-Мостеллера и Брэдли-Терри необходимо не менее тысячи наблюдений.
Соотношение (1) вытекает из следующей модели поведения эксперта: он измерят «ценность» Vi и Vj объектов Ai и Aj, но с ошибками ![]() и
и ![]() соответственно, а затем сравнивает свои оценки ценности объектов
соответственно, а затем сравнивает свои оценки ценности объектов ![]() и
и ![]() Если
Если ![]() то он предпочитает Ai, в противном случае — Aj. Тогда
то он предпочитает Ai, в противном случае — Aj. Тогда
![]() (3)
(3)
Обычно предполагают, что субъективные ошибки эксперта ![]() и
и ![]() независимы и имеют одно и то же непрерывное распределение. Тогда функция распределения Н(х) из соотношения (3) непрерывна и удовлетворяет функциональному уравнению (2).
независимы и имеют одно и то же непрерывное распределение. Тогда функция распределения Н(х) из соотношения (3) непрерывна и удовлетворяет функциональному уравнению (2).
Рассмотренные модели парных сравнений могут быть обобщены в различных направлениях. Так, можно ввести понятие «ничья «- ситуации, когда эксперт оценивает объекты одинаково. Модели с учетом «ничьих» предполагают, что эксперт может отказаться от выбора одного из объектов и заявить об их эквивалентности, т. е. число возможных ответов увеличивается с 2 до 3. В моделях множественных сравнений эксперту представляется не два объекта , а три или большее число
Можно строить модели, учитывающие порядок предъявления объектов при сравнении, зависимость результата сравнения от результатов предшествующих сравнений. Опишем одну из подобных моделей.
Пусть эксперт сравнивает три объекта — A, B, C, причем сначала сравниваются A и B, потом — B и C и, наконец, A и C. Для определенности пусть A > B будет означать, что A более предпочтителен, чем B. Пусть при предъявлении двух объектов ![]() Теперь пусть пара B, C предъявляется после пары A, B. Естественно предположить, что высокая оценка B в первом сравнении повышает вероятность предпочтения B и во втором, и, наоборот, отрицательное мнение о B в первом сравнении сохраняется и при проведении второго сравнения. Это предположение проще всего учесть в модели следующим образом:
Теперь пусть пара B, C предъявляется после пары A, B. Естественно предположить, что высокая оценка B в первом сравнении повышает вероятность предпочтения B и во втором, и, наоборот, отрицательное мнение о B в первом сравнении сохраняется и при проведении второго сравнения. Это предположение проще всего учесть в модели следующим образом: ![]() где
где ![]() — некоторое положительное число, показывающее степень влияния первого сравнения на второе. По аналогичным причинам вероятности исхода третьего сравнения в зависимости от результатов первых двух можно описать так:
— некоторое положительное число, показывающее степень влияния первого сравнения на второе. По аналогичным причинам вероятности исхода третьего сравнения в зависимости от результатов первых двух можно описать так:

Статистическая задача состоит в определении параметров ![]()
![]()
![]() и
и ![]() по результатам сравнений, проведенных n экспертами, и в проверке адекватности модели. Ясно, что можно рассматривать и другие модели, в частности, учитывающие тягу экспертов к транзитивности ответов. Очевидно, что проблемы построения моделей парных сравнений относятся не к прикладной статистике, а к тем прикладным областям, для решения задач которых развиваются методы парных сравнений, например, к экономике предприятия, стратегическому менеджменту, производственной психологии, изучению поведения потребителей, экспертным оценкам и т. д.
по результатам сравнений, проведенных n экспертами, и в проверке адекватности модели. Ясно, что можно рассматривать и другие модели, в частности, учитывающие тягу экспертов к транзитивности ответов. Очевидно, что проблемы построения моделей парных сравнений относятся не к прикладной статистике, а к тем прикладным областям, для решения задач которых развиваются методы парных сравнений, например, к экономике предприятия, стратегическому менеджменту, производственной психологии, изучению поведения потребителей, экспертным оценкам и т. д.
Отметим некоторые сложности при обосновании возможности использовании линейных моделей типа (1) — (3). Вероятностно-статистическая теория достаточно проста, когда предполагается, что каждому отдельному сравнению двух объектов соответствуют свои собственные ошибки экспертов, причем все ошибки независимы в совокупности. Однако это предположение отнюдь не очевидно с содержательной точки зрения. В качестве примера рассмотрим три объекта A, B и C, которые сравнивают попарно: A и B, B и C, A и C. В соответствии со сказанным, в рассмотрение вводят 6 ошибок одного и того же эксперта: ![]() и
и ![]() в первом сравнении,
в первом сравнении, ![]() и
и ![]() -во втором,
-во втором, ![]() и
и ![]() — в третьем, причем все эти 6 случайных величин независимы в совокупности. Между тем естественно думать, что мнения эксперта об одном и том же объекте связаны между собой, т. е.
— в третьем, причем все эти 6 случайных величин независимы в совокупности. Между тем естественно думать, что мнения эксперта об одном и том же объекте связаны между собой, т. е. ![]() и
и ![]() зависимы, равно как
зависимы, равно как ![]() и
и ![]() , а также
, а также ![]() и
и ![]() . Более того, если принять, что точка зрения эксперта полностью определена для него самого, то следует положить
. Более того, если принять, что точка зрения эксперта полностью определена для него самого, то следует положить ![]() =
=![]() и соответственно
и соответственно ![]() =
=![]() и
и ![]() =
=![]() . При этом, напомним, случайные величины
. При этом, напомним, случайные величины![]() ,
, ![]() и др. интерпретируется как отклонения мнений отдельных экспертов от истины. Видимо, ошибку эксперта целесообразно считать состоящей из двух слагаемых, а именно: отклонения от истины, вызванного внутренними особенностями эксперта и колебания мнения эксперта в связи с очередным парным сравнением. Игнорирование систематической погрешности облегчает развитие математико-статистической теории, а ее учет приводит к необходимости изучения зависимых парных сравнений.
и др. интерпретируется как отклонения мнений отдельных экспертов от истины. Видимо, ошибку эксперта целесообразно считать состоящей из двух слагаемых, а именно: отклонения от истины, вызванного внутренними особенностями эксперта и колебания мнения эксперта в связи с очередным парным сравнением. Игнорирование систематической погрешности облегчает развитие математико-статистической теории, а ее учет приводит к необходимости изучения зависимых парных сравнений.
При обработке результатов парных сравнений первый этап — проверка согласованности. Понятие согласованности уточняется различными способами, но все они имеют один и тот же смысл проверки однородности обрабатываемого материала, т.е. того, что целесообразно агрегировать мнения отдельных экспертов, объединить данные и совместно их обрабатывать. При отсутствии однородности данные разбиваются на группы с целью обеспечения однородности внутри отдельных групп. Естественно, согласованность целесообразно проверять, вводя возможно меньше гипотез о структуре данных. Следовательно, целесообразно пользоваться для этого непараметрической теорией парных сравнений, основанной на теории бернуллиевских векторов.
Хорошо известно, что модели парных сравнений с успехом применяются в экспертных и экспериментальных процедурах упорядочивания и выбора. В частности, для анализа голосований, турниров, выбора наилучшего объекта; в планировании и анализе сравнительных экспериментов и испытаний; в органолептической экспертизе; при изучении поведения потребителей; визуальной колоритмии, определении индивидуальных рейтингов и вообще изучении предпочтений при выборе и т. д.
Бинарные отношения. Теорию ранговой корреляции можно рассматривать как теорию статистического анализа случайных ранжировок, равномерно распределенных на множестве всех ранжировок. Так, при обработке данных классического психофизического эксперимента по упорядочению кубиков соответственно их весу, подробно описанного в работе, оказалась адекватной следующая т.н. Т-модель ранжирования.
Пусть имеется t объектов ![]() причем каждому объекту
причем каждому объекту ![]() соответствует число ai, описывающее его положение на шкале изучаемого признака. Испытуемый упорядочивает объекты так, как если бы оценивал соответствующие им значения с ошибками, т.е. находил
соответствует число ai, описывающее его положение на шкале изучаемого признака. Испытуемый упорядочивает объекты так, как если бы оценивал соответствующие им значения с ошибками, т.е. находил ![]() i=1,2,…n, где
i=1,2,…n, где ![]() — ошибка при рассмотрении i-го объекта, а затем располагал бы объекты в том порядке, в каком располагаются
— ошибка при рассмотрении i-го объекта, а затем располагал бы объекты в том порядке, в каком располагаются ![]() В этом случае вероятность появления упорядочения
В этом случае вероятность появления упорядочения ![]() есть
есть ![]() а ранги
а ранги ![]() объектов являются рангами случайных величин
объектов являются рангами случайных величин ![]() , полученными при их упорядочении в порядке возрастания. Кроме того, для простоты расчетов в модели предполагается, что ошибки испытуемого
, полученными при их упорядочении в порядке возрастания. Кроме того, для простоты расчетов в модели предполагается, что ошибки испытуемого ![]() независимы и имеют нормальное распределение с математическим ожиданием 0 и дисперсией
независимы и имеют нормальное распределение с математическим ожиданием 0 и дисперсией ![]() .
.
Бинарное отношение на множестве из t элементов полностью описывается матрицей из 0 и 1 порядка ![]() . Поэтому задать распределение случайного бинарного отношения — это то же самое, что задать распределение вероятностей на множестве всех матриц описанного вида, состоящем из
. Поэтому задать распределение случайного бинарного отношения — это то же самое, что задать распределение вероятностей на множестве всех матриц описанного вида, состоящем из ![]() элементов. Пространства ранжировок, разбиений, толерантностей зачастую удобно считать подпространствами пространства всех бинарных отношений, тогда распределения вероятностей на них — частные случаи описанного выше распределения, выделенные тем, что вероятности принадлежности соответствующим подпространствам равны 1. Распределение произвольного бинарного отношения описывается
элементов. Пространства ранжировок, разбиений, толерантностей зачастую удобно считать подпространствами пространства всех бинарных отношений, тогда распределения вероятностей на них — частные случаи описанного выше распределения, выделенные тем, что вероятности принадлежности соответствующим подпространствам равны 1. Распределение произвольного бинарного отношения описывается ![]() -1 параметрами, распределение случайной ранжировки (без связей) — (t! — 1) параметрами, а описанная выше T-модель ранжирования — (t + 1) параметром. При t = 4 эти числа равны соответственно 65535, 23 и 5. Первое из этих чисел показывает практическую невозможность использования в вероятностно-статистических моделях произвольных бинарных отношений, поскольку по имеющимся данным невозможно оценить столь большое число параметров. Приходится ограничиваться теми или иными семействами бинарных отношений — ранжировками, разбиениями, толерантностями и др. Модель произвольной случайной ранжировки при t = 5 описывается 119 параметрами, при t = 6 — уже 719 параметрами, при t = 7 число параметром достигает 5049, что уже явно за возможностями оценивания. В то же время T-модель ранжирования при t = 7 описывается всего 8-ю параметрами, а потому может быть кандидатом для практического использования.
-1 параметрами, распределение случайной ранжировки (без связей) — (t! — 1) параметрами, а описанная выше T-модель ранжирования — (t + 1) параметром. При t = 4 эти числа равны соответственно 65535, 23 и 5. Первое из этих чисел показывает практическую невозможность использования в вероятностно-статистических моделях произвольных бинарных отношений, поскольку по имеющимся данным невозможно оценить столь большое число параметров. Приходится ограничиваться теми или иными семействами бинарных отношений — ранжировками, разбиениями, толерантностями и др. Модель произвольной случайной ранжировки при t = 5 описывается 119 параметрами, при t = 6 — уже 719 параметрами, при t = 7 число параметром достигает 5049, что уже явно за возможностями оценивания. В то же время T-модель ранжирования при t = 7 описывается всего 8-ю параметрами, а потому может быть кандидатом для практического использования.
Что естественно предположить относительно распределения случайного элемента со значениями в том или ином пространстве бинарных отношений? Зачастую целесообразно считать, что распределение имеет некий центр, попадание в который наиболее вероятно, а по мере удаления от центра вероятности убывают. Это соответствует естественной модели измерения с ошибкой; в классическом одномерном случае результат подобного измерения обычно описывается унимодальной симметричной плотностью, монотонно возрастающей слева от модального значения, в котором плотность максимальна, и монотонно убывающей справа от него. Чтобы ввести понятие монотонного распределения в пространстве бинарных отношений, будем исходить из метрики в этом пространстве. Воспользовавшись тем, что бинарные отношения C и D однозначно описываются матрицами ![]() и
и ![]() порядка
порядка ![]() соответственно, рассмотрим расстояние (в несколько другой терминологии — метрику) в пространстве бинарных отношений
соответственно, рассмотрим расстояние (в несколько другой терминологии — метрику) в пространстве бинарных отношений ![]() (4)
(4)
Метрика (4) в различных пространствах бинарных отношений — ранжировок, разбиений, толерантностей — может быть введена с помощью соответствующих систем аксиом (см. главу 1.1). В настоящее время метрику (4) обычно называют расстоянием Кемени в честь американского исследователя Джона Кемени, впервые получившего эту метрику исходя из предложенной им системы аксиом для расстояния между упорядочениями (ранжировками).
Определение 1. Распределение бинарного отношения X называется монотонным с центром в C0 относительно расстояния (показателя различия) d, если из d(C,C0) < d(D,C0) следует, что P(X=C) > P(X=D).
Это определение впервые введено в монографии. Оно может использоваться в любых пространствах бинарных отношений и, более того, в любых пространствах из конечного числа элементов, лишь бы в них была введена функция d(C,D) — показатель различия элементов С и D этого пространства. Монотонное распределение унимодально, мода находится в С0.
Определение 2. Распределение бинарного отношения X называется симметричным относительно расстояния d с центром в C0, если существует такая функция ![]() что
что ![]() (5)
(5)
Если распределение X монотонно и таково, что из d(C,C0) = d(D,C0) следует P(X=C) =P(X=D), то оно симметрично. Если функция f в формуле (5) монотонно строго убывает, то соответствующее распределение монотонно в смысле определения 1.
Поскольку толерантность на множестве из t элементов задается 0,5t(t — 1) элементами матрицы из 0 и 1 порядка ![]() , лежащими выше главной диагонали, то распределение на множестве толерантностей задается в общем случае
, лежащими выше главной диагонали, то распределение на множестве толерантностей задается в общем случае ![]() параметрами. Естественно выделить семейство распределений, соответствующее независимым элементам матрицы. Оно задается бернуллиевским вектором (люсианом) с 0,5t(t — 1) параметрами. Математическая техника, необходимая для изучения толерантностей с независимыми элементами, существенно проще, чем в случае ранжировок и разбиений. Здесь легко отказаться от условия равномерности распределения. Этому условию соответствует pij ≡ 1/2, в то время как статистические методы анализа люсианов, развитые в статистике нечисловых данных не налагают никаких существенных ограничений на pij .
параметрами. Естественно выделить семейство распределений, соответствующее независимым элементам матрицы. Оно задается бернуллиевским вектором (люсианом) с 0,5t(t — 1) параметрами. Математическая техника, необходимая для изучения толерантностей с независимыми элементами, существенно проще, чем в случае ранжировок и разбиений. Здесь легко отказаться от условия равномерности распределения. Этому условию соответствует pij ≡ 1/2, в то время как статистические методы анализа люсианов, развитые в статистике нечисловых данных не налагают никаких существенных ограничений на pij .
Заключение
Современные методы описания процессов в информационных системах разнообразны и требуют различного смыслового содержания и представления для применения в инженерной практике. Среди них все большее значение приобретают вероятностные методы исследований, основанные на вероятностной трактовке протекающих в информационных системах процессов.
Вероятностный (статистический) подход позволяет более полно учесть состояние динамической системы, характер управляющих и возмущающих воздействий, результирующее поведение информационных потоков в больших вычислительных сетях и во многих случаях более адекватен практическим задачам. Круг вытекающих из указанного подхода проблем, охватываемых пособием, достаточно широк: описание математических моделей случайных процессов в информационных системах, формирование на их базе статистических методов проверки гипотез и обнаружения, оценивания и фильтрации, интерполяции (сглаживания) и экстраполяции (прогнозирования), а также разработка алгоритмов оптимального управления стохастическими системами.
Вероятностно-статистические методы, развитые для результатов наблюдений из пространств произвольного вида, позволяют единообразно проводить анализ данных из любого конкретного пространства. Они применены к конечным случайным множествам, к нечетким множествам. С их помощью установлено поведение обобщенного мнения экспертной комиссии (медианы Кемени) при увеличении числа экспертов, когда ответы экспертов лежат в том или ином пространстве бинарных отношений. Методы классификации могут быть основаны на непараметрических оценках плотности распределения вероятностей в пространстве общей природы.
Рри обработке мнений экспертов сначала проверяют согласованность. В частности, если мнения экспертов описываются монотонными распределениями, то для согласованности необходимо совпадение центров этих распределений. К сожалению, рассмотренные выше классические методы проверки согласованности для ранжировок, основанные на коэффициентах ранговой корреляции и конкордации, позволяют лишь отвергнуть гипотезу о равнораспределенности. Но не установить, можно ли считать, что центры соответствующих экспертам распределений совпадают или же, например, существует две группы экспертов, каждая со своим центром. Теория случайных толерантностей лишена этого недостатка. Отсюда вытекают следующие практические рекомендации.
Список использованной литературы
- Вдовин, В.М. Теория систем и системный анализ: Учебник для бакалавров / В.М. Вдовин, Л.Е. Суркова. — М.: Дашков и К, 2016. — 644 c.
- Волкова, В.Н. Системный анализ информационных комплексов: Учебное пособие / В.Н. Волкова. — СПб.: Лань, 2016. — 336 c.
- Волкова, В.Н. Теория систем и системный анализ: Учебник для академического бакалавриата / В.Н. Волкова, А.А. Денисов. — Люберцы: Юрайт, 2016. — 462 c.
- Гренандер, У. Краткий курс вычислительной вероятности и статистики / У. Гренандер, В. Фрайбергер. — М.: Главная редакция физико-математической литературы издательства «Наука», 2016. — 192 c.
- Громова, Е., Н. Системный анализ информационных комплексов: Учебное пособие / Е. Н. Громова. — СПб.: Лань, 2016. — 336 c.
- Данелян, Т.Я. Теория систем и системный анализ: Учебно-методический комплекс / Т.Я. Данелян. — М.: Ленанд, 2016. — 360 c.
- Дрогобыцкий, И.Н. Системный анализ в экономике: Учебник / И.Н. Дрогобыцкий. — М.: ЮНИТИ, 2016. — 423 c.
- Жевержеев, В. Ф. Специальный курс математики для вузов / В.Ф. Жевержеев, Л.А. Кальницкий, Н.А. Сапогов. — М.: Высшая школа, 2016. — 416 c.
- Каган, А. М. Характеризационные задачи математической стастистики / А.М. Каган, Ю.В. Линник, С.Р. Рао. — М.: Наука, 2017. — 656 c.
- Качала, В.В. Теория систем и системный анализ: Учебник для студентов образовательных учреждений среднего профессионального образования / В.В. Качала.. — М.: ИЦ Академия, 2017. — 272 c.
- Козлов, В.Н. Системный анализ, оптимизация и принятие решений / В.Н. Козлов. — М.: Проспект, 2016. — 176 c.
- Колмогоров, А. Н. Введение в теорию вероятностей: моногр. / А.Н. Колмогоров, И.Г. Журбенко, А.В. Прохоров. — М.: МЦНМО, 2017. — 168 c.
- Кочетыгов, А. А. Основы эконометрики / А.А. Кочетыгов, Л.А. Толоконников. — М.: Издательский центр «МарТ», 2017. — 352 c.
- Мацкевич, И. П. Высшая математика. Теория вероятностей и математическая статистика / И.П. Мацкевич, Г.П. Свирид. — М.: Вышэйшая школа, 2017. — 272 c.
- Пугачев, В. С. Теория вероятностей и математическая статистика / В.С. Пугачев. — Москва: Высшая школа, 2018. — 496 c.
- Рогов, С. Ф. Математические методы в теории принятия решений / С.Ф. Рогов. — Москва: Наука, 2017. — 148 c.
- Тутубалин, В. Н. Теория вероятностей / В.Н. Тутубалин. — М.: Издательство МГУ, 2016. — 232 c.
- Федоткин, М. А. Модели в теории вероятностей / М.А. Федоткин. — М.: ФИЗМАТЛИТ, 2016. — 608 c.
- Хеннан, Э. Многомерные временные ряды / Э. Хеннан. — Москва: Гостехиздат, 2016. — 576 c.
- Юдицкий, С.А. Теория систем и системный анализ в управлении организациями: Учебное пособие / С.А. Юдицкий. — М.: Финансы и статистика, 2017. — 848 c.
- Яковлев, С.В. Теория систем и системный анализ. Лабораторный практикум: Учебное пособие для ВУЗов, перераб., и доп / С.В. Яковлев. — М.: ГЛТ, 2017. — 320 c.