Привет, Вы узнаете про алгоритмы исправления опечаток, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка
, настоятельно рекомендую прочитать все из категории Обработка естественного языка.
Постановка задачи
Итак, нам пришел опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
- дано слово s, переданное нам с ошибками;
- есть словарь Σ правильных слов;
- для всех слов w в словаре есть условные вероятности P(w|s) того, что имелось в виду слово w, при условии, что получили мы слово s;
- нужно найти слово w из словаря с максимальной вероятностью P(w|s).
Эта постановка — самая элементарная — предполагает, что если нам пришел запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать P(w|s). Первый вопрос считается простым. В 1990 году словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!
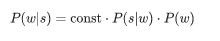
Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные: P(s|w) — вероятность того, что при наборе слова w можно опечататься и получить s, и P(w) — в принципе вероятность использования пользователем слова w.
Как оценить P(s|w)? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумленного канала; в нашем случае зашумленный канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model —
модель ошибок . Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учет как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова — P(w) — можно по-разному. Самый простой вариант — взять за нее частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — еще одна модель. Эта модель называется language model,
модель языка .
Системы автоматической коррекции орфографии
Мы предоставляем два типа конвейеров для исправления орфографии: levenshtein_corrector использует простое расстояние Дамерау-Левенштейна для поиска кандидатов на исправление, а brillmoore использует для него статистическую модель ошибок. В обоих случаях кандидаты на исправление выбираются на основе контекста с помощью языковой модели кенлм .
Сравнение автоматической коррекции орфографии для русского языка с использованием разлиных алгоритмов:
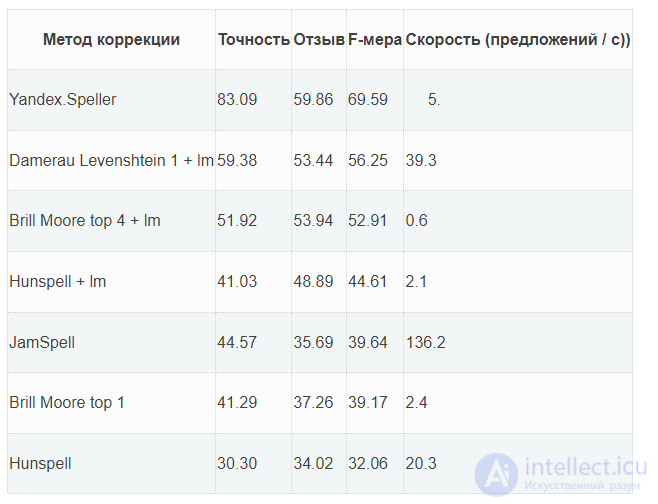
Алгоритмы для исправления опечаток без уета контекста
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в нее встраивают механизмы исправления ошибок.
Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления :
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трех. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики . Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше , несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов . Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Проверка качества работы
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).
Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.
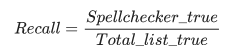
Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.
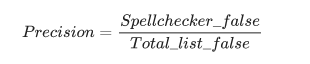
Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье , в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура , либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Модель ошибок
Первые модели ошибок считали P(s|w), подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее . Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром и многократно использованной впоследствии (например, специалистами Google ). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим P(тся→ться) — это параметр нашей модели. Если для всех возможных фрагментов α,β мы можем посчитать P(α→β), то искомую вероятность P(s|w) набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины P(s|w):

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:
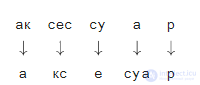
Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины P(ак→а) и P(р→р) еще не так плохи, то P(су→е) и P(а→суа), скорее всего, сделают итоговый «счет» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь все сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной 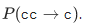 .
.
Как вычислить P(s|w)
Несмотря на то, что возможных разбиений для двух слов имеется порядка 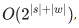 , с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за
, с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за 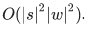 . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведем прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы ее вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие P(α→β). Например, если у нас заполнена таблица
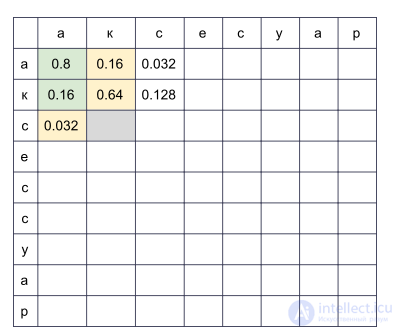
, то для заполнения ячейки в четвертой строке и третьем столбце (серая) нужно взять максимум из величин 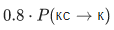 и
и 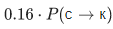 . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет 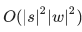 : мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до
: мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до 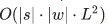 . Для русского языка в своих экспериментах я брал L=3.
. Для русского языка в своих экспериментах я брал L=3.
Как максимизировать P(s|w)
Мы научились находить P(s|w) за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всем словаре. Причем наилучшие не по P(s|w), а по P(w|s)! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по P(s|w), который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить ее для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмем словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд . А кэширование результатов сделает процесс еще быстрее.
Как получить P(α→β)
Вычисление P(α→β) для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть ее качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдем много пар (si,wi), где wi — правильное слово из словаря, а si — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмем составляющие ее w и s и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:
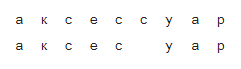
Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее . Об этом говорит сайт https://intellect.icu . Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причем каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам (si,wi) за вероятность P(α→β) принимается количество замен α → β, встретившихся в наших парах (с учетом встречаемости соответствующих слов), деленное на количество повторений фрагмента α.
Как найти пары (si,wi)? В предлагается такой подход. Возьмем большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмем за w, менее популярное — за s. Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В предлагается только фильтр по встречаемости (w в десять раз популярнее, чем s), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом w, найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчетов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трех слов).
Модель языка
Итак, теперь для заданного словарного слова w нам нужно вычислить P(w) — вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчета встречаемости слов в нем. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления P(w1w2…wk), где одно из wi — слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем P(w), а остальные wi — слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу еще раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут все зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы w1w2…wk ее вероятность вычисляется по формуле
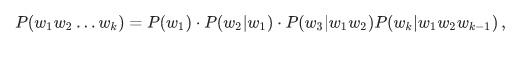
где P(w1) — непосредственно частота слова, а P(w3|w1w2) — вероятность слова w3 при условии, что перед ним идут w1w2 — не что иное, как отношение частоты триграммы w1w2w3 к частоте биграммы w1w2. (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить мамамыларамуP(мама мыла раму), обозначив частоту произвольной n-граммы за f, мы получим формулу
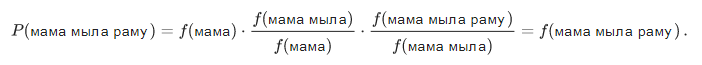
Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввел впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что
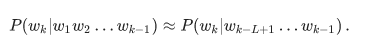
Положив L=3, для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трех. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввел совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить f=0, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьезных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Как исправлять фразы
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в . Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчет первого из них придется, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова si в нашей фразе найдем с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из NK получившихся фраз, где K — количество слов в исходной фразе, посчитаем честно величину
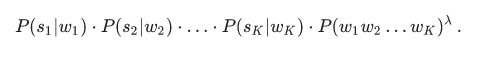
Здесь si — слова, введенные пользователем, wi — подобранные для них исправления (которые мы сейчас перебираем), а λ — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в . Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и еще домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор NK фраз?
К счастью, за счет того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для P(w1w2…wK) так, что она стала зависеть только от частот n-грамм длины не выше трех:
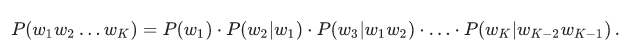
Если мы домножим эту величину на 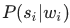 и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
Реализация алгоритма исправления ошибок
Собираем корпус и считаем n-граммы
Сразу оговорюсь: данных в моем распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трех символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r»^[a-z0-9]{2}$» — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчете биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадет в словарь…).
Обучаем модель ошибок
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
Код на Python
короткие правки вида сс → с (под спойлером).
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчета
# расстояния восстановить оптимальное расположение букв, будем
# хранить впродолжение следует…
Продолжение:
Часть 1 Алгоритмы исправления опечаток с и без учёта контекста
Часть 2 Результаты — Алгоритмы исправления опечаток с и без учёта контекста
См.также
- Фильтр Блума
- Расстояние Дамерау-Левенштейна
- metaphone , soundex , approximate string matching , fuzzy string searching ,
- инвертированный индекс , расстояние левенштейна , расстояние редактирования , редакционным расстоянием ,
В общем, мой друг ты одолел чтение этой статьи об алгоритмы исправления опечаток. Работы в переди у тебя будет много. Смело пишикоментарии, развивайся и счастье окажется в ваших руках.
Надеюсь, что теперь ты понял что такое алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Обработка естественного языка

Разновидности ошибок
Чтобы понимать, что представляют собой такие нарушения речи, важно видеть разницу. Существует несколько видов ошибок, которые отличаются в зависимости от неверных формулировок, неправильного использования времен глаголов, построения предложения в целом и много другого.
Нарушения структуры сочетания слов:

- неправильное использование правил согласования;
- неверное применение способов синтаксического управления;
- ошибки при выборе падежных окончаний;
- немотивированное употребление предлогов;
- использования предлогов там, где они неуместны;
- пропуск зависимого члена в составной структуре.
Построение блоков с потерей смысловой нагрузки:
- Сказуемое и подлежащее не имеют логической связи.
- Составление незаконченных самостоятельных единиц текста.
- Построение предложений, где любая из частей может обладать господствующим значением (двузначность).
- Неправильное сопоставление времен глаголов.
Неверное формирование простых двусоставных структур:

- Повторное указание подлежащего с помощью местоимения.
- Несогласованность местоимения и подлежащего во взаимосвязанных образованиях.
- Замена сказуемого на прилагательное.
- Отсутствие родовой и числительной связи между подлежащим и сказуемым.
- Некорректное использование нескольких местоимений, обозначающих подлежащее.
- Неверное употребление определений без их согласования.
- Неуместное применение большого количества определений обоих видов.
- Искажение формы обстоятельства при указании места действия.
Неправильное построение предложений с одним главным членом:
- Употребление двух главных членов в односоставной конструкции.
- Применение деепричастных словосочетаний в конструкции, описывающей независимое действие или обстоятельство.
- Ошибочное использование различных по свойствам классов речи в качестве однородных членов.
- Употребление разнородных определений как однородных частей предложения.
- Неверный выбор союзов для объединения однородных членов.
- Ошибочное образование взаимосвязи между главным и второстепенными членами.
- Отсутствие логической связи между подлежащим и сказуемым.
- Использование разнородных сказуемых как однородных частей.
- Разночтение падежных окончаний именных сказуемых.
Ошибки при образовании вводных слов и композиций:
- использование вводной конструкции в качестве самостоятельного элемента;
- некорректный подбор вводного слова;
- применение вводных композиций, приводящих к возможности двойственного толкования.
Построение неверных конструкций с синтаксически самостоятельными членами:

- Разрыв связи между причастием и словом, которое оно определяет.
- Объединение определения и причастной конструкции.
- Использование блока придаточного типа в качестве причастного оборота.
- Применение деепричастной конструкции как причастного оборота.
- Нарушение построения предложений с обстоятельствами, обладающими изолированными определениями, которые описываются с помощью деепричастия.
Ошибки при отображении прямой и косвенной речи:
- Совместное употребление прямой и авторской речи в одном образовании.
- Отсутствие вводной конструкции от автора при использовании прямой речи.
- Неуместное связывание своего и чужого повествования в одном блоке.
- Неверное формулирование при цитировании высказываний.
Неправильное формирование композиций с несколькими главными членами:

- Смысловые несоответствия грамматического сочетания в сложносочинённых конструкциях.
- Вставка местоимений во вторую половину сложносочинённого блока.
- Неверный выбор соединительного союза для образования взаимосвязи между составляющими сложносочинённого блока.
- Неверный выбор противительного союза.
- Некорректное введение дополнительных и повторяющихся союзов.
- Немотивированное применение одинаковых союзов в одном предложении.
- Ошибочный подбор союза.
Неверное составление конструкций сложноподчинённого типа:
- неправильное сочетание главной и зависимой частей;
- увеличение объема из-за неоправданного количества подчиненных сегментов;
- отсутствие указательного блока;
- выделение зависимой части композиции в самостоятельную единицу текста;
- вставка неуместного указательного оборота;
- разрыв смыслового значения между заместительным союзом подчинённой части и определением в основной части;
- неверное местоположение союзного слова в зависимом предложении;
- неоправданное употребление нескольких зависимых конструкций одного типа.
Ошибочное составление сложных блоков без союзов и союзных слов:

- Отсутствие взаимосвязи между отдельными частями бессоюзного образования сложного вида.
- Употребление частей сложной бессоюзной конструкции как самостоятельных единиц текста.
- Смешение союзных и бессоюзных способов образования сложных структур.
Неправильное формирование сложных блоков с применением связующих способов разного типа:
- Искаженная последовательность элементов сложной конструкции.
- Нарушение взаимосвязи составляющих сложного предложения из-за некорректной вставки местоимений.
Чтобы исключить из текста или речи ошибки такого рода, нужно знать и применять на практике установленные нормы и правила.
Способы исправления
Для того чтобы знать, как исправить синтаксическую ошибку, нужно провести тщательный анализ текста. Выявив смысловые провалы и логические несоответствия, можно приступать устранению несоответствий содержания грамматическим нормам русского языка.
Номера в списке исправления ошибок соответствуют порядку в перечне «Разновидности ошибок»
Список методов исправления ошибок:


- Соблюдать грамматически верную расстановку слов во всех видах предложений.
- Построение структуры без нарушения ее границ, с логически верным внутренним содержанием.
- Формируя двусоставные единицы, правильно использовать местоимения, не заменять сказуемые прилагательными. Не нарушать связи между частями предложения. Применять определения без потери смысловой нагрузки. Корректно согласовывать сказуемое и подлежащее, учитывая число и род.
- Запрещается составлять односоставные композиции по типу двусоставных моделей и вставлять деепричастные словосочетания без указания лица действия.
- Нельзя использовать вводные слова и конструкции как самостоятельные части речи.
- Правильно составлять причастные блоки и следить за логической последовательностью их в предложении.
- Грамматически верно сочетать прямую и косвенную речь.
- Соблюдение смысловых связей между составляющими сложных структур. Правильное употребление союзов сложносочинённого типа.
- Следить за смысловой и грамматической взаимосвязью частей. Избегать ненужного увеличение объема и не использовать подчиненные составляющие как самостоятельные элементы текста.
- Применять только принципы образования бессоюзных конструкций и воздерживаться от потери смысловой связи между сегментами.
Кроме того, нельзя допускать нарушение логической последовательности частей при образовании сложных элементов текста.
Примеры допущенных погрешностей
Наглядные модели предложений, содержащих синтаксические нарушения, помогают более глубоко понять правила русского языка и не позволяют допустить погрешность.
Синтаксические ошибки, примеры:

- Типичное нарушение структуры сочетания слов: Прошедшее зимой он гулял по берегу озера.
- Нарушение смысловой структуры: Снегопад уже начиналась, когда туристы возвращались в лагерь.
- Неверный порядок следования частей простого двусоставного образования: Облака, собравшиеся в грозовую тучу, они готовы разразиться дождем.
- Неправильное построение односоставного образования: Лес нам понравился, потому что в нем интересно, красивый и загадочный.
- Неверная постановка вводного слова: Люди с нетерпением поглядывали на часы, наверное, из-за поворота появится автобус.
- Ошибочный состав конструкции с синтаксически самостоятельными членами: Ребенку вручили подарки: он распечатал, красиво упакованные.
- Ошибки при отображении речевых выражений прямого и косвенного порядка: После остановки проводник крикнул: «Все пассажиры, на выход и первым покинул троллейбус».
- Неправильно сформированная композиция с несколькими главными членами: Ее собака любила играть с резиновым мячом, но она убежала.
- Неверное образование сложноподчинённой композиции: Они всё-таки смогут купаться, потому что дети должны уметь плавать.
- Отсутствие единообразия составляющих сложной бессоюзной структуры и неправильная расстановка знаков препинания: На фестивале показано интересное, представление играют актеры.
- Отсутствие правильной последовательности при формировании сложного образования: Ветер еще дует, но уже не так сильно, поэтому остается надежда, что рыбаки выживут, небо проясняется.
Виды синтаксических ошибок и способы их исправления можно изучить более подробно по многочисленным таблицам, широко представленным в специализированной литературе, а также пройти пробное задание.
Содержание
- Синтаксические ошибки
- Синтаксические нормы и ошибки употребления
- Типы синтаксических ошибок
- Типичные ошибки в русском языке: грамматические, речевые и орфографические
- Самые распространенные ошибки в ЕГЭ по русскому языку:
- Грамматические ошибки
- Виды грамматических ошибок:
- Речевые ошибки
- Виды речевых ошибок:
- Типичные речевые ошибки (К10)
- К наиболее частотным речевым ошибкам относятся:
- Логические ошибки
- Фактические ошибки
- Орфографические, пунктуационные, графические ошибки
- Нормы синтаксиса в русской речи
- Нарушение синтаксических норм
- Нормы управления
- Употребление предлогов
- Употребление предложений с однородными членами
- Употребление деепричастных оборотов
- Употребление сложноподчинённых предложений
- Разновидности ошибок
- Способы исправления
- Примеры допущенных погрешностей
Синтаксические ошибки
Синтаксические ошибки заключаются в неверном построении словосочетаний, в нарушении структуры простых, осложненных и сложных предложений.
Ошибки в структуре словосочетаний :
Нарушение согласования с главным словом в роде, числе и падеже слова зависимого, выраженного прилагательным, причастием, порядковым числительным, местоимением: » Нынешнее летом я был в степном Заволжье «.
Неправильный выбор падежа при правильно выбранном предлоге: » Он был похож на смертельно усталым человеком «.
Пропуск предлога: » Пообедав торопливо, сел за штурвал, поехал (?) поле «.
Употребление лишнего предлога » Жажда к славе «.
Пропуск зависимого компонента словосочетания: » Снова садиться в жаркую кабину, снова крутить лоснящийся от ладоней штурвал, (?) ехать «.
Нарушение связи между подлежащим и сказуемым: » Но не вечно ни юность, ни лето «, » Солнце уже села, когда мы вернулись «.
Синтаксическая двузначность: » Их (девочек) мечта сбылась, они (рыбаки) вернулись «.
Нарушение видовременной соотнесенности глаголов в составе предложения: » Гринев видит, как Пугачев садился в карету «.
Подлежащее :
— Местоименное дублирование подлежащего: » Дети, сидящие на старой опрокинутой вверх килем лодке, они ждут своего отца «.
— Нарушение согласования подлежащего и местоимения, заменяющего подлежащее в другом предложении: » Видимо, на море шторм, поэтому он полон опасностей «.
Сказуемое :
— Ошибки в конструировании сказуемого: » Все были счастливые «.
— Нарушение согласования сказуемого в роде и числе с подлежащим, выраженным собирательными существительным, количественно-именным словосочетанием, вопросительным и неопределенным местоимением: » Я с мамой остались дома «, » В комнату проникли сноп лучей солнца «.
— Местоименное дублирование дополнения: » Многие книги их можно читать несколько раз «.
Определение :
— Неправильное использование несогласованного определения: » Справа висят светильник и мой портрет из садика «.
— Нагромождение согласованных и не согласованных определений, относящихся к одному члену предложения: » Огромный, прекрасный мир жизни нашей страны и наших сверстников открывается в миллионах книг «.
— Неверный выбор морфологической формы обстоятельства: » Я учу уроки на столе » (за столом).
Использование деепричастного оборота в безличном предложении: » Увидев собаку, мне стало жаль ее «.
Источник
Синтаксические нормы и ошибки употребления
Синтаксические нормы языка — это нормы построения словосочетания и предложения.
Такие нормы связаны, например,
не видеть ошибку — не видеть ошибки
(Нормативно переходные глаголы при отрицании требуют постановки существительного в Р.п.), т.е. нормативным будет вариант — не видеть ошибок,
Созданный Лермонтовым роман дает представление о герое нашего времени или Роман, созданный Лермонтовым, дает представление о герое нашего времени;
 Приехав работать в маленький город, люди ему посоветовали посетить семью Туркиных.
Приехав работать в маленький город, люди ему посоветовали посетить семью Туркиных.
По правилам деепричастие обозначает действие подлежащего, т.е. следует написать: Когда Старцев приехал работать в маленький город, люди посоветовали ему посетить семью Туркиных;
Чехов был знаменитым прозаиком и новеллистом.
Нормативно нельзя соединять в качестве однородных членов родовое и видовое понятия: слово прозаик является родовым (более широким по значению) по отношению к слову новеллист, т.е. нужно было написать: Чехов был знаменитым прозаиком.
Первое, на что хочу обратить внимание, — это на экономическом положении.
(По синтаксическим нормам сказуемое, выраженное существительным, употребляется в Им.п.)
Правильным будет предложение: Первое, на что хочу обратить внимание, — это экономическое положение
Типы синтаксических ошибок
Наиболее характерные нарушения здесь — это:
На стендах представлены афиши о выступлениях писателя на немецком, французском, чешском, польском языках.
(Нужно: На стендах представлены афиши на немецком,французском, чешском, польском языках о выступлениях писателя.)
В первом варианте неверный порядок слов создавал двусмысленность,
а) употребление управляемого слова не в том падеже, которого требует управляющее слово:
О том, каких результатов мы добились, показано в таблице № 1.
(Краткое причастие показано требует, чтобы управляемое слово стояло в В.п.) Правильный вариант: То, каких результатов мы добились, показано в таблице № 1)
б) нарушение управления при синонимичных словах
— уверенность в победу.
Синонимичные слова уверенность — вера требуют постановки слова в разных падежах: уверенность (в чем?) в победе, вера (во что?) в победу;
в) нарушение управления при однородных членах предложения
— покрывает и потворствует дурным наклонностям.
Однородные члены предложения требуют от управляемого слова разных падежей: покрывает (что?) дурные наклонности и потворствует (чему? )им;
г) нанизывание падежей
— располагает составленным агентом списком.
(Употребление цепочки зависимых слов в одном и том же падеже создает двусмысленность: имеет список, составленный агентом).
а) неверное соединение
б) двусмысленность из-за возможности отнести один из однородных членов в другой ряд:
Слушатели желали писателю избавления от болезней и здоровья.;
из-за несочетаемости одного из однородных членов с другими словами: окружить вниманием и помощью (можно: окружить вниманием, нельзя — окружить помощью);
в) неверное употребление предлогов и союзов при однородных членах предложения:
детский комплекс на Черном море и Подмосковье — нужно: на Черном море и в Подмосковье;
прочитал не только книги, но и законспектировал их, — нужно: не только прочитал, но и ….
а) неверная форма причастия (не учтены вид, время, залог или падежная форма):
по пути, начертанном великим Глинкой (в данном случае неверна падежная форма причастия: по пути (какому? ) начертанному;
б) неверный порядок слов:
На столе лежала отредактированная рукопись редактором.
Нужно: Рукопись, отредактированная редактором,… или отредактированная редактором рукопись.
а) не учитывается вид деепричастия:
Подъезжая к реке, мы остановили лошадей и бросились в воду.
Нужно: Подъехав к реке, мы остановили лошадей и бросились в воду.
б) не учитывается, что действие деепричастия относится к действию подлежащего:
Подбежав к станции, поезд уже отошел. Приехав в город, было еще темно.
Нужно: Когда мы подбежали к станции, поезд уже отошел. Когда мы приехали в город, было еще темно.
а) загромождение предложения однотипными придаточными:
Он высказал предположение, что его неверно поняли читатели, сказав, что ему представляется совершенно иная трактовка событий.
Нужно: Он высказал предположения, что его неверно поняли читатели, потому что он совершенно иначе представляет трактовку событий.
б) разнотипность частей сложного предложения:
Необходимо помнить, что нужно: 1) оставлять места для заметок, 2) обязательно оформлять сноски, 3) размещение списка литературы по алфавиту.
Нужно: Необходимо помнить, что нужно: 1) оставлять места для заметок, 2) обязательно оформлять сноски, 3)размещать список литературы по алфавиту.
в) смещение конструкции:
Главное, на чем настаивал оратор, — это на учете фактора адресата.
Нужно: Главное, на чем настаивал оратор, — это учет фактора адресата.
г) неверное употребление союзов и союзных слов:
Но однако тем не менее мы должны сказать.
Нужно: Но тем не менее мы должны сказать.
д) неправильный порядок слов в сложном предложении:
Перед нами были лошади казаков, морды которых были в пене.
Нужно: Перед нами были казачьи лошади, морды которых были в пене.
Наша презентация
Предлагаем разгадать онлайн кроссворд и видекроссворд по речевым ошибкам — здесь
Источник
Типичные ошибки в русском языке: грамматические, речевые и орфографические
Самые распространенные ошибки в ЕГЭ по русскому языку:
Классификация ошибок по ФИПИ
Грамматические ошибки
Грамматическая ошибка – это ошибка в структуре языковой единицы: в структуре слова, словосочетания или предложения; это нарушение какой-либо грамматической нормы: словообразовательной, морфологической, синтаксической.
В отличие от грамматических, речевые ошибки – это ошибки не в построении, не в структуре языковой единицы, а в ее использовании, чаще всего в употреблении слова. По преимуществу это нарушения лексических норм, например:
Речевую ошибку можно заметить только в контексте, в этом ее отличие от ошибки грамматической, для обнаружения которой контекст не нужен.
Ниже приводятся общепринятые классификаторы грамматических и речевых ошибок.
Виды грамматических ошибок:
Речевые ошибки
Виды речевых ошибок:
Это ошибки, связанные с употреблением глагола, глагольных форм, наречий, частиц:
Эти ошибки связаны обычно с нарушением закономерностей и правил грамматики и возникают под влиянием просторечия и диалектов.
К типичным можно отнести и грамматико-синтаксические ошибки:
Типичные речевые ошибки (К10)
Это нарушения, связанные с неразвитостью речи: плеоназм, тавтология, речевые штампы; немотивированное использование просторечной лексики, диалектизмов, жаргонизмов; неудачное использование экспрессивных средств, канцелярит, неразличение (смешение) паронимов; ошибки в употреблении омонимов, антонимов, синонимов; не устраненная контекстом многозначность.
К наиболее частотным речевым ошибкам относятся:
Логические ошибки
Логические ошибки связаны с нарушением логической правильности речи. Они возникают в результате нарушения законов логики, допущенного как в пределах одного предложения, суждения, так и на уровне целого текста.
Композиционно-текстовые ошибки
Фактические ошибки
Орфографические, пунктуационные, графические ошибки
При проверке грамотности (К7-К8) учитываются ошибки
Необходимо учитывать также повторяемость и однотипность ошибок. Если ошибка повторяется в одном и том же слове или в корне однокоренных слов, то она считается за одну ошибку.
Графические ошибки – различные приемы сокращения слов, использование пробелов между словами, различных подчеркиваний и шрифтовых выделений. К ним относятся: различные описки и опечатки, вызванные невнимательностью пишущего или поспешностью написания.
Распространенные графические ошибки:
Источник
Нормы синтаксиса в русской речи
Синтаксические нормы требуют правильного построения основных синтаксических единиц — словосочетаний и предложений. Эти нормы включают правила согласования слов, соотнесения частей предложения с помощью грамматических форм слов.

В синтаксические нормы входят правила по согласованию частей речи и синтаксическому управлению, а также соотношения частей предложения между собой. Именно соблюдения этих правил является важным условием построения грамотного осмысленного предложения.
Нарушение синтаксических норм
Синтаксические нормы русского языка – это набор правил, которые регулируют составление предложений и словосочетаний, которое является одним из самых важных условий правильной устной и письменной речи.
Нарушение синтаксических норм есть в следующих примерах:
Чтобы получить представление о важности изучения синтаксических норм, можно привести лишь несколько самых распространенных нарушений синтаксических норм:
При построении словосочетаний используются связи управление, согласование и примыкание.
Нормы управления
Управление — это вид подчинительной связи, при которой зависимое слово ставится в определённом падеже.
Например, в предложении Разрешите поздравить и выразить вам свою признательность сделана ошибка в управлении при употреблении однородных членов. Первое сказуемое не согласуется с дополнением вам. Правильно так: Разрешите поздравить (кого?) вас и выразить (кому?) вам свою признательность.
Несогласованность часто наблюдается в предложениях с причастными оборотами: с некоторыми словосочетаниями, приведённых в упражнении, надо было составить предложения. Правильно так: с некоторыми словосочетаниями (какими?), приведёнными в упражнении, надо было составить предложения.
Читайте также стих Пушкина «Памятник» – один из самых знаменитых.
Употребление предлогов
Предлоги благодаря, согласно, вопреки требуют дательного падежа: Поезд отправился в рейс согласно расписанию. Согласно договору исполнителем должны быть выполнены следующие виды работ. Он действовал вопреки предписанию.
Запомните формы существительных с предлогом по: по истечении, по окончании, по заключении; по приезде сдайте отчёт о командировке, скучаю по вас (допустимо: по вам).
Употребление предложений с однородными членами
Ошибочно употребление в качестве однородных членов полной и краткой форм прилагательного: Деревья высокие и стройны. Нужно говорить: Деревья высоки и стройны (высокие и стройные).
Ошибочно употребление в качестве однородных членов существительного и инфинитива: Прошу тишины и выслушать меня. Нужно говорить: Прошу тишины и внимания.
Употребление деепричастных оборотов
Деепричастные обороты не употребляются:
Ошибка: Заглянув в тёмную комнату, мне стало почему-то страшно. Правильно: Заглянув в тёмную комнату, я почему-то испугался.
Ошибка: Анализируя стихотворный текст, мной был неверно определён размер. Правильно: Анализируя стихотворный текст, я неверно определил размер.
Действия, выраженные глаголом-сказуемым и связанным с ним деепричастием, должны относиться к одному лицу или предмету.
Ошибка: Поднявшись по крутому склону горы, перед нами открылся великолепный вид на море. Правильно: Когда мы поднялись по крутому склону горы, перед нами открылся великолепный вид на море.
Употребление сложноподчинённых предложений
Ошибочно одновременно использовать в сложноподчинённом предложении синонимичные союзы:
Ошибка: В этом году наша команда подготовилась к соревнования лучше, чем нежели в прошлом. Правильно: В этом году наша команда подготовилась к соревнованиям лучше, чем (или нежели) в прошлом.
При последовательном подчинении следует избегать повторения одинаковых союзов, если это не оправдано стилистически:
Ошибка: Дай мне солонку, которая находится в буфете, который стоит на кухне. Правильно: Дай мне солонку, которая находится в буфете, что стоит на кухне.
Определительное придаточное с союзным словом который не должно отрываться от определяемого слова в главном предложении:
Ошибка: Из путешествий по разным странам, которые он совершал на автомобиле, он всегда привозил сувениры. Правильно: Из путешествий, которые он совершал на автомобиле по разным странам, он всегда привозил сувениры.
Допускаются ошибки в предложениях с косвенной речью. Заменяя прямую речь косвенной, нужно помнить, что это разные конструкции. Необходимо заменять формы первого лица подлежащего и глагола-сказуемого и правильно выбирать средства связи частей предложения: Лермонтов писал: «Люблю отчизну я…» — Лермонтов писал, что он любит отчизну. Она спросила: «Ты придёшь?» — Она спросила, приду ли я.
Таким образом, синтаксические нормы русского литературного языка регламентируют построение словосочетаний и предложений. Ошибки чаще всего связаны с неправильным выбором управляемой формы в словосочетании, нарушением согласования подлежащего и сказуемого, использованием причастных и деепричастных оборотов, а также построением некоторых типов сложных предложений.
Источник
Разновидности ошибок
Чтобы понимать, что представляют собой такие нарушения речи, важно видеть разницу. Существует несколько видов ошибок, которые отличаются в зависимости от неверных формулировок, неправильного использования времен глаголов, построения предложения в целом и много другого.
Нарушения структуры сочетания слов:
Построение блоков с потерей смысловой нагрузки:
Неверное формирование простых двусоставных структур:
Неправильное построение предложений с одним главным членом:
Ошибки при образовании вводных слов и композиций:
Построение неверных конструкций с синтаксически самостоятельными членами:
Ошибки при отображении прямой и косвенной речи:
Неправильное формирование композиций с несколькими главными членами:
Неверное составление конструкций сложноподчинённого типа:
Ошибочное составление сложных блоков без союзов и союзных слов:
Неправильное формирование сложных блоков с применением связующих способов разного типа:
Чтобы исключить из текста или речи ошибки такого рода, нужно знать и применять на практике установленные нормы и правила.
Способы исправления
Для того чтобы знать, как исправить синтаксическую ошибку, нужно провести тщательный анализ текста. Выявив смысловые провалы и логические несоответствия, можно приступать устранению несоответствий содержания грамматическим нормам русского языка.
Номера в списке исправления ошибок соответствуют порядку в перечне «Разновидности ошибок»
Список методов исправления ошибок:
Кроме того, нельзя допускать нарушение логической последовательности частей при образовании сложных элементов текста.
Примеры допущенных погрешностей
Наглядные модели предложений, содержащих синтаксические нарушения, помогают более глубоко понять правила русского языка и не позволяют допустить погрешность.
Синтаксические ошибки, примеры:
Виды синтаксических ошибок и способы их исправления можно изучить более подробно по многочисленным таблицам, широко представленным в специализированной литературе, а также пройти пробное задание.
Источник

228
Ошибка в виде пропуска или неправильного употребления, допущенная на более раннем этапе, может проявиться совсем в другом месте программы. Это можно проиллюстрировать следующим примером.
while x>y ; begin something end.
Никакого сообщения об ошибке при встрече «;» на данной стадии синтаксический анализатор не выдаст. Последствия ее могут появиться на более поздней фазе анализа.
Сообщив о синтаксической ошибке, анализатор в большинстве случаев постарается продолжить разбор. Для этого ему понадобится исключить какие-либо символы, включить какие-либо символы или изменить их. Существует ряд стратегий исправления ошибок. Практически все они хорошо срабатывают в одних случаях и плохо – в других. «Хорошая» стратегия заключается в том, чтобы обнаружить как
можно больше синтаксических ошибок и генерировать как можно меньше сообщений в связи с каждой синтаксической ошибкой. Обычно наилучшими методами являются методы, зависимые от языка, т.е.
от знания исходного языка и от того, как он употребляется.
Режим переполоха
Один их наиболее распространенных методов исправления синтаксических ошибок носит названиережим переполоха. При появлении недопустимого символа весь последующий исходный текст, вплоть до соответствующего ограничителя (например «;» или end), игнорируется. Ограничитель заканчивает какую-то конструкцию языка, и элементы удаляются из стека разбора до тех пор, пока не встретится адрес возврата. Этот элемент тоже удаляется из стека, а разбор продолжается, начиная с адреса в таблице разбора, содержащего следующий входной символ. Такой метод довольно легко реализуется, но имеет серьезный недостаток: длинные последовательности кода, соответствующие игнорируемым символам, не анализируются.
Исключение символов
Этот метод также легко реализуется и не требует изменения степени разбора. Когда считывается недопустимый символ, и он сам, и все последующие символы исключаются из исходной строки до тех пор, пока не встретится допустимый символ. Хотя при таком методе могут исключаться длинные последовательности, в отдельных случаях он весьма эффективен. Например, в
c := d+3; end,
229
где «;» является недопустимой, исправление ошибки – идеальное. Однако исключение скобок обычно разрушает блочную структуру и приводит к дальнейшим синтаксическим ошибкам.
Включение символов
Некоторые синтаксические анализаторы имеют наготове множество действительных символов продолжения. В некоторых случаях оп-
равдано исправление программ путем подстановки одного из таких символов перед недопустимым символом, который вызвал ошибку. Например, последовательность
end begin
никогда не будет допустимой. Однако включение «;» между end begin позволит анализатору продолжить работу.
Конечно, в таких ситуациях может иметь место неправильная подстановка, даже если анализатор продолжит работу.
Правила для ошибок
Одним из способов исправления некоторых типов синтаксических ошибок заключается в расширении синтаксиса языка за счет включения в него программ, содержащих типичные ошибки. Это не значит, что ошибки пройдут незамеченными, так как в грамматику могут быть включены сообщения о них. Но анализатор не будет считать такой вход недопустимым и не потребует никаких исправлений. Так можно обращаться, например, с ошибками типа«;» перед end или пропуск «;». Дополнительные правила, включенные в грамматику, обычно называются правилами для ошибок. Они неизбежно приводят к увеличению грамматики, и поэтому включать их следует только для наиболее часто встречающихся ошибок программирования. При этом надо следить за тем, чтобы при включении этих правил грамматика не стала неоднозначной.
11.6. Предупреждения
Наряду с сообщениями о синтаксических ошибках анализатор может выдавать предупреждения, когда ему встретилась допустимая, но маловероятная последовательность символов, например
; do
Еще чаще такие ситуации возникают, когда в таблице идентификаторов содержится переменная, но ссылки в программе на нее нет. Для
230
выдачи сообщений о таких ситуациях в грамматику вводятся действия, идентифицирующие их.
11.7. Сообщения о синтаксических ошибках
Всякий раз при обнаружении анализатором синтаксической ошибки должно печататься соответствующее сообщение. Например
SYNTAX ERROR IN LINE 22.
Или местоположение ошибки может описываться полнее
LINE 22 SYMBOL 4.
В любом случае пользователь может быть недоволен тем, что сообщение не вполне ясное, так как не указывается, в чем заключается ошибка программиста. На практике фактическая ошибка программирования могла произойти гораздо раньше, анализатор же сообщает об ошибке только тогда, когда ему встречается недопустимый символ. Если программист представляет анализатору программу, имеющую синтаксическую ошибку, компилятор, естественно, не сможет решить, какую программу программист должен был написать. Единственное, что компилятор смог бы сделать, это принять решение о «ремонте» на минимальном расстоянии, т.е. о ремонте, требующем минимальное число включений символов в текст программы и исключений из него, дающем синтаксически правильную программу. Цель ремонта – обеспечить анализатору условия для продолжения анализа программы.
Хотя теоретически ремонт на минимальном расстоянии кажется привлекательным, его реализация неэффективна, так как приходится часто возвращаться назад по уже проанализированным частям -про граммы и отменять выполненные компилятором ранее действия. Большинство компиляторов не берется за такой ремонт. Единственное исправление, которое они осуществляют, — это вставка, исключение или изменение символовв том месте, где обнаружена ошибка. В
этом случае компилятор не может предоставить иной информации, кроме точного указания о том, где обнаружена ошибка. Компилятору может быть известен еще и контекст, в котором обнаружена ошибка; например, она могла произойти в пределах присвоения, границах массива или в вызове процедуры. Такая информация не всегда оказывается полезной для пользователя, но она показывает, какой тип конструкции пытался распознать анализатор, когда обнаружил ошибку, а это поможет найти фактическую ошибку программирования. Можно также сообщить пользователю, какие символы допустимы при встрече недопустимого символа. Если анализатор способен сделать разумное предположение о том, какая фактическая ошибка программирования
231
была допущена, он может исправить программу для последующих проходов.
Для исправления программы (но не ремонта) необходимо знать истинные намерения программиста. В общем случае это невозможно, однако для КС-языков многие типы ошибок можно локализовать достаточно точно.
11.8. Контекстно-зависимые ошибки
Некоторые конструкции типичных языков программирования нельзя описать с помощью контекстно-свободной грамматики. Следовательно, с точки зрения таблицы разбора программы с неописанными идентификаторами синтаксически правильны. Такие контекстнозависимые ошибки могут быть обнаружены действиями, включаемыми в контекстно-свободную грамматику и вызываемыми анализатором,
который запрашивает таблицу символов. Об ошибках такого рода обычно выдаются четкие сообщения при анализе таблицы идентификаторов, например
IDENTIFIER xyz NOT DECLARED TYPE NOT COMPATIBLE ASSIGNMENT
Так как сам анализатор ошибку не обнаружил, никакого исправления не требуется. Однако, если не принять соответствующие меры, то одна ошибка может повлечь за собой лавину сообщений об ошибках. Во избежание этого при первом же появлении неописанного идентификатора он должен включаться в таблицу символов. В таблицу также должен помещаться тип, соответствующий неописанному идентификатору. Компилятор в этом случае обладает недостаточной информацией, чтобы решить какой тип идентификатора предполагается, поэтому многие компиляторы принимают стандартный типint или real. Лучше всего иметь для этого специальный типsptype, который будет ассоциироваться с такими идентификаторами; sptype обладает следующими свойствами:
1)его можно приводит к любому типу/виду;
2)если значение типа sptype оказывается операндом, знак операции идентифицируется с помощью другого операнда, причем любая неоднозначность разрешается произвольно;
3)применительно к анализатору значение типа sptype выбирается или вырезается, хотя при этом выдача соответствующего кода может быть невозможной.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В данной работе вы найдёте ответы на следующие вопросы:
- Лексический анализатор, если для данного входного текста (цепочки) и положения указателя в этом тексте анализатор определяет лексему, расположенную непосредственно справа от указанного места, и сдвигает указатель вправо от части текста, образующего лексему, работает
- Степень отношения R на множестве A определяется как…
- Распространенными видами промежуточного кода являются…
- Если идентификатор при построении таблицы имен не может быть внесен в позицию, задаваемую функцией хеширования, такая ситуация называется…
- Объединение при выполнении приведения типов – это, например, переход…
- Для задания алгоритмов используются формализмы…
- Предикат, описывающий пересечение множеств A и B…
- Синтаксические позиции, в которых выполняется приведение, могут называться…
- Поставьте в соответствие компоненты грамматики с их описаниями, чтобы утверждение было истинным.
- Является ли грамматика, описанная данными правилами, LR(1)-грамматикой?
- Программа, определяющая поведение распознавателя, называется … устройством.
- К методам исправления контекстно-независимых синтаксических ошибок относят…
- Укажите основные свойства языков программирования, которые учитываются при построении таблицы имен.
- При оптимизации кода последовательность команд «LOAD α; MPY β» можно…
- Графы G1 = (A1, R1) и G2 = (A2, R2) являются равными помеченными графами, если существует такое биективное отображение h: A1→A2, что…
- Предикат, описывающий разность множеств A и B…
- В грамматике G = (N, Σ, P, S) в нормальной форме Грейбаха e-правила…
- Заключительной конфигурацией конечного автомата M = (Q, Σ, δ, q0, F) является…
- Если передача параметра в процедуру или функцию заключается в текстуальной замене формального параметра в теле процедуры фактическим параметром перед выполнением тела процедуры, то это вызов…
- Избежать перехеширования при построении таблицы имен можно, используя…
- Разыменование при выполнении приведения типов – это, например, переход…
- Регулярное выражение α + β равно…
- Деревом T называется ориентированный граф G = (A, R) со специальной вершиной r∈A, называемой корнем, у которого…
- Полный просмотр таблицы имен при поиске идентификатора называется … поиском
- Описание for ch := 1 to 10 do … является … реализацией переменной ch.
- Для повышения эффективности выдаваемого кода при компиляции можно проделать дополнительную работу, которую называют…
- К внутренним ошибкам, связанным с ограничением компилятора, относят…
- Предупреждения при компиляции программы появляются…
- Символ – это элемент…
- Наиболее подходящим способом, на котором будет базироваться распределение памяти, является…
- Описание int i является … реализацией переменной i.
- Ситуация, когда при построении таблицы хеширования она заполняется неравномерно, называется…
- Какие утверждения являются верными? Здесь p – степень вершины по входу; q – по выходу…
- Пронумеровав от 1 до 6, расставьте по порядку этапы компиляции
- Сцепление элементов таблицы имен – это…
- Если передача параметра в процедуру или функцию заключается том, что при входе в процедуру выделяется память для значения формального параметра, а при выходе из процедуры значение, которое в этот момент имеет формальный параметр, присваивается фактическому параметру, то это вызов…
- Сколько адресов обрабатывает одна команда промежуточного кода, записанная в виде четверки?
- Векторизация при выполнении приведения типов – это, например, переход…
- Является ли грамматика, описанная данными правилами, LR(1)-грамматикой?
- Распроцедуривание при выполнении приведения типов – это, например, переход…
- Двухадресный промежуточный код называется …
- Распределение памяти заключается…
- Начальной конфигурацией конечного автомата M = (Q, Σ, δ, q0, F) является…
- Рефлексивное и транзитивное замыкание отношения R на множестве A подразумевают…
- Состояние q конечного автомата M называется недостижимым, если не существует такой входной цепочки x, что…
- При оптимизации кода последовательность команд «STORE α; LOAD α» можно…
- Регулярное выражение ∅α равно…
Нечеткое сравнение строк как метод обнаружения и исправления ошибок
Время прочтения: 4 мин.
Ошибки можно разделить на следующие виды (таблица).
| Вид ошибки | Пример |
| Ошибки слитно-раздельного написания | Идугулять → иду гулять, м олоко → молоко |
| Неверная раскладка клавиатуры | Dbjkjyxtkm → виолончель |
| Транслитерация | bukva → буква |
| Орфографические ошибки | Лопша → лапша |
| Опечатки | Докоть → локоть |
| Дубликаты символов | Марсиааааааане → марсиане |
| Ложные нажатия | Парсимнг → парсинг |
Существуют контекстно-независимые и контекстно-зависимые методы обнаружения и исправления ошибок. Мы рассмотрим контекстно-независимый способ обнаружения и исправления опечаток и орфографических ошибок. Для выполнения этой задачи нам понадобится алгоритм нечеткого сравнения строк. Существует множество реализаций данных алгоритмов, однако базовый принцип у них похож – данные алгоритмы выявляют разницу между входным словом и словом из словаря и выдают на выходе информацию о том, на сколько они похожи. Так, выполнив проход по словарю, можно получить список слов, наиболее похожих на слово с опечаткой. Далее, выбрать то слово, в котором разница будет минимальна и осуществить замену.
Итак, рассмотрим 4 популярных алгоритма нечеткого сравнения строк:
- алгоритм Хэмминга;
- редакционное расстояние Левенштейна;
- редакционное расстояние Дамерау-Левенштейна;
- расстояние Джаро-Винклера.
Алгоритм Хэмминга базируется на простом принципе – подсчет числа позиций, в которых соответствующие символы двух сравниваемых слов отличаются. Отсюда вытекают и минусы подобного решения – возможность сравнивать только слова одинаковой длины. Однако, реализовать его очень просто, можно обойтись без сторонних решений, но есть и библиотеки, упрощающие работу с данным алгоритмом. Устанавливаем библиотеку и используем нужный модуль. Алгоритм выводит значение, равное 1. Это значит, что строки отличаются друг от друга на 1 символ. При сравнении одинаковых строк вывод будет равен 0.
pip install levenshtein
import Levenshtein
Levenshtein.hamming('привот', 'привет') → 1
Алгоритм Левенштейна уже посложней, в его основе расчет количества операций, необходимых для преобразования одной строки в другую. Существует 3 таких операции:
- вставка символа (сыто → сытно);
- удаление символа (гидрант → гидрат);
- замена одного символа на другой (усвоить → освоить).
В алгоритме Дамерау-Левенштейна добавляется дополнительная операция транспозиции, позволяющая контролировать замену двух символов местами (прикрепить → рпикрепить). В данной реализации есть как и плюсы, так и минусы. Алгоритм позволяет сравнивать строки различной длины, его реализация все еще не является очень сложной, однако есть недостаток в виде долгого времени выполнения, которое при сравнении слова со словарем существенно усложняет анализ больших текстов. Для реализации в Python можно использовать ту же библиотеку.
from Levenshtein import distance
distance('привот', 'привет') → 1
Для использования алгоритма Дамерау-Левенштейна можно использовать библиотеку pyxDamerauLevenshtein.
pip install pyxDamerauLevenshtein
from pyxdameraulevenshtein import damerau_levenshtein_distance
damerau_levenshtein_distance('привот', 'привет') → 1
Расстояние Джаро-Винклера основывается на поиске точных и неточных совпадений в анализируемых строках. Под точным совпадением подразумевается совпадение значения и порядкового номера символа, под неточным — совпадение значения и порядкового номера символа ± длина совпадений L. Если обратиться к формулам, то расстояние Джаро-Винклера вычисляется достаточно просто:
Расстояние Джаро (Dj) вычисляется следующим образом:

, где me – точное совпадение символов в анализируемых строках, mf – неточное совпадение символов в анализируемых строках.
Зная расстояние Джаро, можно вычислить расстояние Джаро-Виклера (Djw):
![]()
, где n – длина совпадающего префикса (количество первых совпадающих символов), p – коэффициент масштабирования (по умолчанию равен 0,1).
Перейдем к преимуществам – это возможность сравнения строк разной длины, высокая скорость работы и выдача нормированного результата по умолчанию. Ниже представлен пример использования данного алгоритма в Python. Здесь результат выводится в другом формате: от 0 до 1, где 1 – это полное совпадение строк.
from jarowinkler import *
jarowinkler_similarity('привот', 'привет') → 0.9333333333333333
Расстояние Джаро-Винклера быстрее справляется с задачей, чем расстояние Левенштейна и Дамерау-Левенштейна и является более универсальным решением в сравнении с расстоянием Хэмминга. Это различие видно на приведенном графике, где в сравнении участвовали 3 алгоритма.

Очевидно, что использование алгоритма Джаро-Винклера является оптимальным с точки зрения скорости решением. Однако бывают ситуации, когда расстояние Левенштейна более предпочтительно из-за выдачи ненормированного результата по умолчанию. В случае с расстоянием Левенштейна мы также можем ввести дополнительные критерии оценивания, например как это сделано в алгоритме Дамерау-Левенштейна, где введен контроль дополнительной операции транспозиции. Можно также устанавливать свои веса для каждой операции, например присвоить коэффициент отличный от единицы операции замены символов. Тогда и результат, выдаваемый алгоритмом будет отличаться, что может быть полезным при адаптации к конкретной задаче распознавания.
Что дальше? А дальше сравнение строк. Алгоритм прост: берем словарь русского языка, выбираем из анализируемого текста слова с опечатками и/или ошибками и сравниваем со словарем. Обязательно нужно установить пороговое значение, ниже которого слова из словаря не будут включаться в результирующую выборку, я использую от 0.7-0.8 до 1 . Желательно предварительно выполнить предобработку и лемматизацию текста для улучшения качества распознавания.
Удачи при распознавании!


Синтаксическая ошибка в интернет-приложении (2021 г.)
Синтаксическая ошибка ( английская синтаксическая ошибка ) обычно является нарушением синтаксических правил естественного или искусственного языка. В грамматике термин относится к расположению частей предложения, в информатике обычно относится к так называемой контекстно-свободной части синтаксических правил языка программирования . Программы с синтаксическими ошибками отклоняются компилятором или интерпретатором . Синтаксически правильная программа может привести к ошибкам времени выполнения, если она содержит семантические ошибки.
определение
Синтаксические ошибки в грамматике естественных языков , например немецкого, являются нарушениями правил построения предложений, в соответствии с которыми слова объединяются в более крупные функциональные единицы ( предложения ), и между ними формулируются такие отношения, как часть-целое, зависимость и т. Д. части предложения .
Синтаксические ошибки в языках программирования распознаются парсером на этапе анализа при запуске компилятора, точнее, при синтаксическом анализе . Парсер должен не только распознавать, что анализируемый исходный код не соответствует формальной грамматике языка программирования, но и выдавать понятное сообщение об ошибке. Поскольку не все свойства языка программирования могут быть описаны контекстно-независимыми грамматиками, некоторые ошибки, например B. Нарушения правил типов языка программирования, также распознаваемые компилятором только при семантическом анализе . Другие ошибки мышления в программе вообще невозможно распознать во время компиляции; Однако компиляторы часто вставляют туда тестовый код, что приводит к ошибке времени выполнения только во время выполнения программы. В отличие от этого, семантические ошибки, то есть ошибки в предполагаемом значении текста программы, вообще не могут быть распознаны автоматически.
Примеры
Распространенным примером синтаксических ошибок в немецком языке являются такие формулировки, как
- сравнил сексуально задокументированную частоту появления Джека Лондона с частотой Эриха Мюсамса
В грамматических терминах наречное определение «сексуальный» относится к причастию «задокументировано», таким образом описывая обстоятельства документирования. Предполагаемое значение, однако, иное: сексуальным является не документирование, а частота. Так что это должно быть правильно: задокументированная частота половых контактов .
Синтаксические ошибки также могут возникать из-за неправильного сочетания уровней значений слов ( семантики ). Например:
- Время отклика провайдеров безопасности часто очень быстрое …
Времена бывают не быстрыми или медленными, а короткими или длинными. Это должно быть правильно, либо время отклика S. часто очень короткое, либо реакция S. часто очень быстрая …
Синтаксические ошибки в компьютерных программах часто вызваны неправильно размещенными или отсутствующими символами, такими как точки с запятой , запятые и квадратные скобки, или значимыми словами, такими как forили BEGIN. Интегрированные среды разработки обычно проектируются таким образом, что такие ошибки немедленно распознаются и сообщаются программисту.
Пример синтаксической ошибки в Java :
public class Beispiel { public static void main(String[] args) { System.out.println("Hallo Welt!") } }
В этом примере типичный компилятор Java критикует отсутствие точки с запятой после закрывающей скобки в строке 3, как того требует синтаксис Java . Вывод компилятора дает программисту информацию о типе и приблизительном местонахождении ошибки:
Syntax error, insert ";" to complete BlockStatements Beispiel.java line 3
Здесь обычно выводятся имя файла с исходным текстом , строка и фактическое сообщение об ошибке. Порядок и количество выходных данных варьируются от компилятора к компилятору.
Индивидуальные доказательства
- ^ Альфред В. Ахо, Рави Сети, Джеффри Д. Ульманн: Compilerbau . Лента 1 . Addison-Wesley, Bonn 1988, ISBN 3-89319-150-X , стр. 194 .
- ↑ Рюдигер Бернхардт в рецензии на Флориана Иллиеса: 1913 — То, что я действительно хотел сказать. Наше время 30.11.2018
- ↑ Кристиан Фенселау: Сканеры вирусов могут быть опасны. t-online.de 6.4.2016 ( онлайн )