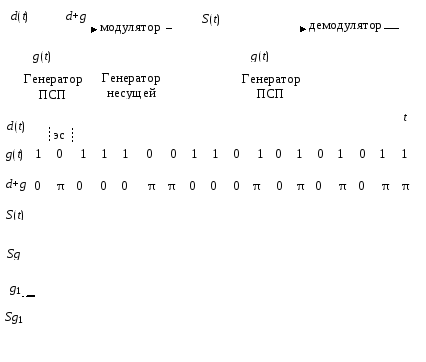
При
оценке энергетического выигрыша
кодирования кодов, различающихся длиной
блока и кодовой скоростью, более удобной
оказывается характеристика
помехоустойчивости, выражаемая через
вероятность ошибки на двоичный символ
(бит).
Соотношение
между вероятностями ошибки декодирования
слова и ошибки на бит определяется
структурой порождающей матрицы
конкретного кода. Однако для обобщенного
анализа могут быть получены простые
границы для вероятности ошибки на бит.
Пусть длительность сеанса связи
составляет 1с. Тогда за сеанс связи может
быть передано 1/TW
кодовых слов, которые содержат k/TW
информационных символов. Количество
ошибочно принятых кодовых слов равно
PWk/TW.
Если через k0
обозначить количество ошибочно
принятых информационных символов при
каждом ошибочно принятом кодовом слове,
то вероятность ошибки на бит будет равна
![]()
. (3.19)
Проблема
заключается в определении величины k0.
В наихудшем случае ошибочный прием
кодового слова сопровождается ошибочным
приемом всех k
информационных символов. Тогда
получаем верхнюю границу
![]()
. (3.20)
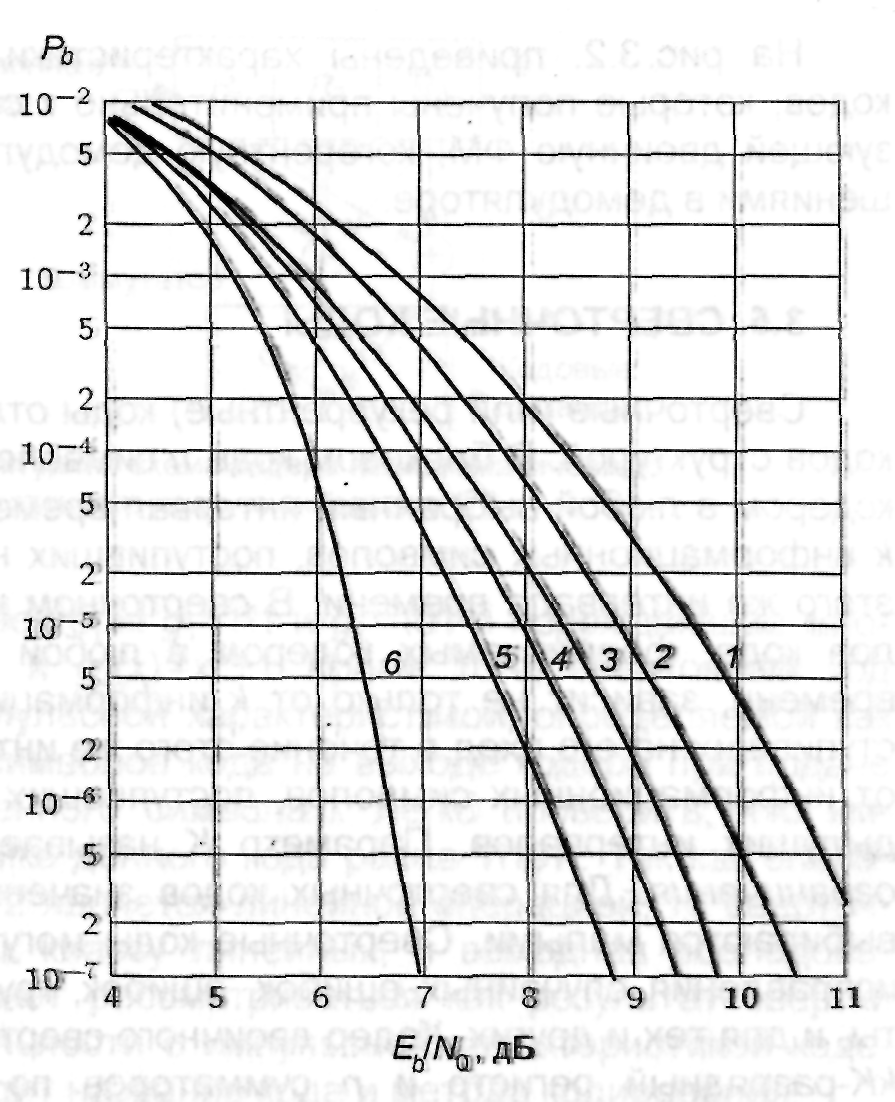
Рис.3.2.
Характеристики помехоустойчивости
блоковых кодов: 1 – без кодирования; 2 –
код Хэмминга (7, 4); 3 – код Хэмминга
(15, 11); 4 – код Хэмминга (31, 26); 5 – код
Голея (24, 12); 6 – код БЧХ (127, 64)
В
лучшем случае ошибочный прием кодового
слова приводит к единственной ошибке
в информационных символах. Поэтому для
нижней границы имеем k0=1
и
![]()
. (3.21)
Для
малых значений k
верхняя и нижняя границы становятся
строгими, и для оценки вероятности
ошибки на бит может быть использована
вероятность ошибочного приема слова.
Для высоких значений Eb/N0
вероятность ошибки на символ оказывается
чрезвычайно малой и ошибки при
декодировании кодовых слов с большой
вероятностью возникают при появлении
(t+1) ошибочных символов.
Из этих (t+1) ошибочных
символов в среднем (t+1)/n
относится к информационным. В результате
![]()
, (3.22)
![]()
. (3.23)
На
рис. 3.2. приведены характеристики
некоторых блоковых кодов, которые
получены применительно к системе связи,
использующей двоичную ФМ, когерентную
демодуляцию с жесткими решениями в
демодуляторе.
3.5. Сверточные коды
Сверточные
(или рекуррентные) коды отличаются от
блоковых кодов структурой. В блоковом
коде n символов кода, формируемых
кодером в любой выбранный интервал
времени, зависят только от k
информационных символов, поступивших
на его вход в течение этого же интервала
времени. В сверточном коде блок из n
символов кода, формируемых кодером
в любой выбранный интервал времени,
зависит не только от k
информационных символов, поступивших
на его вход в течение этого же интервала
времени, но и от информационных символов,
поступивших в течение (K–1)
предыдущих интервалов. Параметр K
называется длиной кодового
ограничения. Для сверточных кодов
значение параметров n и k
выбираются малыми. Сверточные коды
могут использоваться для исправления
случайных ошибок, ошибок, группирующихся
в пакеты, и для тех и других. Кодер
двоичного сверточиого кода содержит
kK-разрядный регистр
и n сумматоров по mod
2. Обобщенная структурная схема кодера
сверточного кода приведена на рис.3.3.
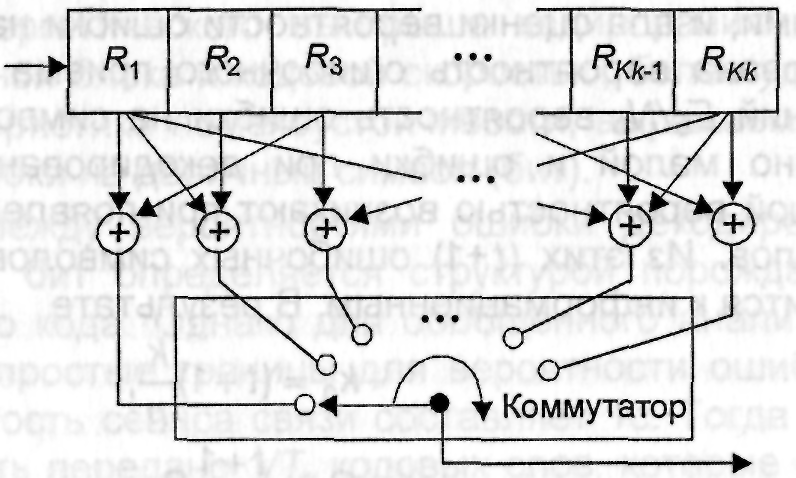
Рис.
3.3. Обобщенная структурная схема
кодера сверточного кода
На
рис. 3.4 приведены пример кодера сверточного
кода с параметрами k =1,
n = 2,
K = 3,
Rk = 1/2.
Информационные символы поступают на
вход регистра, а символы кода формируются
на выходе коммутатора. Коммутатор (КМ)
последовательно опрашивает выходы
сумматоров по mod 2 в течение
интервала времени, равного длительности
информационного символа (бита).
Схема
подключения сумматоров по mod
2, значения k, n и K
полностью описывают сверточный код. Их
можно определить с помощью генераторных
векторов или многочленов. Например,
сверточный код, формируемый кодером,
изображенным на рис.3.4,
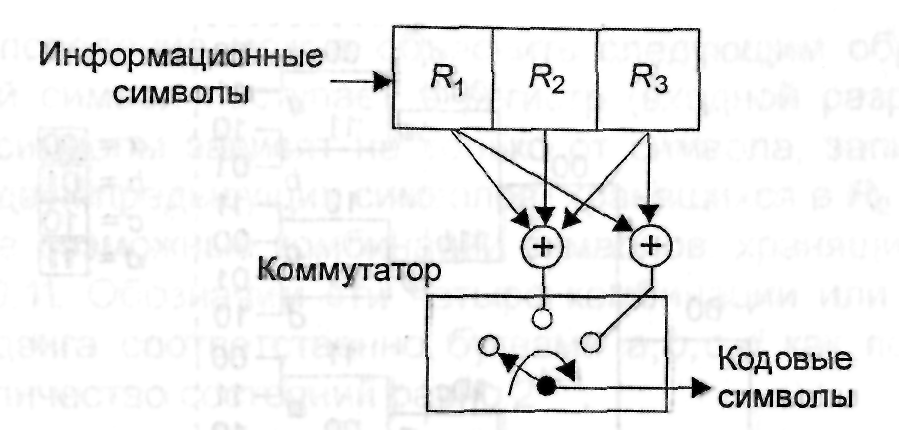
Рис.
3.4. Структурная
схема кодера несистематического
сверточного кода со скоростью 1/2
Информационные
символы имеет порождающие векторы
g1 = 111
и g2 = 101
и порождающие многочлены g1(х) = х2+х+1
и g2(х)=х2+1.
Кроме того, сверточный код может быть
задан импульсной характеристикой,
определяемой как последовательность
символов кода на выходе кодера при
подаче на его вход единственного символа
1. Легко проверить, что импульсная
характеристика данного кода равна
111011. Так как операция сложения по mod
2 является линейной операцией, то
сверточные коды относятся к классу
линейных, и выходная последовательность
кодера может рассматриваться как
результат свертки входной последовательности
с импульсной характеристикой кодера.
Отсюда и происходит название кода и
метода кодирования.
Процедуры
кодирования и декодирования удобно
описывать с помощью так называемого
кодового дерева, которое отображает
последовательности на выходе кодера
для любой возможной входной
последовательности. На рис. 3.5 приведено
кодовое дерево кодера, изображенного
на рис. 3.4, для блока из пяти информационных
символов. Если первый символ принимает
значение 0, то на выходе кодера формируется
пара символов 00. Если первый символ
принимает значение 1, то на выходе кодера
формируется пара символов 11. Это показано
с помощью двух ветвей, которые выходят
из начального узла. Верхняя ветвь
соответствует 0, нижняя – 1. В каждом из
последующих узлов ветвление происходит
аналогичным образом: из каждого узла
исходит две ветви, причем верхняя ветвь
соответствует 0, а нижняя – 1. Ветвление
будет происходить вплоть до последнего
символа входного блока. Вслед за ним
все входные символы принимают значение
0, и образуется только одна обрывающаяся
ветвь. Таким образом, каждой из возможных
входных комбинаций информационных
символов соответствует своя вершина
на кодовом дереве. В данном случае
имеется 32 вершины. С помощью кодового
дерева легко построить выходную
последовательность символов кода,
соответствующую определенной входной
последовательности. Например, входной
последовательности 11010 соответствует
выходная последовательность, лежащая
на пути, изображенном пунктирной линией.

Рис.3.5.
Кодовое дерево для кодера, изображенного
на рис. 3.4
Анализируя
структуру кодового дерева на рис. 3.5,
можно заметить, что, начиная с узлов
третьего уровня, она носит повторяющийся
характер. Действительно, группа ветвей,
заключенных в прямоугольники, изображенные
пунктирными линиями, полностью совпадают.
Это означает, что при поступлении на
вход четвертого символа выходной символ
кода будет одним и тем же, независимо
от того, каким был первый входной символ:
0 или 1. Другими словами, после первых
трех групп выходных символов кода
входные последовательности 1x1x2x3x4…
и 0x1x2x3x4…
будут порождать один и тот же выходной
символ.
Обозначим
четыре узла третьего уровня, т.е. узлы,
в которых происходит третье ветвление,
буквами a,b,c,d.
Повторяющаяся структура ветвей имеет
место и для узлов четвертого и пятого
уровней, поэтому их также можно обозначить
этими же буквами. Для узлов пятого уровня
любой из четырех комбинаций (11,10,01, 00)
первых двух входных символов будет
соответствовать один и тот же выходной
символ.
Такое
поведение можно объяснить следующим
образом. Когда входной символ поступает
в регистр (входной разряд R1),
то выходные символы зависят не только
от символа, записанного в R1,
но и от двух предыдущих символов,
хранящихся в R2
и R3.
Имеется четыре возможные комбинации
символов, хранящихся в R2
и R3:
00, 01, 10, 11. Обозначим эти четыре комбинации
или состояния регистра сдвига
соответственно буквами a,
b, c,
d как показано на
рис. 3.5. Количество состояний равно 2K–1.
Входные
символы 0 и 1 будут формировать четыре
различные комбинации выходных символов
в зависимости от состояния кодера. Если
входной символ 0, то на выходе декодера
будут формироваться 00, 10, 11 или 01 в
зависимости от того, в каком состоянии
находился кодер: a, b,
c или d.
To же самое правило можно
применить относительно символа 1.
Таким
образом, поведение кодера можно полностью
описать с помощью диаграммы состояний,
изображенной на рис. 3.6, а или
направленного графа с четырьмя состояниями
(рис. 3.6, б) который устанавливает
однозначное соответствие между входными
и выходными символами кодера. На графе
сплошные линии соответствуют входному
символу 0, а пунктирные – символу 1.
Например, если кодер находится в состоянии
а и на вход поступает 1, то на выходе
декодера будет формироваться комбинация
11 (пунктирная линия) и декодер перейдет
в состояние b,
соответствующее R3 = 0
и R2 = 1
– Аналогичным образом при поступлении
0 декодер останется в состоянии а
(сплошная линия) и на выходе будет
формироваться комбинация 00.
Заметим,
что прямой переход из состояния а в
состояние с или d
невозможен, причем из любого состояния
прямой переход возможен только в одно
из двух состояний. Диаграмма состояний
содержит исчерпывающую информацию о
структуре кодового дерева.
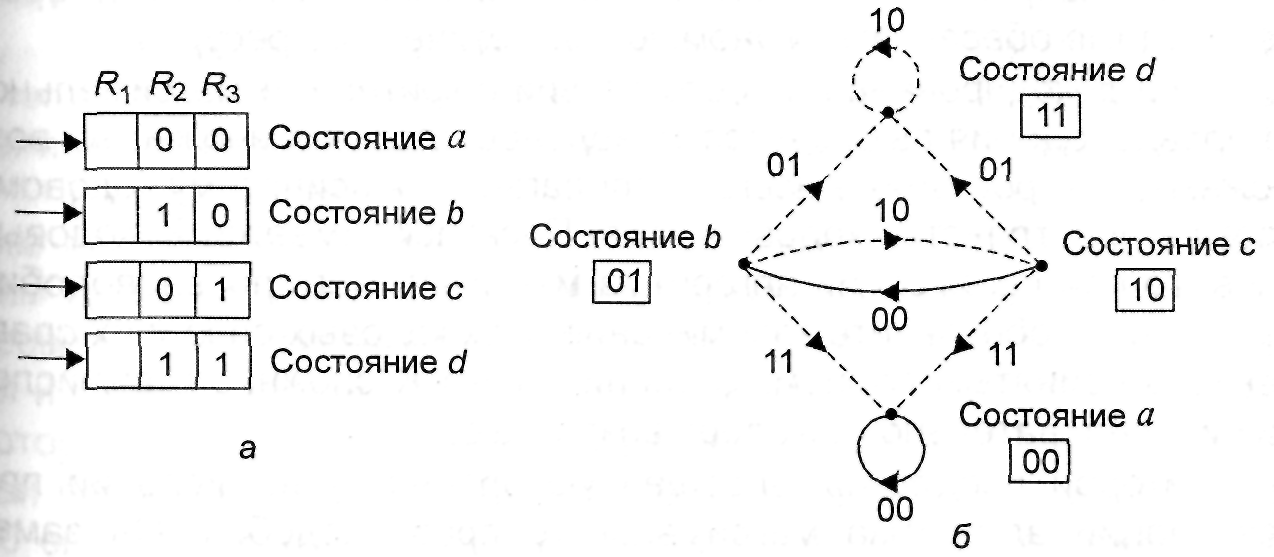
Рис.
3.6. Диаграмма состояний для кодера,
изображенного на рис. 3.4
Другим
полезным способом описания кодового
дерева является решетчатая диаграмма,
изображенная на рис. 3.7. Диаграмма берет
начало из состояния а и на ней
отображаются все возможные переходы
при поступлении на вход очередного
символа. Сплошным линиям соответствуют
переходы, происходящие при поступлении
символа 1 пунктирным – символа 0. При
поступлении на вход двух символов кодер
оказывается в одном из четырех состояний:
a, b,
c или d.
Заметим, что решетчатая диаграмма имеет
повторяющийся характер и может быть
легко построена с помощью диаграммы
состояний.
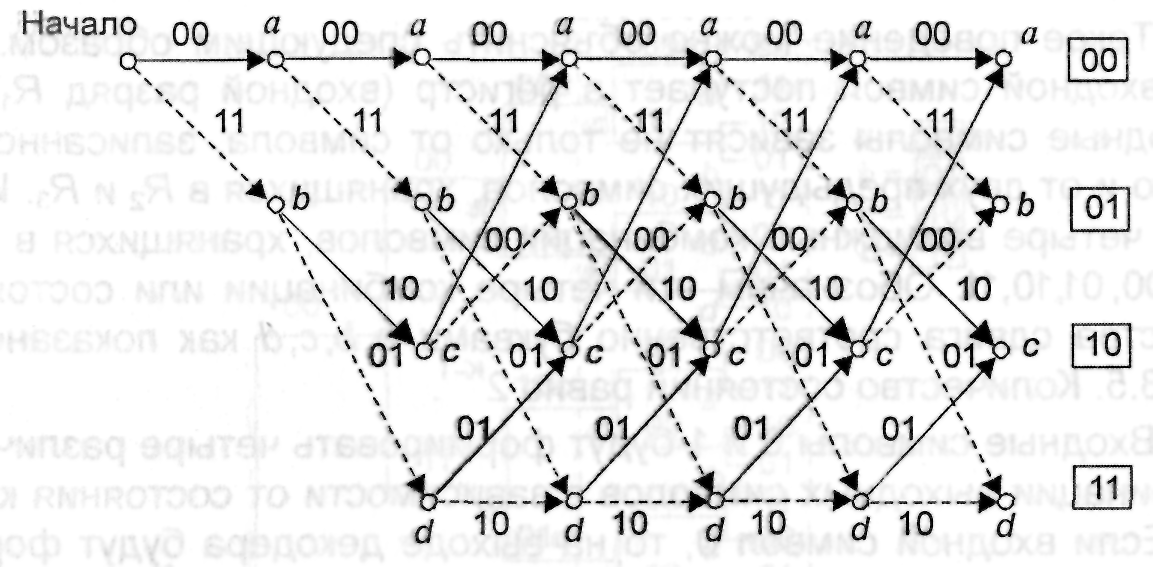
Рис.
3.7. Решетчатая диаграмма для кодера,
изображенного на рис.3.4
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
26.02.2016541.64 Кб16Сертификат Реконструкция жизни.PDF
- #
- #
- #
- #
- #
- #
6.1. Определения коэффициента ошибок
6.2. Математическое выражение коэффициента битовых ошибок
6.3. Нормы на параметры ошибок систем передачи
6.4. Принципы построения измерителей ошибок
6.5. Техника измерения коэффициента ошибок
6.1. Определения коэффициента ошибок
Коэффициент ошибок – важнейшая характеристика линейного тракта. Он измеряется как для отдельных участков регенерации, так и для тракта в целом. Определяется коэффициент ошибок kОШ, по формуле:
kОШ = NОШ /N, (6.1)
где N – общее число символов, переданных за интервал измерения; NОШ – число ошибочно принятых символов за интервал измерения.
Измерение коэффициента ошибок носит статистический характер, так как получаемый за конечное время результат является случайной величиной. Относительную погрешность измерения в случае нормального закона распределения числа ошибок, что допустимо при N≥10, можно определить по формуле:
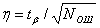 . (6.2)
. (6.2)
Здесь ![]() — коэффициент, зависящий от доверительной вероятности результата измерений:
— коэффициент, зависящий от доверительной вероятности результата измерений:
![]() , (6.3)
, (6.3)
где ![]() — обратная функция интеграла вероятности
— обратная функция интеграла вероятности ![]() :
:
![]() . (6.4)
. (6.4)
Значение kОШ позволяет оценивать вероятность ошибки pОШ – количественную оценку помехоустойчивости. Область возможных значений оценки, в которой с заданной доверительной вероятностью будет находиться значение pОШ, определяется верхней (pВ) и нижней (pН) доверительными границами. При нормальном законе распределения числа ошибок значения pВ и pН определяются по формулам:
![]() , (6.5)
, (6.5)
![]() , (6.6)
, (6.6)
Очевидно, что точность оценок вероятности ошибки и коэффициента ошибки растет с увеличением N. Общее число символов цифрового сигнала, переданных за интервал измерения T, зависит от скорости передачи B: N = TB. Отсюда следует, что чем больше скорость передачи, тем быстрее и точнее можно оценить коэффициент ошибок.
6.2. Математическое выражение коэффициента битовых ошибок
Определим коэффициент битовых ошибок для реальных приёмников, которым свойственно наличие различных источников шумов. При этом будем считать, что приёмник принимает решение, какой бит (0 или 1) был передан в каждом битовом интервале путем стробирования фототока. Очевидно, что из-за наличия шумов данное решение может быть неверным, что приводит к появлению ошибочных битов. Поэтому, чтобы определить коэффициент битовых ошибок, необходимо понять, каким образом приемник принимает решение относительно переданного бита.
Обозначим через I1 и I0 фототоки, стробированные приемником в течение 1 и 0 битов, соответственно, а через s12 и s02 соответствующие шумы. Принимая, что последние имеют гауссовское распределение, проблема установления истинного значения принятого бита имеет следующую математическую формулировку. Фототок для битов 1 и 0 является выборкой гауссовской переменной со средним значением I1 и вариацией s1, а приёмник должен отслеживать этот сигнал и решать, является ли переданный бит 0 или 1. При этом существует много возможных правил принятия решения, которые могут быть реализованы в приёмнике с целью минимизации коэффициента битовых ошибок. Для значения фототока I этим оптимальным решением является наиболее вероятное значение переданного бита, которое определяется путём сравнения текущего значения фототока с пороговым значением Iп, используемым для принятия решения.
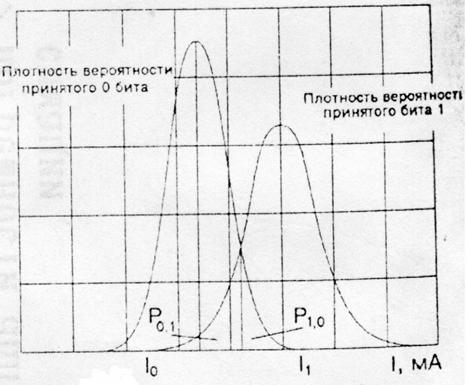
Рисунок 6.1. Функция плотности вероятности фототока принятых сигналов
Пусть при I ³ Iп принимается решение о том, что был передан бит 1, в противном случае – бит 0. Когда биты 1 и 0 равновероятны, что и рассматривается в дальнейшем, пороговый ток приблизительно равен:
![]() (6.7)
(6.7)
Геометрически Iп представляет собой значение тока I, для которого две кривые плотности вероятностей (рис. 6.1) пересекаются.
Вероятность того, что I < Iп, т. е. вероятность ошибки при передаче бита 1, обозначим через Р0,1, а вероятность решения для переданного бита 1, когда I ³ Iп при переданном 0, обозначим Р1,0.
Пусть Q(х) обозначает вероятность того, что нулевая средняя вариация гауссовской переменной превышает значение х, тогда:
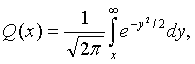 (6.8)
(6.8)
а
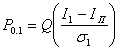 (6.9)
(6.9)
а
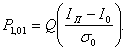 (6.10)
(6.10)
Можно показать [14], что BER определяется,
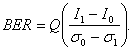 (6.11)
(6.11)
Очень важно отметить, что в ряде случаев эффективным является использование изменяемого в зависимости от уровня сигнала порога принятия решения, как, например, шума оптического усилителя. Многие высокоскоростные приёмники обладают такой особенностью. Однако более простые приемники имеют порог, соответствующий среднему уровню принимаемого тока, а именно (I1 + I0)/2. Такая настройка порогового значения дает большой коэффициент битовых ошибок, определяемый выражением [14].
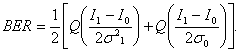 (6.12)
(6.12)
Выражение (6.11) можно использовать для оценки BER, когда известны как мощность полученного сигнала, соответствующего битам 0 и 1, так и статистика шумов.
6.3. Нормы на параметры ошибок систем передачи
Битовые ошибки являются основным источником ухудшения качества связи, проявляющегося в искажении речи в телефонных каналах, недостоверности передачи информации или снижении пропускной способности передачи данных, и характеризуются статистическими параметрами и нормами на них, которые определены соответствующей вероятностью выполнения этих норм. Последние делятся на долговременные и оперативные нормы, первые из которых определяются рекомендациями ITU-T G.821 и G.826, а вторые – М.2100, М.2110 и М.2120, при этом, согласно М.2100, качество цифрового тракта по критерию ошибок делят на три категории:
- нормальное – BER < 10-6;
- пониженное – 10-6 ≤ BER < 10-3 (предаварийное состояние);
- неприемлемое – BER ≥ 10-3 (аварийное состояние).
Так как появление ошибок является следствием совокупности всех текущих условий передачи цифровых сигналов, имеющих случайный характер, то при отсутствии данных о законе распределения ошибок его отдельные элементы могут быть определены с определенной степенью достоверности только по результатам продолжительных измерений. В то же время на практике необходимо, чтобы значения параметров ошибок для ввода в эксплуатацию и технического обслуживания систем передачи основывались на достаточно коротких интервалах времени измерения. Исходя из этого, были определены следующие параметры ошибок [14]:
- секунда с ошибками (error second, ES) – односекундный интервал, содержащий хотя бы один ошибочный бит;
- секунда, пораженная ошибками (severely error second, SES) – односекундный интервал с BER ≥ 10-3.
Данные параметры ошибок должны оцениваться в течение времени готовности (available time), отсчет которого начинается с первой секунды из десяти следующих друг за другом секунд, в каждой из которых BER<10-3. ITU-T M.2100 регламентирует нормы качества (performance objectives, PO) на выраженные максимальным процентом времени параметры ошибок, которые зависят только от скорости передачи и приводятся для условного эталонного соединения (hypothetical reference connection, HRC/HRX/) длиной 27500 км. При этом нормы качества распределяются по участкам соединения соответствующей категории качества. В качестве эталонной модели такого распределения принимается участок высокой категории качества протяженностью 25000 км, которому присваивается 40% от общей нормы качества на параметры ошибок передачи точка-точка, что в пересчете на 1 км, дает 0.0016 %/км.. Остальные 4 участка (2 среднего качества и 2 с приемлемым качеством) длиной 2 х 1250 км расположены по обе стороны от центрального. Поэтому распределение, пропорциональное протяженности L км тракта высокой категории качества, будет определяться, как
AL = 0.0016 · L %/км. (6.13)
Нормы качества на цифровые тракты и каналы подразделяются на настроечные и эксплуатационные, причем вводимые в эксплуатацию впервые или после проведения корректирующих действий они должны сдаваться по настроечным нормам качества, а в процессе эксплуатации должны соответствовать эксплуатационным нормам. Обычно [105] эксплуатационная норма представляется в виде эталонной нормы качества (reference performance objective, RPO)
RPO = A · T · PO, (6.14)
а настроечная, включающая запас на старение, используемая при вводе в эксплуатацию (bringing into service objective, BISO), определяется, как половина RPO, т.е.
BISO = RPO/2. (6.15)
Здесь PO – норма качества оцениваемого параметра, а T = 86400 с (одни сутки) – продолжительность измерений (количество односекундных интервалов).
Для анализа результатов, полученных в процессе измерений, используются также предельные значения S1и S2 норм (рисунок 6.2), которые соответствуют числу событий (ES,SES) и определяются, как:
S1 = RPO/2 – D и S2 = RPO/2 + D, (6.16)
где D = 2![]() — дисперсия оцениваемого параметра.
— дисперсия оцениваемого параметра.
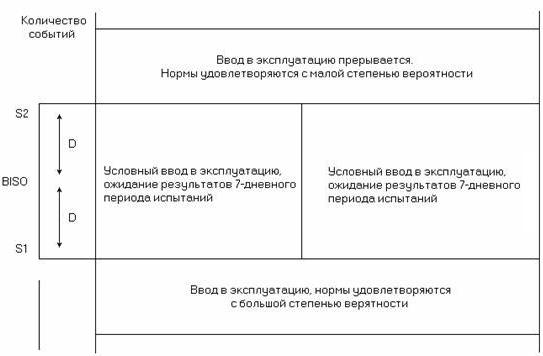
Рисунок 6.2. Предельные значения и условия ввода в эксплуатацию системы передачи
При соответствии результатов измерений норме S1 цифровой тракт может быть введен в эксплуатацию без всякого сомнения, а при превышении нормы S2 в обязательном порядке требуется повышение качества испытываемого цифрового тракта, т.е. должны быть проведены корректирующие действия с повторными измерениями. Если значение ES или SES лежит в интервале от S1 до S2, цифровой тракт может быть введен в эксплуатацию условно или временно с продолжением измерений в течение 7 суток. Данный подход к оценке качества цифровых систем передачи по параметрам ошибок позволяет сократить время измерений и получить норму цифрового тракта суммированием норм цифровых участков. При этом значения RPO, D, S1 и S2 выражаются в виде числа событий за установленный интервал времени, а не в виде процентов времени.
Для измерения коэффициента ошибок разработан ряд специальных BER анализаторов – измерителей коэффициента ошибок, включающих генераторы псевдослучайных и детерминированных последовательностей передаваемых кодированных символов, а также приемное оборудование, осуществляющее собственно измерение коэффициента ошибок. В случае посимвольного сравнения кодов измерение может быть выполнено с использованием шлейфа, т.е. путем измерения ошибок с одной оконечной станции при установке на противоположном конце шлейфа. Другой метод основан на выделении ошибок благодаря избыточности используемых кодов и используется для измерений от передающей до приемной сторон тракта или участка линии, т.е. когда выделение и фиксация ошибок производятся на ее приемном конце. Очевидно, что в первом случае требуется использование одного комплекта, а во втором – двух комплектов приборов. При этом измеренное значение коэффициента ошибок отражает качество передачи при прохождении сигнала в обоих направлениях и в каждом направлении соответственно.
6.4. Принципы построения измерителей ошибок
В зависимости от скорости передачи контролируемой системы передачи в анализаторе используются различные схемотехнические решения.
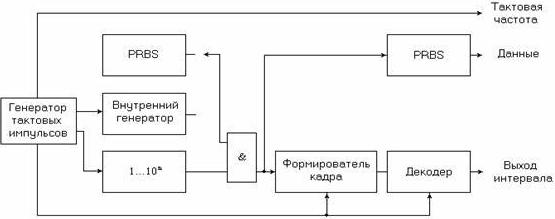
Рисунок 6.3. Генератор низкоскоростного BER анализатора
Низкоскоростной генератор тестовых кодов и детектор ошибок. Используемый в телекоммуникациях анализатор BER, состоящий [106] из генератора тестовых кодов и собственно анализатора ошибок, представлен на рисунках 6.3 и 6.4. Он предназначен для невысоких (до 200 Мбит/с) битовых скоростей, учитывая, что максимальные типовые скорости составляют 44.736 Мбит/с (DS3) в Северной Америке и 139.364 Мбит/с – за пределами Северной Америки.
PRBS с генератором кодовых групп, представленный на рис. 6.16, синхронизируется либо от источника тактового сигнала с фиксированной частотой (согласно G.703), либо от синтезатора, осуществляя тем самым изменение частоты синхронизации. В связи с этим использование данных средств требует задания некоторых определенных частот синхронизации и наличия возможности обеспечения их небольших смещений от ±15 до ±50 ppm. Для повторения тестовых кодов схема PRBS и генератор кодовых групп обычно имеют триггерную схему, управляющую либо выходным усилителем бинарных данных, который обеспечивает данные и данные с сопровождающим синхросигналом, либо выходную схему кодированных данных. Это позволяет создавать цикловую синхронизацию сигнала в соответствии с требованием, например, системы SONET/SDH. Кроме этого, данная схема способствует созданию соответствующего интерфейсного кода для эффективного восстановления тактовой синхронизации. Выходной усилитель обеспечивает необходимый уровень сигнала в соответствии со спецификацией электрического интерфейса, в том числе сигнала с чередованием полярности импульсов.
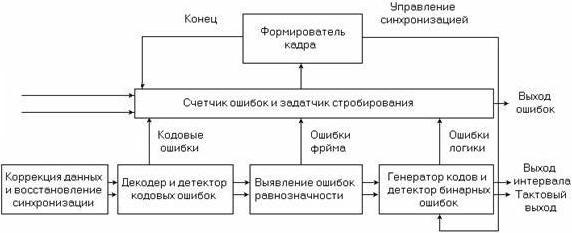
Рисунок 6.4. Низкоскоростной детектор ошибок
Детектор ошибок, показанный на рисунке 6.4, получает стандартный кодированный сигнал, восстанавливает генератор синхросигнала и устраняет кодирование для обеспечения бинарной даты и синхросигналов. Он обнаруживает любые нарушения алгоритма интерфейсного кода и посылает сигналы на счетчик ошибок, что составляет первый уровень процесса обнаружения ошибок. При работе с цикловыми сигналами приемник захватывает любой присутствующий элемент цикловой синхронизации, проверяет наличие цикловых ошибок и декодирует любые встроенные сигналы тревоги, или CRC биты, тем самым обеспечивая возможность измерения.
Наконец, бинарные данные и синхросигнал направляются на детектор ошибок и генератор эталонных тестовых кодов, которые проверяют полученный тестовый код бит за битом на предмет обнаружения логических ошибок. Временная база контролирует пропускание измерения для непрерывного, периодического и ручного режима. Накопленное количество ошибок обрабатывается для получения значения BER и анализа функционирования при наличии ошибок.
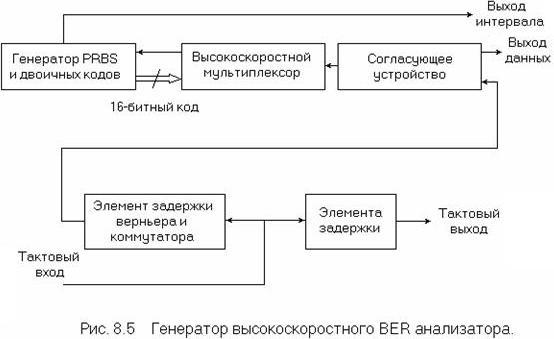
Высокоскоростной генератор тестовых кодов и детектор ошибок. На рисунках 6.5 и 6.6 показаны схемы [14] для 3 Гбит/с генератора тестовых кодов и детектора ошибок. Вследствие высокой битовой скорости генерация последовательных PRBS и кодовых групп на этой скорости не представляется целесообразной. Поэтому тестовые коды генерируются (рисунок 6.5) как параллельные 16-битные кодовые группы при максимальной скорости 200 Мбит/с, используя затем выполненные по биполярной технологии регистраторы смещения и высокоемкостную память. Высокоскоростные схемы обычно выполняются на основе арсенид-галлиевых логических схем, преобразующих параллельные данные в последовательный поток на скорости до 3 Гбит/с.
Согласно данной схеме, вход синхросигнала генерируется синтезатором частоты, согласующее устройство управляется через линию фиксированной задержки, а генератор тестовых кодов и выходной усилитель синхронизируются через схему дискретной и плавно изменяемой задержки, так что фаза синхросигнала/данных может изменяться как в положительном направлении, так и в отрицательном. Дискретные значения задержки составляют 250, 500 и 1000 пс, тогда как диапазон плавной задержки лежит в пределах от 0 до 250 пс с 1 пс инкрементом.
Корректор временной диаграммы, связанный с выходным усилителем, пересинхронизирует данные через триггер D типа для поддержания минимального фазового дрожания. Так как подобный тип тестового устройства обычно используется при проведении лабораторных измерений, выходные уровни синхросигнала и данных и постоянные смещения могут варьироваться для того или иного конкретного случая использования.
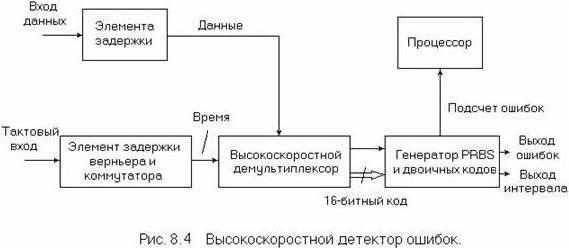
Детектор ошибок, показанный на рис. 6.6, имеет простое параллельное соединение, в связи с чем входы синхросигнала и данных проходят через схемы дискретной и плавной задержки, обеспечивая оптимальную настройку при обнаружении ошибок для любой фазы синхросигнала/данных. Действительно, путем настройки под контролем внутреннего процессора решающего порога и фазы синхросигнала условия функционирования детектора ошибок могут быть оптимизированы автоматически. Высокоскоростной демультиплексор преобразует последовательный поток данных в 16-битные параллельные кодовые группы наряду с поделенным на 16 синхросигналом. Параллельно соединенный генератор эталонных тестовых кодов синхронизируется с входными данными и осуществляет сравнение битов, поэтому любая ошибка фиксируется одним из двух счетчиков, первый из которых подсчитывает число ошибок, а второй – общее число битов. Процессор измерения обеспечивает анализ функционирования при наличии ошибок с разрешением до 1 мс.
6.5. Техника измерения коэффициента ошибок
Рассмотрим измерение коэффициента ошибок путем посимвольного сравнения и подсчета ошибочно принятых элементарных импульсов. Для этого вначале (перед измерением) на передающей станции с помощью оптического аттенюатора устанавливают заданный в технических условиях на аппаратуру линейного тракта уровень оптического излучения. Затем на передающем конце подключают генератор испытательных сигналов, а на приемном – измеритель коэффициента ошибок и, изменяя значения уровней средней мощности, измеряют коэффициент ошибок. Время измерения определяют в зависимости от скорости передачи, объема информации и значений коэффициента ошибок Кошi (BERi).
Коэффициент ошибок при заданном уровне оптического излучения вычисляют по формуле [14]
![]() (6.17)
(6.17)
где
![]() ,
, 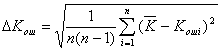 , (6.18)
, (6.18)
где ![]() и
и ![]() — погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
— погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
Для определения выражения СВО на бит информации предполагаем,
что станция шумовых помех в части полосы с ограниченной мощностью ![]() равномерно распределенной в
равномерно распределенной в
пределах участка полосы ![]() ,
, ![]() , одновременно подавляет
, одновременно подавляет ![]() смежных частотных каналов с
смежных частотных каналов с
вероятностью ![]() и
и
не подавляет — с вероятностью ![]() .
.
Принятая энергия сигнала на информационный бит составляет
величину ![]() , где
, где ![]() — мощность сигнала;
— мощность сигнала; ![]() — длительность бита; тогда
— длительность бита; тогда
энергия одного кодированного ![]() -ичного слова может быть записана в виде:
-ичного слова может быть записана в виде:
![]()
![]()
![]() (5.25)
(5.25)
Энергия, соответствующая одной частотной составляющей
кодового слова, может быть выражена формулой
![]() (5.26)
(5.26)
Если принять, что станцией шумовых помех в части полосы
подавляется ![]() частотных
частотных
составляющих кодового слова из общего числа ![]() , образующих одно
, образующих одно ![]() -ичное кодовое слово
-ичное кодовое слово ![]() , то вероятность того, что принятое кодовое слово
, то вероятность того, что принятое кодовое слово ![]() будет ошибочным,
будет ошибочным,
может быть определена из неоднократно используемого ранее выражения
![]() (5.27)
(5.27)
где ![]() — УВО на бит при подавлении
— УВО на бит при подавлении ![]() частотных элементов сигнала из
частотных элементов сигнала из
общего числа![]() .
.
Условная вероятность ошибки демодулятора с АРУ при ![]() -ичном кодировании
-ичном кодировании ![]() может быть
может быть
представлена выражением (5.5), в котором параметр нецентральности статистики
частотного канала, содержащего сигнал, имеет вид:
 (5.28)
(5.28)
![]()
Демодулированные ![]() -ичные слова перед поступлением на вход
-ичные слова перед поступлением на вход
декодера преобразуются в ![]() -ичные символы. А это, в свою очередь,
-ичные символы. А это, в свою очередь,
требует установления взаимосвязи между условной вероятностью ошибки в ![]() -ичном кодовом слове
-ичном кодовом слове ![]() на выходе демодулятора с
на выходе демодулятора с
вероятностью ошибки в ![]() -ичном символе на входе декодера
-ичном символе на входе декодера ![]() .
.
Для решения этой задачи необходимо
предположить, что отношение
![]()
представляет собой целое число, т.е. целое число ![]() -ичных слов
-ичных слов
преобразуется в один ![]() -ичиый
-ичиый
символ или наоборот. Эта ситуация требует рассмотрения двух случаев: ![]() и
и ![]() .
.
В первом случае, если ![]() , то
, то ![]()
![]() -ичных слов преобразуется в
-ичных слов преобразуется в ![]() -ичный символ. Практическим
-ичный символ. Практическим
примером данного варианта является использование 8-ичной ЧМ (![]() ) для передачи выходного
) для передачи выходного
сигнала, кодированного кодом Рида-Соломона (63,32), для которого ![]() (
(![]() ). В этом случае каждый
). В этом случае каждый
кодированный 64-ичный символ преобразуется в два 8-ичных слова для передачи с
использованием 8-ичной ЧМ.
В приемном устройстве на выходе демодулятора ![]() -ичный символ будет
-ичный символ будет
ошибочным, если одно или несколько из ![]() -ичных слов будут ошибочными.
-ичных слов будут ошибочными.
Следовательно, вероятность ошибки в символе будет определяться выражением [15]
![]() ,
, ![]() —
—
целое (5.29)
Во втором случае, при ![]() кодированных
кодированных ![]() -ичный символов
-ичный символов
образуют одно ![]() -ичное
-ичное
слово, предназначенное для передачи. При этом, необходимо использовать
перемежение, чтобы поддержать независимость ошибок в символах в пределах кодового
слова.
В общем случае в приемном устройстве, при ![]() , из
, из ![]() слов, состоящих из
слов, состоящих из ![]()
![]() -ичных символов,
-ичных символов, ![]() , будет иметь место один и тот же
, будет иметь место один и тот же ![]() -ичный символ в любой заданной кодовой позиции.
-ичный символ в любой заданной кодовой позиции.
Следовательно, если в слове имеется ошибка, то вероятность
появления ошибки в символе в любой заданной позиции вычисляется по формуле [15]
![]() (5.30)
(5.30)
На основе изложенного, а также учитывая, что![]() , СВО в символе
, СВО в символе ![]() может быть представлена
может быть представлена
выражением
![]()
![]() — целое (5.31)
— целое (5.31)
В частном случае при ![]() , (двоичный кодер) выражение (5.31)
, (двоичный кодер) выражение (5.31)
принимает вид известного уравнения для вероятности ошибки при преобразовании ![]() -ичной системы в
-ичной системы в
двоичную систему с ортогональными сигналами [39]
![]() .
.
Для оценки влияния кодирования на помехоустойчивость
СРС рассмотрим использование блоковых кодов, в которых последовательность
элементарных сообщений источника разбивается на отрезки, каждый из которых
преобразуется в определенную последовательность (блок) кодовых символов. При
этом закодированная последовательность становится последовательностью независимых
кодовых слов одинаковой длины. Для декодера двоичною блокового кода ![]() , на вход которого
, на вход которого
поступают ![]() -ичные
-ичные
кодированные символы, а на выходе формируются ![]() -кратные декодированные
-кратные декодированные ![]() -ичные информационные
-ичные информационные
символы, вероятность ошибки при декодировании с жестким решением в ![]() -ичном символе
-ичном символе
определяется из приведенного выше выражения (2.78)
![]() (5.32)
(5.32)
где ![]() — минимальное расстояние между
— минимальное расстояние между
кодовыми словами; ![]() —
—
максимальное число поддающихся исправлению ошибок в символах на одно кодовое
слово.

13
период выходной последовательности всегда8 в два раза больше периода входной!
Расчет вероятности битовой ошибки
Перейдем теперь к расчету вероятности ошибки на выходе дифференциального декодера. Вероятность ошибки на входе декодера считается заданной, и определяется каналом передачи информации.
Пусть ошибки в канале независимые и происходят с вероятностью p . Тогда дифференциальный кодер, канал и декодер в эквиваленте дадут канал с памятью, т. е. такой канал, ошибки в котором — зависимые. Канал с памятью может быть описан с помощью следующей модели, рис. 2.
Рис. 2 Модель канала с памятью
Такой канал полностью вероятностей
Здесь буквой «П» обозначено событие «правильный прием», буквой «О» — «ошибочный прием». Обозначение PП/О означает «вероятность правильного приема при условии, что предыдущий прием был ошибочным». Эта вероятность является условной. Зависимость вероятности от условия является признаком наличия памяти в канале. определяется матрицей условных (переходных)
|
P= |
PП/П |
PП/О |
. |
(9) |
|
PО/О) |
||||
|
(PО/П |
Обратите внимание, что буквам «П» и «О» слева соответствует момент времени tn−1 , а таким же буквам справа — tn . Время — это неотъемлемая черта каналов с памятью. Говорят, «канал помнит несколько предыдущих состояний», и эти состояния влияют на вероятность текущего состояния.
Систему «дифференциальный кодер, канал и декодер» удобно рассматривать как некоторый цифровой автомат, на выходе которого в каждый момент времени либо правильный прием, либо — ошибочный; жизнь такого автомата описывается некоторой последовательностью букв
8 За исключением случая когда числитель Y (z) сокращает знаменатель K (z ) , — в этом случае период не меняется
(матрице переходных вероятностей)
(т. е. в канале с независимыми
14
… О П П П П П О О П П П …
Цель нашего повествования — вычислить вероятность ошибки на выходе дифференциального декодера, которая в рамках принятых обозначений
|
соответствует событию «О» и обозначается |
как PО |
. Эта вероятность будет |
|
зависеть от вероятностей перехода PX/X , |
которых, |
по сути, всего две, т. к. |
|
оставшиеся две являются дополнениями до единицы. |
Всякая вероятность есть предельная величина, определяемая по бесконечному количеству событий, поэтому чтобы определить PО требуется выписать всю «линию жизни» автомата и подсчитать долю букв «О» относительно общего количества букв; практически это сделать невозможно, а вот в уме — возможно, чем мы и займемся.
Предположим, что автомат начал жить, и его жизнь кратна дням, т. е. каждый день выпадает буква, «О» или «П». Какова вероятность того, что в первый день жизни произойдет ошибочный прием «О»? Эту вероятность логично приравнять к вероятности ошибки в канале без памяти
ошибками), PО 1 =p . Во второй день могут выпасть буквы либо «О», либо «П». Соответствующие вероятности вычисляются вполне однозначно по матрице канала
(PPПО)2 =(PPП/ПО/П PPП/ОО/О)(PPПО)1 ,
и так далее. Логика данного уравнения основана на формуле умножения и сложения вероятностей.
Упражнение: распишите матричное уравнение в виде системы линейных алгебраических уравнений, и поразмыслите над смыслом умножения и сложения вероятностей.
Пусть теперь уже прошло очень много дней жизни автомата… В этом случае вероятности PО n и PП n должны сходиться к искомым безусловным вероятностям PО и PП
|
PП n+1 ≈ PП n |
, |
lim |
PП n = PП |
. |
(10) |
|
|
(PО) |
(PО) |
n→∞ |
(PО) (PО) |
Тогда справедливо предельное равенство

15
(PPПО)=(PPП/ПО/П PPП/ОО/О)(PPПО) ,
из которого однозначно определяются искомые вероятности
|
PО= |
PО/П |
, |
PП=1−PО= |
PП/О |
. |
(11) |
|
|
PП/О +PО/П |
PО/П+PП/О |
||||||
|
Остается понять как |
переходные вероятности |
зависят |
от вероятности |
ошибки p в канале без памяти, и цель данного повествования будет достигнута.
Предположим для наглядности, что передаются одни нули, тогда единицы будут указывать на ошибки Рассмотрим все возможные комбинации канальных ошибок на входе дифференциального декодера. Разделим рассмотрение на четыре части, согласно матрице переходных вероятностей (9).
I. Правильный прием в предыдущем и текущем битах, PП/П :
1 1 1, декодируем как 0 0,
0 0 0, декодируем как 0 0,
(1 + 1 = 0, 1 + 1 = 0),
(0 + 0 = 0, 0 + 0 = 0).
Вероятность этого события равна PП/П=p2 +(1−p)2 .
Замечание: здесь и далее первый бит (вспомогательный), который не выделен жирным шрифтом, не влияет на вероятность, потому что перебираются все его возможные значения, 0 и 1; следующие два бита полностью определяются значением вспомогательного и поставленным ограничивающим условием.
II. Ошибочный прием в предыдущем бите и правильный — в текущем, PП/О : 0 1 1, декодируем как 1 0, (0 + 1 = 1, 1 + 1 = 0), 1 0 0, декодируем как 1 0, (1 + 0 = 1, 0 + 0 = 0).
Вероятность этого события равна PП/О=p2 +(1−p)2 . III.Ошибочный прием в предыдущем и текущем битах, PО/О :
0 1 0, декодируем как 1 1, (0 + 1 = 1, 1 + 0 = 1), 1 0 1, декодируем как 1 1, (1 + 0 = 1, 0 + 1 = 1).
Вероятность этого события равна PО/О= p(1−p)+(1−p) p=2 p(1− p) .
16
IV.Правильный прием в предыдущем и ошибочный — в текущем, PО/П : 0 0 1, декодируем как 0 1, (0 + 0 = 0, 0 + 1 = 1), 1 1 0, декодируем как 0 1, (1 + 1 = 0, 1 + 0 = 1).
|
Вероятность этого события равна |
PО/П=p(1−p)+(1− p) p=2 p(1−p) . |
||
|
Подставим найденные переходные вероятности в (11) и получим |
|||
|
окончательный результат |
|||
|
PО=2 p(1−p) , |
PП= p2 +(1−p)2 . |
(12) |
|
|
Таким образом, вероятность ошибки на выходе дифференциального |
|||
|
декодера почти в два раза превышает канальную вероятность ошибки p |
; этот |
||
|
результат тем точнее, чем лучше |
канал, |
т. е. чем меньше p . Данный |
факт |
объясняется достаточно просто: при малых p ошибки происходят изредка и, в основном, по одиночке, а из логики дифференциального декодирования следует, что одна одиночная ошибка после декодирования трансформируется в две.
Любопытно также отметить, что если в канале вероятность ошибки равна ½, то после дифференциального декодирования вероятность ошибки остается той же!
4.7.1. Вероятность появления ошибочного бита при когерентном обнаружении сигнала BPSK
4.7.2. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в дифференциальной модуляции BPSK
4.7.3. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
4.7.4. Вероятность появления ошибочного бита при некогерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
4.7.5. Вероятность появления ошибочного бита для бинарной модуляции DPSK
4.7.6. Вероятность ошибки для различных модуляций
4.7.1. Вероятность появления ошибочного бита при когерентном обнаружении сигнала BPSK
Важной мерой производительности, используемой для сравнения цифровых схем модуляции, является вероятность ошибки, РЕ Для коррелятора или согласованного фильтра вычисление РЕ можно представить геометрически (см. рис. 4.6). Расчет РЕ включает нахождение вероятности того, что при данном векторе переданного сигнала, скажем si вектор шума n выведет сигнал из области 1. Вероятность принятия детектором неверного решения называется вероятностью символьной ошибки, рE. Несмотря на то что решения принимаются на символьном уровне, производительность системы часто удобнее задавать через вероятность битовой ошибки (Ps). Связь РВ и РЕ рассмотрена в разделе 4.9.3 для ортогональной передачи сигналов и в разделе 4.9.4 для многофазной передачи сигналов.
Для удобства изложения в данном разделе мы ограничимся когерентным обнаружением сигналов BPSK. В этом случае вероятность символьной ошибки — это то же самое, что и вероятность битовой ошибки. Предположим, что сигналы равновероятны. Допустим также, что при передаче сигнала ![]() принятый сигнал r(t) равен
принятый сигнал r(t) равен ![]() , где n(t) — процесс AWGN; кроме того, мы пренебрегаем ухудшением качества вследствие введенной каналом или схемой межсимвольной интерференции. Как показывалось в разделе 4.4.1, антиподные сигналы
, где n(t) — процесс AWGN; кроме того, мы пренебрегаем ухудшением качества вследствие введенной каналом или схемой межсимвольной интерференции. Как показывалось в разделе 4.4.1, антиподные сигналы ![]() и
и ![]() можно описать в одномерном сигнальном пространстве, где
можно описать в одномерном сигнальном пространстве, где
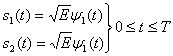 (4.74)
(4.74)
Детектор выбирает ![]() с наибольшим выходом коррелятора
с наибольшим выходом коррелятора ![]() ; или, в нашем случае антиподных сигналов с равными энергиями, детектор, используя формулу (4.20), принимает решение следующего вида.
; или, в нашем случае антиподных сигналов с равными энергиями, детектор, используя формулу (4.20), принимает решение следующего вида.
![]() (4.74)
(4.74)
Как видно из рис. 4.9, возможны ошибки двух типов: шум так искажает переданный сигнал ![]() , что измерения в детекторе дают отрицательную величину z(T), и детектор выбирает гипотезу H2, что был послан сигнал s2(t). Возможна также обратная ситуация: шум искажает переданный сигнал
, что измерения в детекторе дают отрицательную величину z(T), и детектор выбирает гипотезу H2, что был послан сигнал s2(t). Возможна также обратная ситуация: шум искажает переданный сигнал ![]() , измерения в детекторе дают положительную величину z(T), и детектор выбирает гипотезу Н1, соответствующую предположению о передаче сигнала
, измерения в детекторе дают положительную величину z(T), и детектор выбирает гипотезу Н1, соответствующую предположению о передаче сигнала ![]() .
.
В разделе 3.2.1.1 была выведена формула (3.42), описывающая вероятность битовой ошибки РB для детектора, работающего по принципу минимальной вероятности ошибки.
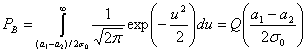 (4.76)
(4.76)
Здесь σ0 — среднеквадратическое отклонение шума вне коррелятора. Функция Q(x), называемая гауссовым интегралом ошибок, определяется следующим образом.
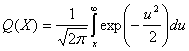 (4.77)
(4.77)
Эта функция подробно описывается в разделах 3.2 и Б.3.2.
Для передачи антиподных сигналов с равными энергиями, таких как сигналы в формате BPSK, приведенные в выражении (4.74), на выход приемника поступают следующие компоненты: ![]() , при переданном сигнале
, при переданном сигнале ![]() , и
, и ![]() , при переданном сигнале s2(t), где Еь — энергия сигнала, приходящаяся на двоичный символ. Для процесса AWGN дисперсию шума
, при переданном сигнале s2(t), где Еь — энергия сигнала, приходящаяся на двоичный символ. Для процесса AWGN дисперсию шума ![]() вне коррелятора можно заменить N0/2 (см. приложение В), так что формулу (4.76) можно переписать следующим образом.
вне коррелятора можно заменить N0/2 (см. приложение В), так что формулу (4.76) можно переписать следующим образом.
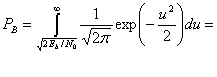 (4.78)
(4.78)
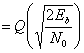 (4.79)
(4.79)
Данный результат для полосовой передачи антиподных сигналов BPSK совпадает с полученными ранее формулами для обнаружения антиподных сигналов с использованием согласованного фильтра (формула (3.70)) и обнаружения узкополосных антиподных сигналов с применением согласованного фильтра (формула (3.76)). Это является примером описанной ранее теоремы эквивалентности. Для линейных систем теорема эквивалентности утверждает, что на математическое описание процесса обнаружения не влияет сдвиг частоты. Как следствие, использование согласованных фильтров или корреляторов для обнаружения полосовых сигналов (рассмотренное в данной главе) дает те же соотношения, что были выведены ранее для сопоставимых узкополосных сигналов.
4.7.2. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в дифференциальной модуляции BPSK
Сигналы в канале иногда инвертируются; например, при использовании когерентного опорного сигнала, генерируемого контуром ФАПЧ, фаза может быть неоднозначной. Если фаза несущей была инвертирована при использовании схемы DPSK, как это скажется на сообщении? Поскольку информация сообщения кодируется подобием или отличием соседних символов, единственным следствием может быть ошибка в бите, который инвертируется, или в бите, непосредственно следующим за инвертированным. Точность определения подобия или отличия символов не меняется при инвертировании несущей. Иногда сообщения (и кодирующие их сигналы) дифференциально кодируются и когерентно обнаруживаются, чтобы просто избежать неопределенности в определении фазы.
Вероятность появления ошибочного бита при когерентном обнаружении сигналов в дифференциальной модуляции PSK (DPSK) дается выражением [5].
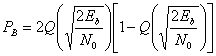 (4.80)
(4.80)
Это соотношение изображено на рис. 4.25. Отметим, что существует незначительное ухудшение достоверности обнаружения по сравнению с когерентным обнаружением сигналов в модуляции PSK. Это вызвано дифференциальным кодированием, поскольку любая отдельная ошибка обнаружения обычно приводит к принятию двух ошибочных решений. Подробно вероятность ошибки при использовании наиболее популярной схемы — когерентного обнаружения сигналов в модуляции DPSK — рассмотрена в разделе 4.7.5.
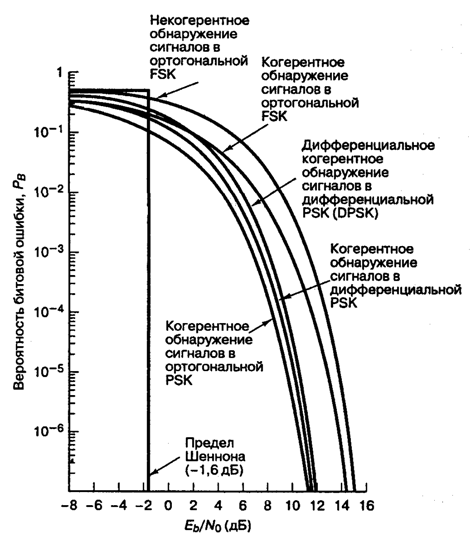
Рис. 4.25. Вероятность появления ошибочного бита для бинарных систем нескольких типов
4.7.3. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
Формулы (4.78) и (4.79) описывают вероятность появления ошибочного бита для когерентного обнаружения антиподных сигналов. Более общую трактовку для когерентного обнаружения бинарных сигналов (не ограничивающихся антиподными сигналами) дает следующее выражение для РВ [6].
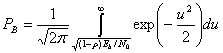 (4.81)
(4.81)
Из формулы (3.64,б) ![]() — временной коэффициент взаимной корреляций между
— временной коэффициент взаимной корреляций между ![]() и
и ![]() , где θ — угол между векторами сигналов
, где θ — угол между векторами сигналов ![]() и s2 (см. рис. 4.6). Для антиподных сигналов, таких как сигналы BPSK, θ = π, поэтому ρ = -1.
и s2 (см. рис. 4.6). Для антиподных сигналов, таких как сигналы BPSK, θ = π, поэтому ρ = -1.
Для ортогональных сигналов, таких как сигналы бинарной FSK (BFSK), θ = π/2, поскольку векторы ![]() и s2 перпендикулярны; следовательно, ρ = 0, что можно доказать с помощью формулы (3.64,а), поэтому выражение (4.81) можно переписать следующим образом.
и s2 перпендикулярны; следовательно, ρ = 0, что можно доказать с помощью формулы (3.64,а), поэтому выражение (4.81) можно переписать следующим образом.
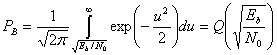 (4.82)
(4.82)
Здесь Q(x) — дополнительная функция ошибок, подробно описанная в разделах 3.2 и Б.3.2. Зависимость (4.82) для когерентного обнаружения ортогональных сигналов BFSK, показанная на рис. 4.25, аналогична зависимости, полученной для обнаружения ортогональных сигналов с помощью согласованного фильтра (формула (3.71)) и узкополосных ортогональных сигналов (униполярных импульсов) с использованием согласованного фильтра (формула (3.73)). В данной книге мы не рассматриваем амплитудную манипуляцию ООК (on-off keying), но соотношение (4.82 применимо к обнаружению с помощью согласованного фильтра сигналов ООК, так же как и к когерентному обнаружению любых ортогональных сигналов.
Справедливость соотношения (4.82) подтверждает и то, что разность энергий между ортогональными векторами сигналов ![]() и s2 с амплитудой
и s2 с амплитудой ![]() , как показано на рис. 3.10, б, равна квадрату расстояния между концами ортогональных векторов Ed = 2Eb. Подстановка этого результата в формулу (3.63) также дает формулу (4.82). Сравнивая формулы (4.82) и (4.79), видим, что, по сравнению со схемой BPSK, схема BFSK требует на 3 дБ большего отношения E/N0 для обеспечения аналогичной достоверности передачи. Этот результат не должен быть неожиданным, поскольку при данной мощности сигнала квадрат расстояния между ортогональными векторами вдвое (на 3 дБ) больше квадрата расстояния между антиподными векторами.
, как показано на рис. 3.10, б, равна квадрату расстояния между концами ортогональных векторов Ed = 2Eb. Подстановка этого результата в формулу (3.63) также дает формулу (4.82). Сравнивая формулы (4.82) и (4.79), видим, что, по сравнению со схемой BPSK, схема BFSK требует на 3 дБ большего отношения E/N0 для обеспечения аналогичной достоверности передачи. Этот результат не должен быть неожиданным, поскольку при данной мощности сигнала квадрат расстояния между ортогональными векторами вдвое (на 3 дБ) больше квадрата расстояния между антиподными векторами.
4.7.4. Вероятность появления ошибочного бита при некогерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
Рассмотрим бинарное ортогональное множество равновероятных сигналов FSK ![]() , определенное формулой (4.8).
, определенное формулой (4.8).
![]()
Фаза φ неизвестна и предполагается постоянной. Детектор описывается М = 2 каналами, состоящими, как показано на рис. 4.19, из полосовых фильтров и детекторов огибающей. На вход детектора поступает принятый сигнал r(t) = si(t) + n(t), где n(i) — гауссов шум с двусторонней спектральной плотностью мощности No/2. Предположим, что ![]() и
и ![]() достаточно разнесены по частоте, чтобы их перекрытием можно было пренебречь. Вычисление вероятности появления ошибочного бита для равновероятных сигналов
достаточно разнесены по частоте, чтобы их перекрытием можно было пренебречь. Вычисление вероятности появления ошибочного бита для равновероятных сигналов ![]() и
и ![]() начнем, как и в случае узкополосной передачи, с уравнения (3.38).
начнем, как и в случае узкополосной передачи, с уравнения (3.38).
 (4.83)
(4.83)
Для бинарного случая тестовая статистика z(T) определена как ![]() . Предположим, что полоса фильтра Wf равна 1/T, так что огибающая сигнала FSK (приблизительно) сохраняется на выходе фильтра. При отсутствии шума в приемнике значение z(T) равно
. Предположим, что полоса фильтра Wf равна 1/T, так что огибающая сигнала FSK (приблизительно) сохраняется на выходе фильтра. При отсутствии шума в приемнике значение z(T) равно ![]() при передаче s1(t) и —
при передаче s1(t) и —![]() — при передаче s2(t). Вследствие такой симметрии оптимальный порог γ0=0. Плотность вероятности
— при передаче s2(t). Вследствие такой симметрии оптимальный порог γ0=0. Плотность вероятности ![]() подобна плотности вероятности
подобна плотности вероятности ![]() .
.
![]() (4.84)
(4.84)
Таким образом, можем записать
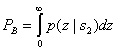 (4.85)
(4.85)
или
![]() (4.86)
(4.86)
где z1 и z2 обозначают выходы z1(T) и z2(T) детекторов огибающей, показанных на рис.4.19. При передаче тона ![]() , т.е. когда r(t) = s2(t) + n(t), выход z1(T) состоит исключительно из случайной переменной гауссового шума; он не содержит сигнального компонента. Распределение Гаусса в нелинейном детекторе огибающей дает распределение Релея на выходе [6], так что
, т.е. когда r(t) = s2(t) + n(t), выход z1(T) состоит исключительно из случайной переменной гауссового шума; он не содержит сигнального компонента. Распределение Гаусса в нелинейном детекторе огибающей дает распределение Релея на выходе [6], так что
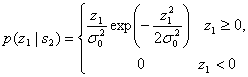 (4.87)
(4.87)
где ![]() — шум на выходе фильтра. С другой стороны, z2(T) имеет распределение Раиса, поскольку на вход нижнего детектора огибающей подается синусоида плюс шум [6]. Плотность вероятности p(z2s2) записывается как
— шум на выходе фильтра. С другой стороны, z2(T) имеет распределение Раиса, поскольку на вход нижнего детектора огибающей подается синусоида плюс шум [6]. Плотность вероятности p(z2s2) записывается как
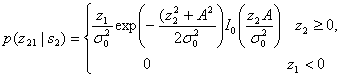 (4.88)
(4.88)
где ![]() и, как и ранее,
и, как и ранее, ![]() — шум на выходе фильтра. Функция 10(х), известная как модифицированная функция Бесселя первого рода нулевого порядка [7], определяется следующим образом.
— шум на выходе фильтра. Функция 10(х), известная как модифицированная функция Бесселя первого рода нулевого порядка [7], определяется следующим образом.
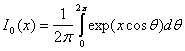 (4.89)
(4.89)
Ошибка при передаче s2(t) происходит, если выборка огибающей z1(T), полученная из верхнего канала (по которому проходит шум), больше выборки огибающей z2(T), полученной из нижнего канала (по которому проходит сигнал и шум). Таким образом, вероятность этой ошибки можно получить, проинтегрировав ![]() до бесконечности с последующим усреднением результата по всем возможным z2.
до бесконечности с последующим усреднением результата по всем возможным z2.
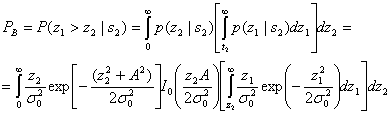 (4.91)
(4.91)
Здесь ![]() , внутренний интеграл — условная вероятность ошибки, при фиксированном значении z2, если был передан сигнал s2(1), а внешний интеграл усредняет условную вероятность по всем возможным значениям z2. Данный интеграл можно вычислить аналитически [8], и его значение равно следующему.
, внутренний интеграл — условная вероятность ошибки, при фиксированном значении z2, если был передан сигнал s2(1), а внешний интеграл усредняет условную вероятность по всем возможным значениям z2. Данный интеграл можно вычислить аналитически [8], и его значение равно следующему.
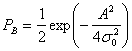 (4.92)
(4.92)
С помощью формулы (1.19) шум на выходе фильтра можно выразить как
![]() (4.93)
(4.93)
где ![]() a Wf — ширина полосы фильтра. Таким образом, формула (4.92) приобретает следующий вид.
a Wf — ширина полосы фильтра. Таким образом, формула (4.92) приобретает следующий вид.
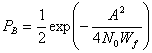 (4.94)
(4.94)
Выражение (4.94) показывает, что вероятность ошибки зависит от ширины полосы полосового фильтра и РB уменьшается при снижении Wf. Результат справедлив только при пренебрежении межсимвольной интерференцией (intersymbol interference — ISI). Минимальная разрешенная Wf (т.е. не дающая межсимвольной интерференции) получается из уравнения (3.81) при коэффициенте сглаживания г = 0. Следовательно, Wf= R бит/с =1/T, и выражение (4.94) можно переписать следующим образом.
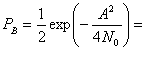 (4.95)
(4.95)
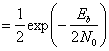 (4.96)
(4.96)
Здесь Еь= (1/2)А2Т — энергия одного бита. Если сравнить вероятность ошибки схем некогерентной и когерентной FSK (см. рис. 4.25), можно заметить, что при равных РB некогерентная FSK требует приблизительно на 1 дБ большего отношения Eb/N0, чем когерентная FSK (для РB < 10-4). При этом некогерентный приемник легче реализуется, поскольку не требуется генерировать когерентные опорные сигналы. По этой причине практически все приемники FSK используют некогерентное обнаружение. В следующем разделе будет показано, что при сравнении когерентной ортогональной схемы FSK с нёкогерентной схемой DPSK имеет место та же разница в 3 дБ, что и при сравнении когерентной ортогональной FSK и когерентной PSK. Как указывалось ранее, в данной книге не рассматривается амплитудная манипуляция ООК (on-off keying). Все же отметим, что вероятность появления ошибочного бита РB, выраженная в формуле (4.96), идентична РB для некогерентного обнаружения сигналов ООК.
4.7.5. Вероятность появления ошибочного бита для бинарной модуляции DPSK
Определим набор сигналов BPSK следующим образом.
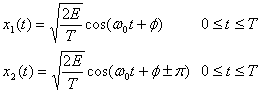 (4.97)
(4.97)
Особенностью схемы DPSK является отсутствие в сигнальном пространстве четко определенных областей решений. В данном случае решение основывается на разности фаз между принятыми сигналами. Таким образом, при передаче сигналов DPSK каждый бит в действительности передается парой двоичных сигналов.
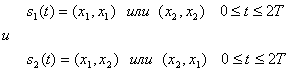 (4.98)
(4.98)
Здесь ![]() обозначает сигнал
обозначает сигнал ![]() , за которым следует сигнал
, за которым следует сигнал ![]() . Первые Т секунд каждого сигнала — это в действительности последние Т секунд предыдущего. Отметим, что оба сигнала s1(t) и s2(t) могут принимать любую из возможных форм и что
. Первые Т секунд каждого сигнала — это в действительности последние Т секунд предыдущего. Отметим, что оба сигнала s1(t) и s2(t) могут принимать любую из возможных форм и что ![]() и
и ![]() — это антиподные сигналы. Таким образом, корреляцию между
— это антиподные сигналы. Таким образом, корреляцию между ![]() и s2(t) для любой комбинации сигналов можно записать следующим образом.
и s2(t) для любой комбинации сигналов можно записать следующим образом.
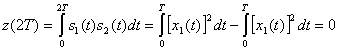 (4.99)
(4.99)
Следовательно, каждую пару сигналов DPSK можно представить как ортогональный сигнал длительностью 2Т секунд. Обнаружение может соответствовать некогерентному обнаружению огибающей с помощью четырех каналов, согласованных с каждым возможным выходом огибающей, как показано на рис. 4.26. Поскольку два детектора огибающей, представляющих каждый символ, обратны друг другу, выборки их огибающих будут совпадать. Значит, мы можем реализовать детектор как один канал для ![]() , согласовывающегося с
, согласовывающегося с ![]() или
или ![]() , и один канал для
, и один канал для ![]() , согласовывающегося с
, согласовывающегося с ![]() или
или ![]() , как показано на рис. 4.26. Следовательно, детектор DPSK сокращается до стандартного двухканального некогерентного детектора. В действительности фильтр может согласовываться с разностным сигналом; так что необходимым является всего один канал. На рис. 4.26 показаны фильтры, которые согласовываются с огибающими сигнала (в течение двух периодов передачи символа). Что это означает, если вспомнить, что DPSK — это схема передачи сигналов с постоянной огибающей? Это означает, что нам требуется реализовать детектор энергии, подобный квадратурному приемнику на рис. 4.18, где каждый сигнал в течение периода
, как показано на рис. 4.26. Следовательно, детектор DPSK сокращается до стандартного двухканального некогерентного детектора. В действительности фильтр может согласовываться с разностным сигналом; так что необходимым является всего один канал. На рис. 4.26 показаны фильтры, которые согласовываются с огибающими сигнала (в течение двух периодов передачи символа). Что это означает, если вспомнить, что DPSK — это схема передачи сигналов с постоянной огибающей? Это означает, что нам требуется реализовать детектор энергии, подобный квадратурному приемнику на рис. 4.18, где каждый сигнал в течение периода ![]() представляется синфазным и квадратурным опорными сигналами.
представляется синфазным и квадратурным опорными сигналами.
синфазный опорный сигнал ![]() квадратурный опорный сигнал
квадратурный опорный сигнал ![]() синфазный опорный сигнал
синфазный опорный сигнал ![]() квадратурный опорный сигнал
квадратурный опорный сигнал ![]()
Поскольку пары сигналов DPSK ортогональны, вероятность ошибки при подобном некогерентном обнаружении дается выражением (4.96). Впрочем, поскольку сигналы DPSK длятся 2Т секунд, энергия сигналов ![]() , определенных в формуле (4.98), равна удвоенной энергии сигнала, определенного в течение одного периода передачи символа.
, определенных в формуле (4.98), равна удвоенной энергии сигнала, определенного в течение одного периода передачи символа.
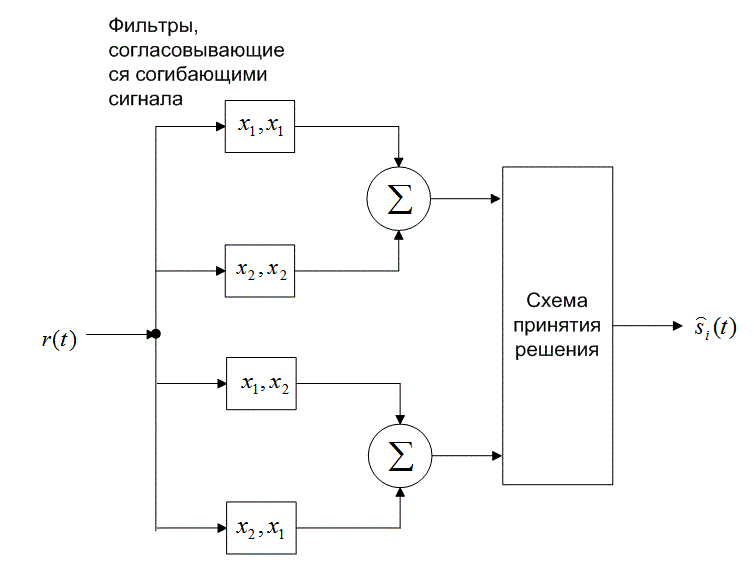
а)
б)
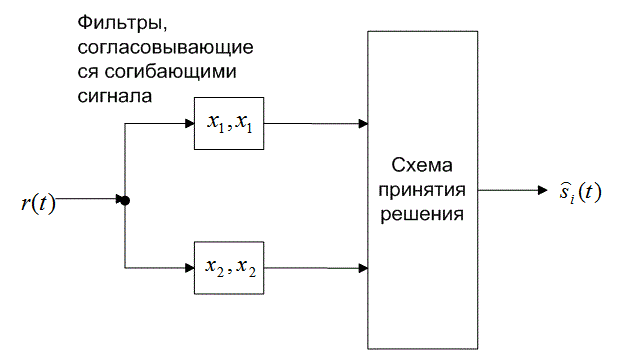
Рис. 4.26. Обнаружение в схеме DPSK: а) четырехканальное дифференциально-когерентное обнаружение сигналов в бинарной модуляции DPSK; б) эквивалентный двухканальный детектор сигналов в бинарной модуляции DPSK
Таким образом, РВможно записать в следующем виде.
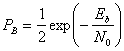 (4.100)
(4.100)
Зависимость (4.100), изображенная на рис. 4.25, представляет собой дифференциальное когерентное обнаружение сигналов в дифференциальной модуляции PSK, или просто DPSK. Выражение справедливо для оптимального детектора DPSK (рис. 4.17, в). Для детектора, показанного на рис. 4.17, б, вероятность ошибки будет несколько выше приведенной в выражении (4.100) [3]. Если сравнить вероятность ошибки, приведенную в формуле (4.100), с вероятностью ошибки когерентной схемы PSK (см. рис. 4.25), видно, что при равных РB схема DPSK требует приблизительно на 1 дБ большего отношения E^N0, чем схема BPSK (для ![]() ). Систему DPSK реализовать легче, чем систему PSK, поскольку приемник DPSK не требует фазовой синхронизации. По этой причине иногда предпочтительнее использовать менее эффективную схему DPSK, чем более сложную схему PSK.
). Систему DPSK реализовать легче, чем систему PSK, поскольку приемник DPSK не требует фазовой синхронизации. По этой причине иногда предпочтительнее использовать менее эффективную схему DPSK, чем более сложную схему PSK.
4.7.6. Вероятность ошибки для различных модуляций
В табл. 4.1 и на рис. 4.25 приведены аналитические выражения и графики РB для наиболее распространенных схем модуляции, описанных выше. Для РB = 10-4 можно видеть, что разница между лучшей (когерентной PSK) и худшей (некогерентной ортогональной FSK) из рассмотренных схем равна приблизительно 4 дБ. В некоторых случаях 4 дБ — это небольшая цена за простоту реализации, увеличивающуюся от когерентной схемы PSK до некогерентной FSK (рис. 4.25); впрочем, в других случаях ценным является даже выигрыш в 1 дБ. Помимо сложности реализации и вероятности РB существуют и другие факторы, влияющие на выбор модуляции; например, в некоторых случаях (в каналах со случайным затуханием) желательными являются некогерентные системы, поскольку иногда когерентные опорные сигналы затруднительно определять и использовать. В военных и космических приложениях весьма желательны сигналы, которые могут противостоять значительному ухудшению качества, сохраняя возможность обнаружения.
Таблица 4.1. Вероятность ошибки для различных бинарных модуляций
|
Модуляция |
PB |
|
PSK (когерентное обнаружение) |
|
|
DPSK (дифференциальное когерентное обнаружение) |
|
|
Ортогональная FSK (когерентное обнаружение) |
|
|
Ортогональная FSK (некогерентное обнаружение) |
|
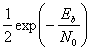
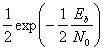
Основные показатели эффективности цифровой системы связи
Спектральная
эффективность Rb/П
– отношение скорости передачи (бит/c)
к ширине полосы (Гц).
Rb=log2M/Ts
(M
– объем алфавита символов, Ts
– длительность символа), полоса П =1/Ts
при амплитудно-фазовой манипуляции и
П =M/Ts
при частотной манипуляции, следовательно,
спектральная эффективность:
![]()
Удельные
энергетические затраты Eb
/ N0
при заданной вероятности ошибки –
отношение энергии Eb,
затраченной на передачу одного бита, к
односторонней спектральной плотности
аддитивного белого гауссова шума N0.
Вероятность битовой ошибки рb
![]()
Функция Q
табулирована, значение (a2
— a1)/(2
)
зависит от способа формирования сигнала.
Чтобы сравнивать различные способы
формирования сигналов по вероятности
ошибок, безразмерную величину (a2
— a1)/(2
)
выражают через удельные энергетические
затраты.
![]() –вероятность принять
–вероятность принять
сигнал х
при переданном символе s.

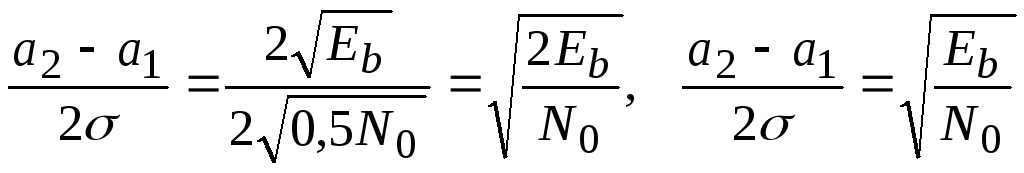
Максимальная пропускная способность канала
Максимальной
спектральной эффективностью Rbm/П
= log2
M
обладает система с амплитудно-фазовой
модуляцией.
Максимальное
значение Mмакс=
(S+N)/N
= 1+S/N
– числу различимых, при наличии шума,
градаций сигнала.
Соотношение
между максимально возможной спектральной
эффективностью и энергетическими
затратами дает теорема Шеннона – Хартли:
максимальная
скорость передачи информации Rbm
(бит/с)
по каналу с белым гауссовым шумом
(пропускная способность канала) равна
![]()
S
и N
– средняя мощность сигнала и шума,
П
– полоса
пропускания.
Минимально
допустимое значение Eb/N0
можно найти при предельном переходе
Rb/П→0:
![]()
Значение Eb/N0
= 0,693 = -1,6 дБ называют пределом Шеннона.
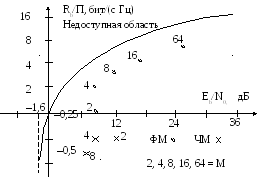
На рисунке указано
соотношение параметров Rb/П
и Eb/N0
при разных способах модуляции без
помехоустойчивого кодирования
(демодуляция сигналов с АФМ когерентная,
ортогональных сигналов с ЧМ –
некогерентная).
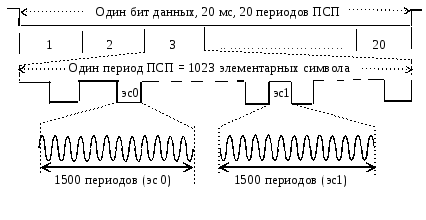
Расширение спектра прямой последовательностью
Расширение
спектра прямой последовательностью –
это модуляция сигнала двоичной
псевдослучайной последовательностью
(ПСП), выполняемая независимо от вида
информационного сигнала. Такая модуляция
может проводиться на разных этапах
формирования сигнала.
Исходная
информационная последовательность
данных суммируется с ПСП:
Расширение
спектра S(f)
сигнала и N(f)
помехи

Преимущества
систем с расширением спектра:
— высокая
помехоустойчивость,
— конфиденциальность
связи,
— возможность
многоканальной связи на одной несущей
частоте,
— возможность
передачи маломощного сигнала,
—
высокая
разрешающая способность по времени
Расширение
спектра скачкообразным изменением
несущей частоты

Расширение
спектра
сигналов в
системе GPS

Основные понятия
помехоустойчивого (канального) кодирования
Выявление и
устранение ошибок в принятом сообщении
основано на введении избыточности в
сообщение путем:
– многократной
передачи сообщения,
– повторной
передачи по запросу приемника,
–применения
корректирующих кодов для обнаружения
и исправления ошибки.
При блочном
кодировании
к каждому блоку данных из k
символов добавляют (n
– k)
избыточных (контрольных) символов,
зависящих от содержания k
«информационных» символов данного
блока. Набор из всех таких n
– разрядных блоков составляет блоковый
(n,
k)
код (block
code).
В «систематическом»
коде
проверочные символы приписываются к
концу информационной последовательности.
При непрерывном
кодировании
исходная информационная последовательность
символов полностью преобразуется в
процессе введения избыточности.
Разделения на информационные и проверочные
символы нет.
Примерами
непрерывного кодирования являются
сверточные коды
и турбокоды
– Кодовое
(хемминговое)
расстояние
d
между
двумя словами – это число одноименных
разрядов с разными символами. Оно равно
числу единиц в кодовой комбинации,
образованной суммированием по модулю
2 сравниваемых слов.
10111001
d
= 5
10001110
– Минимальное
кодовое расстояние –
минимальное
расстояние, взятое по всем парам
разрешенных кодовых комбинаций.
– Кратность
ошибки –
число искаженных символов кодовой
комбинации.
Исходное
слово 10111001,
принятое
слово 10001011 – ошибка кратности 3.
– Вес
кодовой комбинации
– число
единиц в двоичной кодовой комбинации.
10111001–
вес 5
– Вектор
ошибки –
кодовая комбинация с единицами в
искаженных разрядах и нулями в остальных
разрядах.
–
Скорость
кодирования – k/n.
–
Относительная
избыточность – (n—k)/n.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In digital transmission, the number of bit errors is the number of received bits of a data stream over a communication channel that have been altered due to noise, interference, distortion or bit synchronization errors.
The bit error rate (BER) is the number of bit errors per unit time. The bit error ratio (also BER) is the number of bit errors divided by the total number of transferred bits during a studied time interval. Bit error ratio is a unitless performance measure, often expressed as a percentage.[1]
The bit error probability pe is the expected value of the bit error ratio. The bit error ratio can be considered as an approximate estimate of the bit error probability. This estimate is accurate for a long time interval and a high number of bit errors.
Example[edit]
As an example, assume this transmitted bit sequence:
1 1 0 0 0 1 0 1 1
and the following received bit sequence:
0 1 0 1 0 1 0 0 1,
The number of bit errors (the underlined bits) is, in this case, 3. The BER is 3 incorrect bits divided by 9 transferred bits, resulting in a BER of 0.333 or 33.3%.
Packet error ratio[edit]
The packet error ratio (PER) is the number of incorrectly received data packets divided by the total number of received packets. A packet is declared incorrect if at least one bit is erroneous. The expectation value of the PER is denoted packet error probability pp, which for a data packet length of N bits can be expressed as
,
assuming that the bit errors are independent of each other. For small bit error probabilities and large data packets, this is approximately

Similar measurements can be carried out for the transmission of frames, blocks, or symbols.
The above expression can be rearranged to express the corresponding BER (pe) as a function of the PER (pp) and the data packet length N in bits:
![{displaystyle p_{e}=1-{sqrt[{N}]{(1-p_{p})}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5d380e45b0451c45265e199221fae5bd5b84bf9)
Factors affecting the BER[edit]
In a communication system, the receiver side BER may be affected by transmission channel noise, interference, distortion, bit synchronization problems, attenuation, wireless multipath fading, etc.
The BER may be improved by choosing a strong signal strength (unless this causes cross-talk and more bit errors), by choosing a slow and robust modulation scheme or line coding scheme, and by applying channel coding schemes such as redundant forward error correction codes.
The transmission BER is the number of detected bits that are incorrect before error correction, divided by the total number of transferred bits (including redundant error codes). The information BER, approximately equal to the decoding error probability, is the number of decoded bits that remain incorrect after the error correction, divided by the total number of decoded bits (the useful information). Normally the transmission BER is larger than the information BER. The information BER is affected by the strength of the forward error correction code.
Analysis of the BER[edit]
The BER may be evaluated using stochastic (Monte Carlo) computer simulations. If a simple transmission channel model and data source model is assumed, the BER may also be calculated analytically. An example of such a data source model is the Bernoulli source.
Examples of simple channel models used in information theory are:
- Binary symmetric channel (used in analysis of decoding error probability in case of non-bursty bit errors on the transmission channel)
- Additive white Gaussian noise (AWGN) channel without fading.
A worst-case scenario is a completely random channel, where noise totally dominates over the useful signal. This results in a transmission BER of 50% (provided that a Bernoulli binary data source and a binary symmetrical channel are assumed, see below).
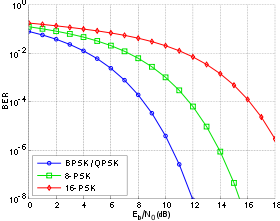
Bit-error rate curves for BPSK, QPSK, 8-PSK and 16-PSK, AWGN channel.

In a noisy channel, the BER is often expressed as a function of the normalized carrier-to-noise ratio measure denoted Eb/N0, (energy per bit to noise power spectral density ratio), or Es/N0 (energy per modulation symbol to noise spectral density).
For example, in the case of QPSK modulation and AWGN channel, the BER as function of the Eb/N0 is given by:

People usually plot the BER curves to describe the performance of a digital communication system. In optical communication, BER(dB) vs. Received Power(dBm) is usually used; while in wireless communication, BER(dB) vs. SNR(dB) is used.
Measuring the bit error ratio helps people choose the appropriate forward error correction codes. Since most such codes correct only bit-flips, but not bit-insertions or bit-deletions, the Hamming distance metric is the appropriate way to measure the number of bit errors. Many FEC coders also continuously measure the current BER.
A more general way of measuring the number of bit errors is the Levenshtein distance.
The Levenshtein distance measurement is more appropriate for measuring raw channel performance before frame synchronization, and when using error correction codes designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.[3]
Mathematical draft[edit]
The BER is the likelihood of a bit misinterpretation due to electrical noise 





Knowing that the noise has a bilateral spectral density 

and 
Returning to BER, we have the likelihood of a bit misinterpretation 


where 

We can use the average energy of the signal 
±§

Bit error rate test[edit]
BERT or bit error rate test is a testing method for digital communication circuits that uses predetermined stress patterns consisting of a sequence of logical ones and zeros generated by a test pattern generator.
A BERT typically consists of a test pattern generator and a receiver that can be set to the same pattern. They can be used in pairs, with one at either end of a transmission link, or singularly at one end with a loopback at the remote end. BERTs are typically stand-alone specialised instruments, but can be personal computer–based. In use, the number of errors, if any, are counted and presented as a ratio such as 1 in 1,000,000, or 1 in 1e06.
Common types of BERT stress patterns[edit]
- PRBS (pseudorandom binary sequence) – A pseudorandom binary sequencer of N Bits. These pattern sequences are used to measure jitter and eye mask of TX-Data in electrical and optical data links.
- QRSS (quasi random signal source) – A pseudorandom binary sequencer which generates every combination of a 20-bit word, repeats every 1,048,575 words, and suppresses consecutive zeros to no more than 14. It contains high-density sequences, low-density sequences, and sequences that change from low to high and vice versa. This pattern is also the standard pattern used to measure jitter.
- 3 in 24 – Pattern contains the longest string of consecutive zeros (15) with the lowest ones density (12.5%). This pattern simultaneously stresses minimum ones density and the maximum number of consecutive zeros. The D4 frame format of 3 in 24 may cause a D4 yellow alarm for frame circuits depending on the alignment of one bits to a frame.
- 1:7 – Also referred to as 1 in 8. It has only a single one in an eight-bit repeating sequence. This pattern stresses the minimum ones density of 12.5% and should be used when testing facilities set for B8ZS coding as the 3 in 24 pattern increases to 29.5% when converted to B8ZS.
- Min/max – Pattern rapid sequence changes from low density to high density. Most useful when stressing the repeater’s ALBO feature.
- All ones (or mark) – A pattern composed of ones only. This pattern causes the repeater to consume the maximum amount of power. If DC to the repeater is regulated properly, the repeater will have no trouble transmitting the long ones sequence. This pattern should be used when measuring span power regulation. An unframed all ones pattern is used to indicate an AIS (also known as a blue alarm).
- All zeros – A pattern composed of zeros only. It is effective in finding equipment misoptioned for AMI, such as fiber/radio multiplex low-speed inputs.
- Alternating 0s and 1s — A pattern composed of alternating ones and zeroes.
- 2 in 8 – Pattern contains a maximum of four consecutive zeros. It will not invoke a B8ZS sequence because eight consecutive zeros are required to cause a B8ZS substitution. The pattern is effective in finding equipment misoptioned for B8ZS.
- Bridgetap — Bridge taps within a span can be detected by employing a number of test patterns with a variety of ones and zeros densities. This test generates 21 test patterns and runs for 15 minutes. If a signal error occurs, the span may have one or more bridge taps. This pattern is only effective for T1 spans that transmit the signal raw. Modulation used in HDSL spans negates the bridgetap patterns’ ability to uncover bridge taps.
- Multipat — This test generates five commonly used test patterns to allow DS1 span testing without having to select each test pattern individually. Patterns are: all ones, 1:7, 2 in 8, 3 in 24, and QRSS.
- T1-DALY and 55 OCTET — Each of these patterns contain fifty-five (55), eight bit octets of data in a sequence that changes rapidly between low and high density. These patterns are used primarily to stress the ALBO and equalizer circuitry but they will also stress timing recovery. 55 OCTET has fifteen (15) consecutive zeroes and can only be used unframed without violating one’s density requirements. For framed signals, the T1-DALY pattern should be used. Both patterns will force a B8ZS code in circuits optioned for B8ZS.
Bit error rate tester[edit]
A bit error rate tester (BERT), also known as a «bit error ratio tester»[4] or bit error rate test solution (BERTs) is electronic test equipment used to test the quality of signal transmission of single components or complete systems.
The main building blocks of a BERT are:
- Pattern generator, which transmits a defined test pattern to the DUT or test system
- Error detector connected to the DUT or test system, to count the errors generated by the DUT or test system
- Clock signal generator to synchronize the pattern generator and the error detector
- Digital communication analyser is optional to display the transmitted or received signal
- Electrical-optical converter and optical-electrical converter for testing optical communication signals
See also[edit]
- Burst error
- Error correction code
- Errored second
- Pseudo bit error ratio
- Viterbi Error Rate
References[edit]
- ^ Jit Lim (14 December 2010). «Is BER the bit error ratio or the bit error rate?». EDN. Retrieved 2015-02-16.
- ^
Digital Communications, John Proakis, Massoud Salehi, McGraw-Hill Education, Nov 6, 2007 - ^
«Keyboards and Covert Channels»
by Gaurav Shah, Andres Molina, and Matt Blaze (2006?) - ^ «Bit Error Rate Testing: BER Test BERT » Electronics Notes». www.electronics-notes.com. Retrieved 2020-04-11.
![]() This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
External links[edit]
- QPSK BER for AWGN channel – online experiment
From Wikipedia, the free encyclopedia
In digital transmission, the number of bit errors is the number of received bits of a data stream over a communication channel that have been altered due to noise, interference, distortion or bit synchronization errors.
The bit error rate (BER) is the number of bit errors per unit time. The bit error ratio (also BER) is the number of bit errors divided by the total number of transferred bits during a studied time interval. Bit error ratio is a unitless performance measure, often expressed as a percentage.[1]
The bit error probability pe is the expected value of the bit error ratio. The bit error ratio can be considered as an approximate estimate of the bit error probability. This estimate is accurate for a long time interval and a high number of bit errors.
Example[edit]
As an example, assume this transmitted bit sequence:
1 1 0 0 0 1 0 1 1
and the following received bit sequence:
0 1 0 1 0 1 0 0 1,
The number of bit errors (the underlined bits) is, in this case, 3. The BER is 3 incorrect bits divided by 9 transferred bits, resulting in a BER of 0.333 or 33.3%.
Packet error ratio[edit]
The packet error ratio (PER) is the number of incorrectly received data packets divided by the total number of received packets. A packet is declared incorrect if at least one bit is erroneous. The expectation value of the PER is denoted packet error probability pp, which for a data packet length of N bits can be expressed as
assuming that the bit errors are independent of each other. For small bit error probabilities and large data packets, this is approximately
Similar measurements can be carried out for the transmission of frames, blocks, or symbols.
The above expression can be rearranged to express the corresponding BER (pe) as a function of the PER (pp) and the data packet length N in bits:
Factors affecting the BER[edit]
In a communication system, the receiver side BER may be affected by transmission channel noise, interference, distortion, bit synchronization problems, attenuation, wireless multipath fading, etc.
The BER may be improved by choosing a strong signal strength (unless this causes cross-talk and more bit errors), by choosing a slow and robust modulation scheme or line coding scheme, and by applying channel coding schemes such as redundant forward error correction codes.
The transmission BER is the number of detected bits that are incorrect before error correction, divided by the total number of transferred bits (including redundant error codes). The information BER, approximately equal to the decoding error probability, is the number of decoded bits that remain incorrect after the error correction, divided by the total number of decoded bits (the useful information). Normally the transmission BER is larger than the information BER. The information BER is affected by the strength of the forward error correction code.
Analysis of the BER[edit]
The BER may be evaluated using stochastic (Monte Carlo) computer simulations. If a simple transmission channel model and data source model is assumed, the BER may also be calculated analytically. An example of such a data source model is the Bernoulli source.
Examples of simple channel models used in information theory are:
- Binary symmetric channel (used in analysis of decoding error probability in case of non-bursty bit errors on the transmission channel)
- Additive white Gaussian noise (AWGN) channel without fading.
A worst-case scenario is a completely random channel, where noise totally dominates over the useful signal. This results in a transmission BER of 50% (provided that a Bernoulli binary data source and a binary symmetrical channel are assumed, see below).
Bit-error rate curves for BPSK, QPSK, 8-PSK and 16-PSK, AWGN channel.
In a noisy channel, the BER is often expressed as a function of the normalized carrier-to-noise ratio measure denoted Eb/N0, (energy per bit to noise power spectral density ratio), or Es/N0 (energy per modulation symbol to noise spectral density).
For example, in the case of QPSK modulation and AWGN channel, the BER as function of the Eb/N0 is given by:
People usually plot the BER curves to describe the performance of a digital communication system. In optical communication, BER(dB) vs. Received Power(dBm) is usually used; while in wireless communication, BER(dB) vs. SNR(dB) is used.
Measuring the bit error ratio helps people choose the appropriate forward error correction codes. Since most such codes correct only bit-flips, but not bit-insertions or bit-deletions, the Hamming distance metric is the appropriate way to measure the number of bit errors. Many FEC coders also continuously measure the current BER.
A more general way of measuring the number of bit errors is the Levenshtein distance.
The Levenshtein distance measurement is more appropriate for measuring raw channel performance before frame synchronization, and when using error correction codes designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.[3]
Mathematical draft[edit]
The BER is the likelihood of a bit misinterpretation due to electrical noise
Knowing that the noise has a bilateral spectral density
and
Returning to BER, we have the likelihood of a bit misinterpretation
where
We can use the average energy of the signal
±§
Bit error rate test[edit]
BERT or bit error rate test is a testing method for digital communication circuits that uses predetermined stress patterns consisting of a sequence of logical ones and zeros generated by a test pattern generator.
A BERT typically consists of a test pattern generator and a receiver that can be set to the same pattern. They can be used in pairs, with one at either end of a transmission link, or singularly at one end with a loopback at the remote end. BERTs are typically stand-alone specialised instruments, but can be personal computer–based. In use, the number of errors, if any, are counted and presented as a ratio such as 1 in 1,000,000, or 1 in 1e06.
Common types of BERT stress patterns[edit]
- PRBS (pseudorandom binary sequence) – A pseudorandom binary sequencer of N Bits. These pattern sequences are used to measure jitter and eye mask of TX-Data in electrical and optical data links.
- QRSS (quasi random signal source) – A pseudorandom binary sequencer which generates every combination of a 20-bit word, repeats every 1,048,575 words, and suppresses consecutive zeros to no more than 14. It contains high-density sequences, low-density sequences, and sequences that change from low to high and vice versa. This pattern is also the standard pattern used to measure jitter.
- 3 in 24 – Pattern contains the longest string of consecutive zeros (15) with the lowest ones density (12.5%). This pattern simultaneously stresses minimum ones density and the maximum number of consecutive zeros. The D4 frame format of 3 in 24 may cause a D4 yellow alarm for frame circuits depending on the alignment of one bits to a frame.
- 1:7 – Also referred to as 1 in 8. It has only a single one in an eight-bit repeating sequence. This pattern stresses the minimum ones density of 12.5% and should be used when testing facilities set for B8ZS coding as the 3 in 24 pattern increases to 29.5% when converted to B8ZS.
- Min/max – Pattern rapid sequence changes from low density to high density. Most useful when stressing the repeater’s ALBO feature.
- All ones (or mark) – A pattern composed of ones only. This pattern causes the repeater to consume the maximum amount of power. If DC to the repeater is regulated properly, the repeater will have no trouble transmitting the long ones sequence. This pattern should be used when measuring span power regulation. An unframed all ones pattern is used to indicate an AIS (also known as a blue alarm).
- All zeros – A pattern composed of zeros only. It is effective in finding equipment misoptioned for AMI, such as fiber/radio multiplex low-speed inputs.
- Alternating 0s and 1s — A pattern composed of alternating ones and zeroes.
- 2 in 8 – Pattern contains a maximum of four consecutive zeros. It will not invoke a B8ZS sequence because eight consecutive zeros are required to cause a B8ZS substitution. The pattern is effective in finding equipment misoptioned for B8ZS.
- Bridgetap — Bridge taps within a span can be detected by employing a number of test patterns with a variety of ones and zeros densities. This test generates 21 test patterns and runs for 15 minutes. If a signal error occurs, the span may have one or more bridge taps. This pattern is only effective for T1 spans that transmit the signal raw. Modulation used in HDSL spans negates the bridgetap patterns’ ability to uncover bridge taps.
- Multipat — This test generates five commonly used test patterns to allow DS1 span testing without having to select each test pattern individually. Patterns are: all ones, 1:7, 2 in 8, 3 in 24, and QRSS.
- T1-DALY and 55 OCTET — Each of these patterns contain fifty-five (55), eight bit octets of data in a sequence that changes rapidly between low and high density. These patterns are used primarily to stress the ALBO and equalizer circuitry but they will also stress timing recovery. 55 OCTET has fifteen (15) consecutive zeroes and can only be used unframed without violating one’s density requirements. For framed signals, the T1-DALY pattern should be used. Both patterns will force a B8ZS code in circuits optioned for B8ZS.
Bit error rate tester[edit]
A bit error rate tester (BERT), also known as a «bit error ratio tester»[4] or bit error rate test solution (BERTs) is electronic test equipment used to test the quality of signal transmission of single components or complete systems.
The main building blocks of a BERT are:
- Pattern generator, which transmits a defined test pattern to the DUT or test system
- Error detector connected to the DUT or test system, to count the errors generated by the DUT or test system
- Clock signal generator to synchronize the pattern generator and the error detector
- Digital communication analyser is optional to display the transmitted or received signal
- Electrical-optical converter and optical-electrical converter for testing optical communication signals
See also[edit]
- Burst error
- Error correction code
- Errored second
- Pseudo bit error ratio
- Viterbi Error Rate
References[edit]
- ^ Jit Lim (14 December 2010). «Is BER the bit error ratio or the bit error rate?». EDN. Retrieved 2015-02-16.
- ^
Digital Communications, John Proakis, Massoud Salehi, McGraw-Hill Education, Nov 6, 2007 - ^
«Keyboards and Covert Channels»
by Gaurav Shah, Andres Molina, and Matt Blaze (2006?) - ^ «Bit Error Rate Testing: BER Test BERT » Electronics Notes». www.electronics-notes.com. Retrieved 2020-04-11.
![]() This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
External links[edit]
- QPSK BER for AWGN channel – online experiment
Введение
Моя сеть приёма сигналов со спутников r2cloud постепенно растёт. Однако уровень приёма оставляет желать лучшего. Несмотря на то, что на спектограмме виден сигнал, демодулятор не может восстановить его. В попытках найти проблему, я понял, что мне не хватает фундаментальных знаний по теории обработки сигналов и некоторой математики. Дело в том, что в интернете зачастую выкладываются демодуляторы без обоснования их работы. Меня это не устраивает, потому что нужны метрики по которым я буду понимать насколько один алгоритм эффективнее другого. И стал ли новый код лучше, если я добавлю какой-нибудь другой блок в обработку.
Всё это привело меня к ( E_b / N_0 ). Эта метрика показывает отношение энергии сигнала, приходящейся на 1 бит принимаемого сообщения (( E_b )), к энергетической спектральной плотности шума (( N_0 )). Почему она так важна? Дело в том, что она не зависит от способа модуляции сигнала и пропускной способности канала. Из-за этого её можно использовать, чтобы сравнивать различные модуляции между собой. Обычно строят график отношения ( E_b / N_0 ) к вероятности ошибки (BER). Вот пример графика сравнения BPSK/QPSK/8-PSK/16-PSK:

Что из этого графика можно понять?
- Если увеличивать энергию передаваемого бита, то уменьшается вероятность возникновения ошибки.
- В BPSK/QPSK ошибка возникает значительно реже, чем в 8-PSK и 16-PSK при одинаковых значениях энергии передаваемого бита.
- График, например, читается следующим образом: при ( E_b / N_0 ) равным 4 децибелла и BPSK модуляции можно получить 1 ошибочный бит на каждые 100 полученных.
Мне же график прежде всего нужен:
- Сравнивать теоретические значения с практической реализацией демодулятора. Прямо сейчас я точно знаю, что различия есть из-за ограниченной точности АЦП. Дело в том, что rtl-sdr имеет разрешающую способность 8 бит. А в теории числа могут быть бесконечной точности. Именно эта разница и должна давать ошибку.
- Анализировать улучшится ли демодулятор, если добавить какой-то определённый блок. Как минимум я хочу попробовать различные алгоритмы получения несущего сигнала и компенсации многолучевого распространения.
Ну и для того, чтобы понять математику, я решил проделать выводы сам. Ниже я буду рассчитывать вероятности ошибки для BPSK (см. синий график выше). Вдохновение я черпал у dsplog плюс добавлял свои мысли.
Дано
Прежде всего необходимо описать физику процесса. Схема процесса показана ниже:
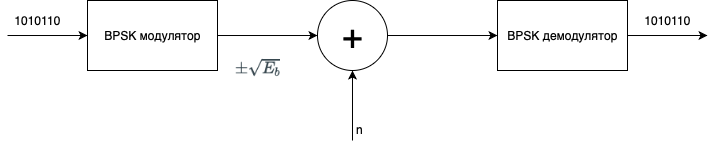
- Изначальное сообщение кодируется в аналоговый сигнал. “1” кодируется в (+sqrt{E_b}), “0” кодируется в (-sqrt{E_b}). Почему именно как корень из (E_b)? Не знаю. Это единственное место, где я не разобрался.
- После этого сигнал складывается с аддитивным белым гауссовским шумом.
- Далее сигнал демодулируется.
Модулированный BPSK сигнал выглядит следующим образом:
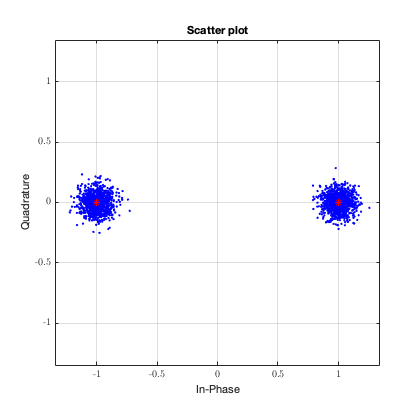
Красными точками обозначается сигнал без шума. Синими — сигнал с добавлением белого гауссовского шума. Как демодулируется этот сигнал? Все точки, которые больше “0” становятся “1”, а те, что меньше “0” становятся “0”. На рисунке выше все синие точки достаточно далеко от “0”, поэтому информацию можно однозначно восстановить. Но что если шум будет сильнее?
Тут уже не всё так однозначно. Видно, что некоторые точки закодированные как “1” на самом деле оказались меньше “0”. И если бы я попытался их демодулировать, то получил бы неправильную информацию.
Решение
Теперь, когда стало понятно влияние шума на результат демодуляции, можно переходить к графику зависимости вероятности от энергии сигнала. Этот график поможет посчитать вероятность ошибок для различных входных значений. Для начала возьмём сигнал без шума. Вероятность получения “0” или “1” всегда 1.
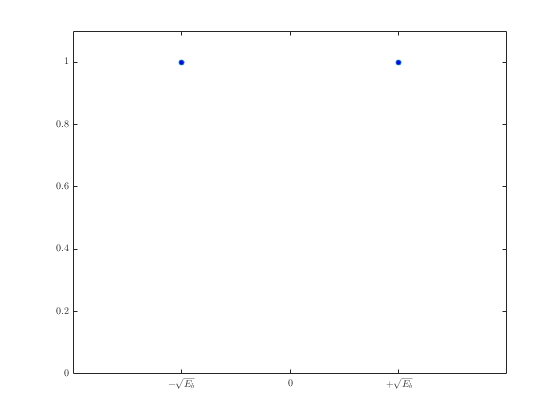
Частота получения ошибочных битов (Bit error rate) будет 0. Т.е. 0 ошибочных битов на бесконечное количество принятых. В случае наличия гауссовского шума, вероятность получения определяется гауссовской функцией вероятности:
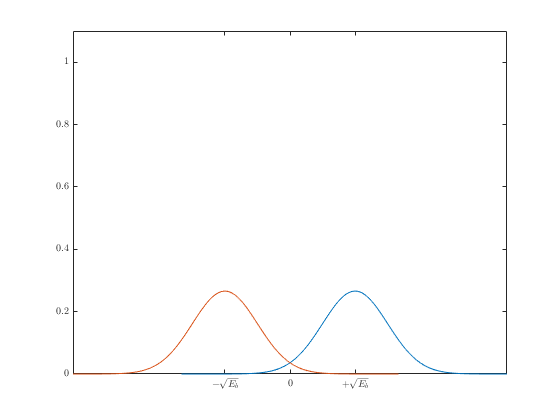
Гауссовский шум определяется следующей формулой:
$$
p(x) = dfrac{1}{sqrt{2pisigma^2}}e^dfrac{-(x-mu)^2}{2sigma^2}
$$
Где:
- (mu=0),
- (sigma^2=N_0/2)
При передаче “1” (mu=+sqrt{E_b}), при “0” (mu=-sqrt{E_b}). Подставляя это в формулу:
$$
begin{align}
P(x|s_0)=dfrac{1}{sqrt{pi N_0}}e^dfrac{-(x+sqrt{E_b})^2}{N_0} newline
P(x|s_1)=dfrac{1}{sqrt{pi N_0}}e^dfrac{-(x-sqrt{E_b})^2}{N_0}
end{align}
$$
Теперь самое интересное.
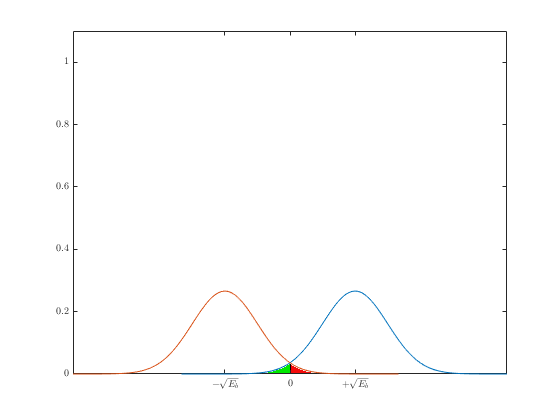
На этом рисунке показаны области возникновения ошибки. Зелёная область — это место, где возникает ошибка при передаче “1”, красная — при передаче “0”. Общую вероятность ошибки можно записать с помощью формулы полной вероятности:
$$
P(error)=dfrac{1}{2}P(error|s_0) + dfrac{1}{2}P(error|s_1)
$$
После этого необходимо найти каждую из вероятностей:
$$
begin{align}
P(error|s_0) = int_{0}^{infty}P(x|s_0)dx = dfrac{1}{sqrt{pi N_0}}int_{0}^{infty}e^dfrac{-(x+sqrt{E_b})^2}{N_0}dx newline
P(error|s_1) = int_{-infty}^{0}P(x|s_1)dx = dfrac{1}{sqrt{pi N_0}}int_{-infty}^{0}e^dfrac{-(x-sqrt{E_b})^2}{N_0}dx
end{align}
$$
Обычно вероятность ошибки записывают с помощью функции ошибок:
$$
erfc(x)=dfrac{2}{sqrtpi}int_{0}^{x}e^{-t^2}dt
$$
Для этого необходимо сделать следующее:
$$
z=dfrac{y+sqrt{E_b}}{sqrt{N_0}} => zsqrt{N_0} = y + sqrt{E_b}
$$
Заменить пределы интегрирования:
$$
begin{align}
y=0 => z = dfrac{sqrt{E_b}}{sqrt{N_0}} newline
y=infty => z = infty
end{align}
$$
Получившаяся ошибка записывается как:
$$
begin{align}
P(error|s_0)=dfrac{1}{sqrt{pi N_0}}int_limits{sqrt{dfrac{E_b}{N_0}}}^{infty}e^{-z^2}sqrt{N_0}dz
=dfrac{1}{sqrt{pi}}int_limits{sqrt{dfrac{E_b}{N_0}}}^{infty}e^{-z^2}dz
=dfrac{1}{2}erfc(sqrt{dfrac{E_b}{N_0}})
end{align}
$$
Аналогично можно найти ошибку при передаче “1”:
$$
begin{align}
P(error|s_1)=1-P(s_1)=1-dfrac{1}{2}erfc(-sqrt{dfrac{E_b}{N_0}})
end{align}
$$
Можно воспользоваться свойством функции ошибок:
$$
begin{align}
erfc(-x)=2-erfc(x) => P(error|s_1) = dfrac{1}{2}erfc(sqrt{dfrac{E_b}{N_0}})
end{align}
$$
Если подставить в формулу полной вероятности:
$$
P(error)=dfrac{1}{2}(dfrac{1}{2}erfc(sqrt{dfrac{E_b}{N_0}})) + dfrac{1}{2}(dfrac{1}{2}erfc(sqrt{dfrac{E_b}{N_0}}))=dfrac{1}{2}erfc(sqrt{dfrac{E_b}{N_0}})
$$
Ответ
Получившийся график:
6.1. Определения коэффициента ошибок
6.2. Математическое выражение коэффициента битовых ошибок
6.3. Нормы на параметры ошибок систем передачи
6.4. Принципы построения измерителей ошибок
6.5. Техника измерения коэффициента ошибок
6.1. Определения коэффициента ошибок
Коэффициент ошибок – важнейшая характеристика линейного тракта. Он измеряется как для отдельных участков регенерации, так и для тракта в целом. Определяется коэффициент ошибок kОШ, по формуле:
kОШ = NОШ /N, (6.1)
где N – общее число символов, переданных за интервал измерения; NОШ – число ошибочно принятых символов за интервал измерения.
Измерение коэффициента ошибок носит статистический характер, так как получаемый за конечное время результат является случайной величиной. Относительную погрешность измерения в случае нормального закона распределения числа ошибок, что допустимо при N≥10, можно определить по формуле:
. (6.2)
Здесь ![]() — коэффициент, зависящий от доверительной вероятности результата измерений:
— коэффициент, зависящий от доверительной вероятности результата измерений:
![]() , (6.3)
, (6.3)
где ![]() — обратная функция интеграла вероятности
— обратная функция интеграла вероятности ![]() :
:
![]() . (6.4)
. (6.4)
Значение kОШ позволяет оценивать вероятность ошибки pОШ – количественную оценку помехоустойчивости. Область возможных значений оценки, в которой с заданной доверительной вероятностью будет находиться значение pОШ, определяется верхней (pВ) и нижней (pН) доверительными границами. При нормальном законе распределения числа ошибок значения pВ и pН определяются по формулам:
![]() , (6.5)
, (6.5)
![]() , (6.6)
, (6.6)
Очевидно, что точность оценок вероятности ошибки и коэффициента ошибки растет с увеличением N. Общее число символов цифрового сигнала, переданных за интервал измерения T, зависит от скорости передачи B: N = TB. Отсюда следует, что чем больше скорость передачи, тем быстрее и точнее можно оценить коэффициент ошибок.
6.2. Математическое выражение коэффициента битовых ошибок
Определим коэффициент битовых ошибок для реальных приёмников, которым свойственно наличие различных источников шумов. При этом будем считать, что приёмник принимает решение, какой бит (0 или 1) был передан в каждом битовом интервале путем стробирования фототока. Очевидно, что из-за наличия шумов данное решение может быть неверным, что приводит к появлению ошибочных битов. Поэтому, чтобы определить коэффициент битовых ошибок, необходимо понять, каким образом приемник принимает решение относительно переданного бита.
Обозначим через I1 и I0 фототоки, стробированные приемником в течение 1 и 0 битов, соответственно, а через s12 и s02 соответствующие шумы. Принимая, что последние имеют гауссовское распределение, проблема установления истинного значения принятого бита имеет следующую математическую формулировку. Фототок для битов 1 и 0 является выборкой гауссовской переменной со средним значением I1 и вариацией s1, а приёмник должен отслеживать этот сигнал и решать, является ли переданный бит 0 или 1. При этом существует много возможных правил принятия решения, которые могут быть реализованы в приёмнике с целью минимизации коэффициента битовых ошибок. Для значения фототока I этим оптимальным решением является наиболее вероятное значение переданного бита, которое определяется путём сравнения текущего значения фототока с пороговым значением Iп, используемым для принятия решения.
Рисунок 6.1. Функция плотности вероятности фототока принятых сигналов
Пусть при I ³ Iп принимается решение о том, что был передан бит 1, в противном случае – бит 0. Когда биты 1 и 0 равновероятны, что и рассматривается в дальнейшем, пороговый ток приблизительно равен:
![]() (6.7)
(6.7)
Геометрически Iп представляет собой значение тока I, для которого две кривые плотности вероятностей (рис. 6.1) пересекаются.
Вероятность того, что I < Iп, т. е. вероятность ошибки при передаче бита 1, обозначим через Р0,1, а вероятность решения для переданного бита 1, когда I ³ Iп при переданном 0, обозначим Р1,0.
Пусть Q(х) обозначает вероятность того, что нулевая средняя вариация гауссовской переменной превышает значение х, тогда:
(6.8)
а
(6.9)
а
(6.10)
Можно показать [14], что BER определяется,
(6.11)
Очень важно отметить, что в ряде случаев эффективным является использование изменяемого в зависимости от уровня сигнала порога принятия решения, как, например, шума оптического усилителя. Многие высокоскоростные приёмники обладают такой особенностью. Однако более простые приемники имеют порог, соответствующий среднему уровню принимаемого тока, а именно (I1 + I0)/2. Такая настройка порогового значения дает большой коэффициент битовых ошибок, определяемый выражением [14].
(6.12)
Выражение (6.11) можно использовать для оценки BER, когда известны как мощность полученного сигнала, соответствующего битам 0 и 1, так и статистика шумов.
6.3. Нормы на параметры ошибок систем передачи
Битовые ошибки являются основным источником ухудшения качества связи, проявляющегося в искажении речи в телефонных каналах, недостоверности передачи информации или снижении пропускной способности передачи данных, и характеризуются статистическими параметрами и нормами на них, которые определены соответствующей вероятностью выполнения этих норм. Последние делятся на долговременные и оперативные нормы, первые из которых определяются рекомендациями ITU-T G.821 и G.826, а вторые – М.2100, М.2110 и М.2120, при этом, согласно М.2100, качество цифрового тракта по критерию ошибок делят на три категории:
- нормальное – BER < 10-6;
- пониженное – 10-6 ≤ BER < 10-3 (предаварийное состояние);
- неприемлемое – BER ≥ 10-3 (аварийное состояние).
Так как появление ошибок является следствием совокупности всех текущих условий передачи цифровых сигналов, имеющих случайный характер, то при отсутствии данных о законе распределения ошибок его отдельные элементы могут быть определены с определенной степенью достоверности только по результатам продолжительных измерений. В то же время на практике необходимо, чтобы значения параметров ошибок для ввода в эксплуатацию и технического обслуживания систем передачи основывались на достаточно коротких интервалах времени измерения. Исходя из этого, были определены следующие параметры ошибок [14]:
- секунда с ошибками (error second, ES) – односекундный интервал, содержащий хотя бы один ошибочный бит;
- секунда, пораженная ошибками (severely error second, SES) – односекундный интервал с BER ≥ 10-3.
Данные параметры ошибок должны оцениваться в течение времени готовности (available time), отсчет которого начинается с первой секунды из десяти следующих друг за другом секунд, в каждой из которых BER<10-3. ITU-T M.2100 регламентирует нормы качества (performance objectives, PO) на выраженные максимальным процентом времени параметры ошибок, которые зависят только от скорости передачи и приводятся для условного эталонного соединения (hypothetical reference connection, HRC/HRX/) длиной 27500 км. При этом нормы качества распределяются по участкам соединения соответствующей категории качества. В качестве эталонной модели такого распределения принимается участок высокой категории качества протяженностью 25000 км, которому присваивается 40% от общей нормы качества на параметры ошибок передачи точка-точка, что в пересчете на 1 км, дает 0.0016 %/км.. Остальные 4 участка (2 среднего качества и 2 с приемлемым качеством) длиной 2 х 1250 км расположены по обе стороны от центрального. Поэтому распределение, пропорциональное протяженности L км тракта высокой категории качества, будет определяться, как
AL = 0.0016 · L %/км. (6.13)
Нормы качества на цифровые тракты и каналы подразделяются на настроечные и эксплуатационные, причем вводимые в эксплуатацию впервые или после проведения корректирующих действий они должны сдаваться по настроечным нормам качества, а в процессе эксплуатации должны соответствовать эксплуатационным нормам. Обычно [105] эксплуатационная норма представляется в виде эталонной нормы качества (reference performance objective, RPO)
RPO = A · T · PO, (6.14)
а настроечная, включающая запас на старение, используемая при вводе в эксплуатацию (bringing into service objective, BISO), определяется, как половина RPO, т.е.
BISO = RPO/2. (6.15)
Здесь PO – норма качества оцениваемого параметра, а T = 86400 с (одни сутки) – продолжительность измерений (количество односекундных интервалов).
Для анализа результатов, полученных в процессе измерений, используются также предельные значения S1и S2 норм (рисунок 6.2), которые соответствуют числу событий (ES,SES) и определяются, как:
S1 = RPO/2 – D и S2 = RPO/2 + D, (6.16)
где D = 2![]() — дисперсия оцениваемого параметра.
— дисперсия оцениваемого параметра.
Рисунок 6.2. Предельные значения и условия ввода в эксплуатацию системы передачи
При соответствии результатов измерений норме S1 цифровой тракт может быть введен в эксплуатацию без всякого сомнения, а при превышении нормы S2 в обязательном порядке требуется повышение качества испытываемого цифрового тракта, т.е. должны быть проведены корректирующие действия с повторными измерениями. Если значение ES или SES лежит в интервале от S1 до S2, цифровой тракт может быть введен в эксплуатацию условно или временно с продолжением измерений в течение 7 суток. Данный подход к оценке качества цифровых систем передачи по параметрам ошибок позволяет сократить время измерений и получить норму цифрового тракта суммированием норм цифровых участков. При этом значения RPO, D, S1 и S2 выражаются в виде числа событий за установленный интервал времени, а не в виде процентов времени.
Для измерения коэффициента ошибок разработан ряд специальных BER анализаторов – измерителей коэффициента ошибок, включающих генераторы псевдослучайных и детерминированных последовательностей передаваемых кодированных символов, а также приемное оборудование, осуществляющее собственно измерение коэффициента ошибок. В случае посимвольного сравнения кодов измерение может быть выполнено с использованием шлейфа, т.е. путем измерения ошибок с одной оконечной станции при установке на противоположном конце шлейфа. Другой метод основан на выделении ошибок благодаря избыточности используемых кодов и используется для измерений от передающей до приемной сторон тракта или участка линии, т.е. когда выделение и фиксация ошибок производятся на ее приемном конце. Очевидно, что в первом случае требуется использование одного комплекта, а во втором – двух комплектов приборов. При этом измеренное значение коэффициента ошибок отражает качество передачи при прохождении сигнала в обоих направлениях и в каждом направлении соответственно.
6.4. Принципы построения измерителей ошибок
В зависимости от скорости передачи контролируемой системы передачи в анализаторе используются различные схемотехнические решения.
Рисунок 6.3. Генератор низкоскоростного BER анализатора
Низкоскоростной генератор тестовых кодов и детектор ошибок. Используемый в телекоммуникациях анализатор BER, состоящий [106] из генератора тестовых кодов и собственно анализатора ошибок, представлен на рисунках 6.3 и 6.4. Он предназначен для невысоких (до 200 Мбит/с) битовых скоростей, учитывая, что максимальные типовые скорости составляют 44.736 Мбит/с (DS3) в Северной Америке и 139.364 Мбит/с – за пределами Северной Америки.
PRBS с генератором кодовых групп, представленный на рис. 6.16, синхронизируется либо от источника тактового сигнала с фиксированной частотой (согласно G.703), либо от синтезатора, осуществляя тем самым изменение частоты синхронизации. В связи с этим использование данных средств требует задания некоторых определенных частот синхронизации и наличия возможности обеспечения их небольших смещений от ±15 до ±50 ppm. Для повторения тестовых кодов схема PRBS и генератор кодовых групп обычно имеют триггерную схему, управляющую либо выходным усилителем бинарных данных, который обеспечивает данные и данные с сопровождающим синхросигналом, либо выходную схему кодированных данных. Это позволяет создавать цикловую синхронизацию сигнала в соответствии с требованием, например, системы SONET/SDH. Кроме этого, данная схема способствует созданию соответствующего интерфейсного кода для эффективного восстановления тактовой синхронизации. Выходной усилитель обеспечивает необходимый уровень сигнала в соответствии со спецификацией электрического интерфейса, в том числе сигнала с чередованием полярности импульсов.
Рисунок 6.4. Низкоскоростной детектор ошибок
Детектор ошибок, показанный на рисунке 6.4, получает стандартный кодированный сигнал, восстанавливает генератор синхросигнала и устраняет кодирование для обеспечения бинарной даты и синхросигналов. Он обнаруживает любые нарушения алгоритма интерфейсного кода и посылает сигналы на счетчик ошибок, что составляет первый уровень процесса обнаружения ошибок. При работе с цикловыми сигналами приемник захватывает любой присутствующий элемент цикловой синхронизации, проверяет наличие цикловых ошибок и декодирует любые встроенные сигналы тревоги, или CRC биты, тем самым обеспечивая возможность измерения.
Наконец, бинарные данные и синхросигнал направляются на детектор ошибок и генератор эталонных тестовых кодов, которые проверяют полученный тестовый код бит за битом на предмет обнаружения логических ошибок. Временная база контролирует пропускание измерения для непрерывного, периодического и ручного режима. Накопленное количество ошибок обрабатывается для получения значения BER и анализа функционирования при наличии ошибок.
Высокоскоростной генератор тестовых кодов и детектор ошибок. На рисунках 6.5 и 6.6 показаны схемы [14] для 3 Гбит/с генератора тестовых кодов и детектора ошибок. Вследствие высокой битовой скорости генерация последовательных PRBS и кодовых групп на этой скорости не представляется целесообразной. Поэтому тестовые коды генерируются (рисунок 6.5) как параллельные 16-битные кодовые группы при максимальной скорости 200 Мбит/с, используя затем выполненные по биполярной технологии регистраторы смещения и высокоемкостную память. Высокоскоростные схемы обычно выполняются на основе арсенид-галлиевых логических схем, преобразующих параллельные данные в последовательный поток на скорости до 3 Гбит/с.
Согласно данной схеме, вход синхросигнала генерируется синтезатором частоты, согласующее устройство управляется через линию фиксированной задержки, а генератор тестовых кодов и выходной усилитель синхронизируются через схему дискретной и плавно изменяемой задержки, так что фаза синхросигнала/данных может изменяться как в положительном направлении, так и в отрицательном. Дискретные значения задержки составляют 250, 500 и 1000 пс, тогда как диапазон плавной задержки лежит в пределах от 0 до 250 пс с 1 пс инкрементом.
Корректор временной диаграммы, связанный с выходным усилителем, пересинхронизирует данные через триггер D типа для поддержания минимального фазового дрожания. Так как подобный тип тестового устройства обычно используется при проведении лабораторных измерений, выходные уровни синхросигнала и данных и постоянные смещения могут варьироваться для того или иного конкретного случая использования.
Детектор ошибок, показанный на рис. 6.6, имеет простое параллельное соединение, в связи с чем входы синхросигнала и данных проходят через схемы дискретной и плавной задержки, обеспечивая оптимальную настройку при обнаружении ошибок для любой фазы синхросигнала/данных. Действительно, путем настройки под контролем внутреннего процессора решающего порога и фазы синхросигнала условия функционирования детектора ошибок могут быть оптимизированы автоматически. Высокоскоростной демультиплексор преобразует последовательный поток данных в 16-битные параллельные кодовые группы наряду с поделенным на 16 синхросигналом. Параллельно соединенный генератор эталонных тестовых кодов синхронизируется с входными данными и осуществляет сравнение битов, поэтому любая ошибка фиксируется одним из двух счетчиков, первый из которых подсчитывает число ошибок, а второй – общее число битов. Процессор измерения обеспечивает анализ функционирования при наличии ошибок с разрешением до 1 мс.
6.5. Техника измерения коэффициента ошибок
Рассмотрим измерение коэффициента ошибок путем посимвольного сравнения и подсчета ошибочно принятых элементарных импульсов. Для этого вначале (перед измерением) на передающей станции с помощью оптического аттенюатора устанавливают заданный в технических условиях на аппаратуру линейного тракта уровень оптического излучения. Затем на передающем конце подключают генератор испытательных сигналов, а на приемном – измеритель коэффициента ошибок и, изменяя значения уровней средней мощности, измеряют коэффициент ошибок. Время измерения определяют в зависимости от скорости передачи, объема информации и значений коэффициента ошибок Кошi (BERi).
Коэффициент ошибок при заданном уровне оптического излучения вычисляют по формуле [14]
![]() (6.17)
(6.17)
где
![]() , , (6.18)
, , (6.18)
где ![]() и
и ![]() — погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
— погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.