Одна из ключевых особенностей Python, благодаря которой он является таким популярным – это простота. Особенно подкупает простота работы с различными структурами данных – списками, кортежами, словарями и множествами. Сегодня мы рассмотрим работу со списками.
Список (list) – это структура данных для хранения объектов различных типов. Если вы использовали другие языки программирования, то вам должно быть знакомо понятие массива. Так вот, список очень похож на массив, только, как было уже сказано выше, в нем можно хранить объекты различных типов. Размер списка не статичен, его можно изменять. Список по своей природе является изменяемым типом данных. Про типы данных можно подробно прочитать здесь. Переменная, определяемая как список, содержит ссылку на структуру в памяти, которая в свою очередь хранит ссылки на какие-либо другие объекты или структуры.
Как списки хранятся в памяти?
Как уже было сказано выше, список является изменяемым типом данных. При его создании в памяти резервируется область, которую можно условно назвать некоторым “контейнером”, в котором хранятся ссылки на другие элементы данных в памяти. В отличии от таких типов данных как число или строка, содержимое “контейнера” списка можно менять. Для того, чтобы лучше визуально представлять себе этот процесс взгляните на картинку ниже. Изначально был создан список содержащий ссылки на объекты 1 и 2, после операции a[1] = 3, вторая ссылка в списке стала указывать на объект 3.

Более подробно эти вопросы обсуждались в уроке 3 (Типы и модель данных).
Создание, изменение, удаление списков и работа с его элементами
Создать список можно одним из следующих способов.
>>> a = [] >>> type(a) <class 'list'> >>> b = list() >>> type(b) <class 'list'>
Также можно создать список с заранее заданным набором данных.
>>> a = [1, 2, 3] >>> type(a) <class 'list'>
Если у вас уже есть список и вы хотите создать его копию, то можно воспользоваться следующим способом:
>>> a = [1, 3, 5, 7] >>> b = a[:] >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7]
или сделать это так:
>>> a = [1, 3, 5, 7] >>> b = list(a) >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7]
В случае, если вы выполните простое присвоение списков друг другу, то переменной b будет присвоена ссылка на тот же элемент данных в памяти, на который ссылается a, а не копия списка а. Т.е. если вы будете изменять список a, то и b тоже будет меняться.
>>> a = [1, 3, 5, 7] >>> b = a >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7] >>> a[1] = 10 >>> print(a) [1, 10, 5, 7] >>> print(b) [1, 10, 5, 7]
Добавление элемента в список осуществляется с помощью метода append().
>>> a = []
>>> a.append(3)
>>> a.append("hello")
>>> print(a)
[3, 'hello']
Для удаления элемента из списка, в случае, если вы знаете его значение, используйте метод remove(x), при этом будет удалена первая ссылка на данный элемент.
>>> b = [2, 3, 5] >>> print(b) [2, 3, 5] >>> b.remove(3) >>> print(b) [2, 5]
Если необходимо удалить элемент по его индексу, воспользуйтесь командой del имя_списка[индекс].
>>> c = [3, 5, 1, 9, 6] >>> print(c) [3, 5, 1, 9, 6] >>> del c[2] >>> print(c) [3, 5, 9, 6]
Изменить значение элемента списка, зная его индекс, можно напрямую к нему обратившись.
>>> d = [2, 4, 9] >>> print(d) [2, 4, 9] >>> d[1] = 17 >>> print(d) [2, 17, 9]
Очистить список можно просто заново его проинициализировав, так как будто вы его вновь создаете. Для получения доступа к элементу списка укажите индекс этого элемента в квадратных скобках.
>>> a = [3, 5, 7, 10, 3, 2, 6, 0] >>> a[2] 7
Можно использовать отрицательные индексы, в таком случае счет будет идти с конца, например для доступа к последнему элементу списка можно использовать вот такую команду:
>>> a[-1] 0
Для получения из списка некоторого подсписка в определенном диапазоне индексов, укажите начальный и конечный индекс в квадратных скобках, разделив их двоеточием.
>>> a[1:4] [5, 7, 10]
Методы списков
list.append(x)
Добавляет элемент в конец списка. Ту же операцию можно сделать так a[len(a):] = [x].
>>> a = [1, 2] >>> a.append(3) >>> print(a) [1, 2, 3]
list.extend(L)
Расширяет существующий список за счет добавления всех элементов из списка L. Эквивалентно команде a[len(a):] = L.
>>> a = [1, 2] >>> b = [3, 4] >>> a.extend(b) >>> print(a) [1, 2, 3, 4]
list.insert(i, x)
Вставить элемент x в позицию i. Первый аргумент – индекс элемента после которого будет вставлен элемент x.
>>> a = [1, 2] >>> a.insert(0, 5) >>> print(a) [5, 1, 2] >>> a.insert(len(a), 9) >>> print(a) [5, 1, 2, 9]
list.remove(x)
Удаляет первое вхождение элемента x из списка.
>>> a = [1, 2, 3] >>> a.remove(1) >>> print(a) [2, 3]
list.pop([i])
Удаляет элемент из позиции i и возвращает его. Если использовать метод без аргумента, то будет удален последний элемент из списка.
>>> a = [1, 2, 3, 4, 5] >>> print(a.pop(2)) 3 >>> print(a.pop()) 5 >>> print(a) [1, 2, 4]
list.clear()
Удаляет все элементы из списка. Эквивалентно del a[:].
>>> a = [1, 2, 3, 4, 5] >>> print(a) [1, 2, 3, 4, 5] >>> a.clear() >>> print(a) []
list.index(x[, start[, end]])
Возвращает индекс элемента.
>>> a = [1, 2, 3, 4, 5] >>> a.index(4) 3
list.count(x)
Возвращает количество вхождений элемента x в список.
>>> a=[1, 2, 2, 3, 3] >>> print(a.count(2)) 2
list.sort(key=None, reverse=False)
Сортирует элементы в списке по возрастанию. Для сортировки в обратном порядке используйте флаг reverse=True. Дополнительные возможности открывает параметр key, за более подробной информацией обратитесь к документации.
>>> a = [1, 4, 2, 8, 1] >>> a.sort() >>> print(a) [1, 1, 2, 4, 8]
list.reverse()
Изменяет порядок расположения элементов в списке на обратный.
>>> a = [1, 3, 5, 7] >>> a.reverse() >>> print(a) [7, 5, 3, 1]
list.copy()
Возвращает копию списка. Эквивалентно a[:].
>>> a = [1, 7, 9] >>> b = a.copy() >>> print(a) [1, 7, 9] >>> print(b) [1, 7, 9] >>> b[0] = 8 >>> print(a) [1, 7, 9] >>> print(b) [8, 7, 9]
List Comprehensions
List Comprehensions чаще всего на русский язык переводят как абстракция списков или списковое включение, является частью синтаксиса языка, которая предоставляет простой способ построения списков. Проще всего работу list comprehensions показать на примере. Допустим вам необходимо создать список целых чисел от 0 до n, где n предварительно задается. Классический способ решения данной задачи выглядел бы так:
>>> n = int(input())
7
>>> a=[]
>>> for i in range(n):
a.append(i)
>>> print(a)
[0, 1, 2, 3, 4, 5, 6]
Использование list comprehensions позволяет сделать это значительно проще:
>>> n = int(input()) 7 >>> a = [i for i in range(n)] >>> print(a) [0, 1, 2, 3, 4, 5, 6]
или вообще вот так, в случае если вам не нужно больше использовать n:
>>> a = [i for i in range(int(input()))] 7 >>> print(a) [0, 1, 2, 3, 4, 5, 6]
List Comprehensions как обработчик списков
В языке Python есть две очень мощные функции для работы с коллекциями: map и filter. Они позволяют использовать функциональный стиль программирования, не прибегая к помощи циклов, для работы с такими типами как list, tuple, set, dict и т.п. Списковое включение позволяет обойтись без этих функций. Приведем несколько примеров для того, чтобы понять о чем идет речь.
Пример с заменой функции map.
Пусть у нас есть список и нужно получить на базе него новый, который содержит элементы первого, возведенные в квадрат. Решим эту задачу с использованием циклов:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = []
>>> for i in a:
b.append(i**2)
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [1, 4, 9, 16, 25, 36, 49]
Та же задача, решенная с использованием map, будет выглядеть так:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = list(map(lambda x: x**2, a))
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [1, 4, 9, 16, 25, 36, 49]
В данном случае применена lambda-функция, о том, что это такое и как ее использовать можете прочитать здесь.
Через списковое включение эта задача будет решена так:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = [i**2 for i in a]
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [1, 4, 9, 16, 25, 36, 49]
Пример с заменой функции filter.
Построим на базе существующего списка новый, состоящий только из четных чисел:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = []
>>> for i in a:
if i%2 == 0:
b.append(i)
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [2, 4, 6]
Решим эту задачу с использованием filter:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = list(filter(lambda x: x % 2 == 0, a))
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [2, 4, 6]
Решение через списковое включение:
>>> a = [1, 2, 3, 4, 5, 6, 7]
>>> b = [i for i in a if i % 2 == 0]
>>> print('a = {}nb = {}'.format(a, b))
a = [1, 2, 3, 4, 5, 6, 7]
b = [2, 4, 6]
Слайсы / Срезы
Слайсы (срезы) являются очень мощной составляющей Python, которая позволяет быстро и лаконично решать задачи выборки элементов из списка. Выше уже был пример использования слайсов, здесь разберем более подробно работу с ними. Создадим список для экспериментов:
>>> a = [i for i in range(10)]
Слайс задается тройкой чисел, разделенных запятой: start:stop:step. Start – позиция с которой нужно начать выборку, stop – конечная позиция, step – шаг. При этом необходимо помнить, что выборка не включает элемент определяемый stop.
Рассмотрим примеры:
>>> # Получить копию списка >>> a[:] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> # Получить первые пять элементов списка >>> a[0:5] [0, 1, 2, 3, 4] >>> # Получить элементы с 3-го по 7-ой >>> a[2:7] [2, 3, 4, 5, 6] >>> # Взять из списка элементы с шагом 2 >>> a[::2] [0, 2, 4, 6, 8] >>> # Взять из списка элементы со 2-го по 8-ой с шагом 2 >>> a[1:8:2] [1, 3, 5, 7]
Слайсы можно сконструировать заранее, а потом уже использовать по мере необходимости. Это возможно сделать, в виду того, что слайс – это объект класса slice. Ниже приведен пример, демонстрирующий эту функциональность:
>>> s = slice(0, 5, 1) >>> a[s] [0, 1, 2, 3, 4] >>> s = slice(1, 8, 2) >>> a[s] [1, 3, 5, 7]
Типо “List Comprehensions”… в генераторном режиме
Есть ещё одни способ создания списков, который похож на списковое включение, но результатом работы является не объект класса list, а генератор. Подробно про генераторы написано в “Уроке 15. Итераторы и генераторы“.
Предварительно импортируем модуль sys, он нам понадобится:
>>> import sys
Создадим список, используя списковое включение :
>>> a = [i for i in range(10)]
проверим тип переменной a:
>>> type(a) <class 'list'>
и посмотрим сколько она занимает памяти в байтах:
>>> sys.getsizeof(a) 192
Для создания объекта-генератора, используется синтаксис такой же как и для спискового включения, только вместо квадратных скобок используются круглые:
>>> b = (i for i in range(10)) >>> type(b) <class 'generator'> >>> sys.getsizeof(b) 120
Обратите внимание, что тип этого объекта ‘generator’, и в памяти он занимает места меньше, чем список, это объясняется тем, что в первом случае в памяти хранится весь набор чисел от 0 до 9, а во втором функция, которая будет нам генерировать числа от 0 до 9. Для наших примеров разница в размере не существенна, рассмотрим вариант с 10000 элементами:
>>> c = [i for i in range(10000)] >>> sys.getsizeof(c) 87624 >>> d = (i for i in range(10000)) >>> sys.getsizeof(d) 120
Сейчас уже разница существенна, как вы уже поняли, размер генератора в данном случае не будет зависеть от количества чисел, которые он должен создать.
Если вы решаете задачу обхода списка, то принципиальной разницы между списком и генератором не будет:
>>> for val in a:
print(val, end=' ')
0 1 2 3 4 5 6 7 8 9
>>> for val in b:
print(val, end=' ')
0 1 2 3 4 5 6 7 8 9
Но с генератором нельзя работать также как и со списком: нельзя обратиться к элементу по индексу и т.п.
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.

<<< Python. Урок 6. Работа с IPython и Jupyter Notebook Python. Урок 8. Кортежи (tuple) >>>
Обработка ошибок увеличивает отказоустойчивость кода, защищая его от потенциальных сбоев, которые могут привести к преждевременному завершению работы.

Прежде чем переходить к обсуждению того, почему обработка исключений так важна, и рассматривать встроенные в Python исключения, важно понять, что есть тонкая грань между понятиями ошибки и исключения.
Ошибку нельзя обработать, а исключения Python обрабатываются при выполнении программы. Ошибка может быть синтаксической, но существует и много видов исключений, которые возникают при выполнении и не останавливают программу сразу же. Ошибка может указывать на критические проблемы, которые приложение и не должно перехватывать, а исключения — состояния, которые стоит попробовать перехватить. Ошибки — вид непроверяемых и невозвратимых ошибок, таких как OutOfMemoryError, которые не стоит пытаться обработать.
Обработка исключений делает код более отказоустойчивым и помогает предотвращать потенциальные проблемы, которые могут привести к преждевременной остановке выполнения. Представьте код, который готов к развертыванию, но все равно прекращает работу из-за исключения. Клиент такой не примет, поэтому стоит заранее обработать конкретные исключения, чтобы избежать неразберихи.
Ошибки могут быть разных видов:
- Синтаксические
- Недостаточно памяти
- Ошибки рекурсии
- Исключения
Разберем их по очереди.
Синтаксические ошибки (SyntaxError)
Синтаксические ошибки часто называют ошибками разбора. Они возникают, когда интерпретатор обнаруживает синтаксическую проблему в коде.
Рассмотрим на примере.
a = 8
b = 10
c = a b
File "", line 3
c = a b
^
SyntaxError: invalid syntax
Стрелка вверху указывает на место, где интерпретатор получил ошибку при попытке исполнения. Знак перед стрелкой указывает на причину проблемы. Для устранения таких фундаментальных ошибок Python будет делать большую часть работы за программиста, выводя название файла и номер строки, где была обнаружена ошибка.
Недостаточно памяти (OutofMemoryError)
Ошибки памяти чаще всего связаны с оперативной памятью компьютера и относятся к структуре данных под названием “Куча” (heap). Если есть крупные объекты (или) ссылки на подобные, то с большой долей вероятности возникнет ошибка OutofMemory. Она может появиться по нескольким причинам:
- Использование 32-битной архитектуры Python (максимальный объем выделенной памяти невысокий, между 2 и 4 ГБ);
- Загрузка файла большого размера;
- Запуск модели машинного обучения/глубокого обучения и много другое;
Обработать ошибку памяти можно с помощью обработки исключений — резервного исключения. Оно используется, когда у интерпретатора заканчивается память и он должен немедленно остановить текущее исполнение. В редких случаях Python вызывает OutofMemoryError, позволяя скрипту каким-то образом перехватить самого себя, остановить ошибку памяти и восстановиться.
Но поскольку Python использует архитектуру управления памятью из языка C (функция malloc()), не факт, что все процессы восстановятся — в некоторых случаях MemoryError приведет к остановке. Следовательно, обрабатывать такие ошибки не рекомендуется, и это не считается хорошей практикой.
Ошибка рекурсии (RecursionError)
Эта ошибка связана со стеком и происходит при вызове функций. Как и предполагает название, ошибка рекурсии возникает, когда внутри друг друга исполняется много методов (один из которых — с бесконечной рекурсией), но это ограничено размером стека.
Все локальные переменные и методы размещаются в стеке. Для каждого вызова метода создается стековый кадр (фрейм), внутрь которого помещаются данные переменной или результат вызова метода. Когда исполнение метода завершается, его элемент удаляется.
Чтобы воспроизвести эту ошибку, определим функцию recursion, которая будет рекурсивной — вызывать сама себя в бесконечном цикле. В результате появится ошибка StackOverflow или ошибка рекурсии, потому что стековый кадр будет заполняться данными метода из каждого вызова, но они не будут освобождаться.
def recursion():
return recursion()
recursion()
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
in
----> 1 recursion()
in recursion()
1 def recursion():
----> 2 return recursion()
... last 1 frames repeated, from the frame below ...
in recursion()
1 def recursion():
----> 2 return recursion()
RecursionError: maximum recursion depth exceeded
Ошибка отступа (IndentationError)
Эта ошибка похожа по духу на синтаксическую и является ее подвидом. Тем не менее она возникает только в случае проблем с отступами.
Пример:
for i in range(10):
print('Привет Мир!')
File "", line 2
print('Привет Мир!')
^
IndentationError: expected an indented block
Исключения
Даже если синтаксис в инструкции или само выражение верны, они все равно могут вызывать ошибки при исполнении. Исключения Python — это ошибки, обнаруживаемые при исполнении, но не являющиеся критическими. Скоро вы узнаете, как справляться с ними в программах Python. Объект исключения создается при вызове исключения Python. Если скрипт не обрабатывает исключение явно, программа будет остановлена принудительно.
Программы обычно не обрабатывают исключения, что приводит к подобным сообщениям об ошибке:
Ошибка типа (TypeError)
a = 2
b = 'PythonRu'
a + b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 a = 2
2 b = 'PythonRu'
----> 3 a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Ошибка деления на ноль (ZeroDivisionError)
10 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
in
----> 1 10 / 0
ZeroDivisionError: division by zero
Есть разные типы исключений в Python и их тип выводится в сообщении: вверху примеры TypeError и ZeroDivisionError. Обе строки в сообщениях об ошибке представляют собой имена встроенных исключений Python.
Оставшаяся часть строки с ошибкой предлагает подробности о причине ошибки на основе ее типа.
Теперь рассмотрим встроенные исключения Python.
Встроенные исключения
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
Прежде чем переходить к разбору встроенных исключений быстро вспомним 4 основных компонента обработки исключения, как показано на этой схеме.
Try: он запускает блок кода, в котором ожидается ошибка.Except: здесь определяется тип исключения, который ожидается в блокеtry(встроенный или созданный).Else: если исключений нет, тогда исполняется этот блок (его можно воспринимать как средство для запуска кода в том случае, если ожидается, что часть кода приведет к исключению).Finally: вне зависимости от того, будет ли исключение или нет, этот блок кода исполняется всегда.
В следующем разделе руководства больше узнаете об общих типах исключений и научитесь обрабатывать их с помощью инструмента обработки исключения.
Ошибка прерывания с клавиатуры (KeyboardInterrupt)
Исключение KeyboardInterrupt вызывается при попытке остановить программу с помощью сочетания Ctrl + C или Ctrl + Z в командной строке или ядре в Jupyter Notebook. Иногда это происходит неумышленно и подобная обработка поможет избежать подобных ситуаций.
В примере ниже если запустить ячейку и прервать ядро, программа вызовет исключение KeyboardInterrupt. Теперь обработаем исключение KeyboardInterrupt.
try:
inp = input()
print('Нажмите Ctrl+C и прервите Kernel:')
except KeyboardInterrupt:
print('Исключение KeyboardInterrupt')
else:
print('Исключений не произошло')
Исключение KeyboardInterrupt
Стандартные ошибки (StandardError)
Рассмотрим некоторые базовые ошибки в программировании.
Арифметические ошибки (ArithmeticError)
- Ошибка деления на ноль (Zero Division);
- Ошибка переполнения (OverFlow);
- Ошибка плавающей точки (Floating Point);
Все перечисленные выше исключения относятся к классу Arithmetic и вызываются при ошибках в арифметических операциях.
Деление на ноль (ZeroDivisionError)
Когда делитель (второй аргумент операции деления) или знаменатель равны нулю, тогда результатом будет ошибка деления на ноль.
try:
a = 100 / 0
print(a)
except ZeroDivisionError:
print("Исключение ZeroDivisionError." )
else:
print("Успех, нет ошибок!")
Исключение ZeroDivisionError.
Переполнение (OverflowError)
Ошибка переполнение вызывается, когда результат операции выходил за пределы диапазона. Она характерна для целых чисел вне диапазона.
try:
import math
print(math.exp(1000))
except OverflowError:
print("Исключение OverFlow.")
else:
print("Успех, нет ошибок!")
Исключение OverFlow.
Ошибка утверждения (AssertionError)
Когда инструкция утверждения не верна, вызывается ошибка утверждения.
Рассмотрим пример. Предположим, есть две переменные: a и b. Их нужно сравнить. Чтобы проверить, равны ли они, необходимо использовать ключевое слово assert, что приведет к вызову исключения Assertion в том случае, если выражение будет ложным.
try:
a = 100
b = "PythonRu"
assert a == b
except AssertionError:
print("Исключение AssertionError.")
else:
print("Успех, нет ошибок!")
Исключение AssertionError.
Ошибка атрибута (AttributeError)
При попытке сослаться на несуществующий атрибут программа вернет ошибку атрибута. В следующем примере можно увидеть, что у объекта класса Attributes нет атрибута с именем attribute.
class Attributes(obj):
a = 2
print(a)
try:
obj = Attributes()
print(obj.attribute)
except AttributeError:
print("Исключение AttributeError.")
2
Исключение AttributeError.
Ошибка импорта (ModuleNotFoundError)
Ошибка импорта вызывается при попытке импортировать несуществующий (или неспособный загрузиться) модуль в стандартном пути или даже при допущенной ошибке в имени.
import nibabel
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 import nibabel
ModuleNotFoundError: No module named 'nibabel'
Ошибка поиска (LookupError)
LockupError выступает базовым классом для исключений, которые происходят, когда key или index используются для связывания или последовательность списка/словаря неверна или не существует.
Здесь есть два вида исключений:
- Ошибка индекса (
IndexError); - Ошибка ключа (
KeyError);
Ошибка ключа
Если ключа, к которому нужно получить доступ, не оказывается в словаре, вызывается исключение KeyError.
try:
a = {1:'a', 2:'b', 3:'c'}
print(a[4])
except LookupError:
print("Исключение KeyError.")
else:
print("Успех, нет ошибок!")
Исключение KeyError.
Ошибка индекса
Если пытаться получить доступ к индексу (последовательности) списка, которого не существует в этом списке или находится вне его диапазона, будет вызвана ошибка индекса (IndexError: list index out of range python).
try:
a = ['a', 'b', 'c']
print(a[4])
except LookupError:
print("Исключение IndexError, индекс списка вне диапазона.")
else:
print("Успех, нет ошибок!")
Исключение IndexError, индекс списка вне диапазона.
Ошибка памяти (MemoryError)
Как уже упоминалось, ошибка памяти вызывается, когда операции не хватает памяти для выполнения.
Ошибка имени (NameError)
Ошибка имени возникает, когда локальное или глобальное имя не находится.
В следующем примере переменная ans не определена. Результатом будет ошибка NameError.
try:
print(ans)
except NameError:
print("NameError: переменная 'ans' не определена")
else:
print("Успех, нет ошибок!")
NameError: переменная 'ans' не определена
Ошибка выполнения (Runtime Error)
Ошибка «NotImplementedError»
Ошибка выполнения служит базовым классом для ошибки NotImplemented. Абстрактные методы определенного пользователем класса вызывают это исключение, когда производные методы перезаписывают оригинальный.
class BaseClass(object):
"""Опередляем класс"""
def __init__(self):
super(BaseClass, self).__init__()
def do_something(self):
# функция ничего не делает
raise NotImplementedError(self.__class__.__name__ + '.do_something')
class SubClass(BaseClass):
"""Реализует функцию"""
def do_something(self):
# действительно что-то делает
print(self.__class__.__name__ + ' что-то делает!')
SubClass().do_something()
BaseClass().do_something()
SubClass что-то делает!
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in
14
15 SubClass().do_something()
---> 16 BaseClass().do_something()
in do_something(self)
5 def do_something(self):
6 # функция ничего не делает
----> 7 raise NotImplementedError(self.__class__.__name__ + '.do_something')
8
9 class SubClass(BaseClass):
NotImplementedError: BaseClass.do_something
Ошибка типа (TypeError)
Ошибка типа вызывается при попытке объединить два несовместимых операнда или объекта.
В примере ниже целое число пытаются добавить к строке, что приводит к ошибке типа.
try:
a = 5
b = "PythonRu"
c = a + b
except TypeError:
print('Исключение TypeError')
else:
print('Успех, нет ошибок!')
Исключение TypeError
Ошибка значения (ValueError)
Ошибка значения вызывается, когда встроенная операция или функция получают аргумент с корректным типом, но недопустимым значением.
В этом примере встроенная операция float получат аргумент, представляющий собой последовательность символов (значение), что является недопустимым значением для типа: число с плавающей точкой.
try:
print(float('PythonRu'))
except ValueError:
print('ValueError: не удалось преобразовать строку в float: 'PythonRu'')
else:
print('Успех, нет ошибок!')
ValueError: не удалось преобразовать строку в float: 'PythonRu'
Пользовательские исключения в Python
В Python есть много встроенных исключений для использования в программе. Но иногда нужно создавать собственные со своими сообщениями для конкретных целей.
Это можно сделать, создав новый класс, который будет наследовать из класса Exception в Python.
class UnAcceptedValueError(Exception):
def __init__(self, data):
self.data = data
def __str__(self):
return repr(self.data)
Total_Marks = int(input("Введите общее количество баллов: "))
try:
Num_of_Sections = int(input("Введите количество разделов: "))
if(Num_of_Sections < 1):
raise UnAcceptedValueError("Количество секций не может быть меньше 1")
except UnAcceptedValueError as e:
print("Полученная ошибка:", e.data)
Введите общее количество баллов: 10
Введите количество разделов: 0
Полученная ошибка: Количество секций не может быть меньше 1
В предыдущем примере если ввести что-либо меньше 1, будет вызвано исключение. Многие стандартные исключения имеют собственные исключения, которые вызываются при возникновении проблем в работе их функций.
Недостатки обработки исключений в Python
У использования исключений есть свои побочные эффекты, как, например, то, что программы с блоками try-except работают медленнее, а количество кода возрастает.
Дальше пример, где модуль Python timeit используется для проверки времени исполнения 2 разных инструкций. В stmt1 для обработки ZeroDivisionError используется try-except, а в stmt2 — if. Затем они выполняются 10000 раз с переменной a=0. Суть в том, чтобы показать разницу во времени исполнения инструкций. Так, stmt1 с обработкой исключений занимает больше времени чем stmt2, который просто проверяет значение и не делает ничего, если условие не выполнено.
Поэтому стоит ограничить использование обработки исключений в Python и применять его в редких случаях. Например, когда вы не уверены, что будет вводом: целое или число с плавающей точкой, или не уверены, существует ли файл, который нужно открыть.
import timeit
setup="a=0"
stmt1 = '''
try:
b=10/a
except ZeroDivisionError:
pass'''
stmt2 = '''
if a!=0:
b=10/a'''
print("time=",timeit.timeit(stmt1,setup,number=10000))
print("time=",timeit.timeit(stmt2,setup,number=10000))
time= 0.003897680000136461
time= 0.0002797570000439009
Выводы!
Как вы могли увидеть, обработка исключений помогает прервать типичный поток программы с помощью специального механизма, который делает код более отказоустойчивым.
Обработка исключений — один из основных факторов, который делает код готовым к развертыванию. Это простая концепция, построенная всего на 4 блоках: try выискивает исключения, а except их обрабатывает.
Очень важно поупражняться в их использовании, чтобы сделать свой код более отказоустойчивым.
Содержание:
1. Обработка исключительной ситуации
2. Совершаем ошибку в 1С 8.3
3. А что еще можно делать с результатом попытки?
4. А ваши транзакции то здесь при чём?
1. Обработка исключительной ситуации
— Приветствую, Амиго! Ты, как я понял, пришёл на мою лекцию по физическим основам изготовления термитных пирамидок для заряда аппаратов гиперболоидной конструкции? Нет? А зачем тогда?

— Здравствуйте, профессор. Сегодня мы собирались разобрать конструкцию «Попытка-Исключение».
— А… Это… Ну, тогда вот:

— Кажется, понятно. А можно примеров добавить?
— Ох уж эти юные роботы, всегда хотят практики. С примерами это будет выглядеть вот так:

Ох, извини, это для старых баз. На новых космолётах с прошивкой выше 8.1 есть более удобный способ узнать код ошибки.
2. Совершаем ошибку в 1С 8.3
Ты и сам можешь попробовать. Главное – придумать ошибку в 1С 8.3. Самая простая ошибка – это разделить что-нибудь на нуль или на, как это говорят на современном сленге, ноль.

В ответ получим:

Нажимаем на кнопку «Подробно…» и видим: Деление на 0 {NudlsProff_Расширение.NudlsProff_ФормаОшибок.Форма(96)}: Результат = 1/0
Добавляем нашей красоты:

Теперь пользователю ВИДНО, что случилось. И ПОНЯТНО, что с этим делать.
Описание=’Деление на 0′
ИмяМодуля=’NudlsProff_Расширение.NudlsProff_ФормаОшибок.Форма’
НомерСтроки=99
ИсходнаяСтрока=’ Результат = 1 / 0;’
Позвоните Профессору Нудлсупо тел+7 (495) 125-23-77
и ознакомьтесь с теорией деления на ноль
https://elementy.ru/email/1530320/Pochemu_nelzya_delit_na_nol
3. А что еще можно делать с результатом попытки?
— А что ещё мы можем делать в результате с попыткой?
— Мы можем обработать попытку в попытке.

По своей сути Попытка-Исключение – это отлов исключительной ситуации. Ситуации, которая может произойти. Возможно, даже и не по вине юного робота. Робот же должен учесть все возможные ситуации при написании кода и обработать их. Но наш мир не идеален и даже программы не всегда работают идеально. Именно тогда мы и должны проанализировать возможные последствия и понять, что для нас важнее: чтобы код выполнился до конца или вызвать прерывание работы ошибочного кусочка кода, но дать пользователю исправить ситуацию и продолжить работу.

— Профессор, Вы опять забыли про примеры.
— Ах, да, конечно. Например, мы записывали файл на диск. Пользователь, конечно, выбрал папку для записи файла, но случайно удалил её во время работы программы. Вся наша программа рухнет из-за невнимательности.

Нельзя просто обернуть код в попытку и обезопасить себя от последствий. Также неправильно и маскировать ошибку общими фразами – дальнейший поиск и исправление этого бага вызовет уйму вопросов. Нужно показать максимально информативное сообщение пользователю, чтобы он передал его в службу поддержки. Всё-же, исключительная ситуация – это баг, который нужно исправлять.

4. А ваши транзакции то здесь при чем?
— То есть если в программе что-то может пойти не так, например, при записи файла на диск, обработке web-hook, работе с API, синхронизации с другими базами, записи изменений в справочник или документ, для безопасности я должен обернуть потенциально опасный кусочек кода в Попытку-Исключение, и тем самым пользователь сможет продолжить работу, а мы всегда будем знать, где именно и почему возникает ошибка?
— Да, Амиго, все верно! Кстати, поскольку уж речь зашла о записи объектов баз данных, очень важно не забывать правильно закрывать ваши транзакции:

Специалист компании «Кодерлайн»
Алексей Зятнин
В этом руководстве мы расскажем, как обрабатывать исключения в Python с помощью try и except. Рассмотрим общий синтаксис и простые примеры, обсудим, что может пойти не так, и предложим меры по исправлению положения.
Зачастую разработчик может предугадать возникновение ошибок при работе даже синтаксически и логически правильной программы. Эти ошибки могут быть вызваны неверными входными данными или некоторыми предсказуемыми несоответствиями.
Для обработки большей части этих ошибок как исключений в Python есть блоки try и except.
Для начала разберем синтаксис операторов try и except в Python. Общий шаблон представлен ниже:
try:
# В этом блоке могут быть ошибки
except <error type>:
# Сделай это для обработки исключения;
# выполняется, если блок try выбрасывает ошибку
else:
# Сделай это, если блок try выполняется успешно, без ошибок
finally:
# Этот блок выполняется всегда
Давайте посмотрим, для чего используются разные блоки.
Блок try
Блок try — это блок кода, который вы хотите попробовать выполнить. Однако во время выполнения из-за какого-нибудь исключения могут возникнуть ошибки. Поэтому этот блок может не работать должным образом.
Блок except
Блок except запускается, когда блок try не срабатывает из-за исключения. Инструкции в этом блоке часто дают некоторый контекст того, что пошло не так внутри блока try.
Если собираетесь перехватить ошибку как исключение, в блоке except нужно обязательно указать тип этой ошибки. В приведенном выше сниппете место для указания типа ошибки обозначено плейсхолдером <error type> .
except можно использовать и без указания типа ошибки. Но лучше так не делать. При таком подходе не учитывается, что возникающие ошибки могут быть разных типов. То есть вы будете знать, что что-то пошло не так, но что именно произошло, какая была ошибка — вам будет не известно.
При попытке выполнить код внутри блока try также существует вероятность возникновения нескольких ошибок.
Например, вы можете попытаться обратиться к элементу списка по индексу, выходящему за пределы допустимого диапазона, использовать неправильный ключ словаря и попробовать открыть несуществующий файл – и все это внутри одного блока try.
В результате вы можете столкнуться с IndexError, KeyError и FileNotFoundError. В таком случае нужно добавить столько блоков except, сколько ошибок ожидается – по одному для каждого типа ошибки.
Блок else
Блок else запускается только в том случае, если блок try выполняется без ошибок. Это может быть полезно, когда нужно выполнить ещё какие-то действия после успешного выполнения блока try. Например, после успешного открытия файла вы можете прочитать его содержимое.
Блок finally
Блок finally выполняется всегда, независимо от того, что происходит в других блоках. Это полезно, когда вы хотите освободить ресурсы после выполнения определенного блока кода.
Примечание: блоки else и finally не являются обязательными. В большинстве случаев вы можете использовать только блок try, чтобы что-то сделать, и перехватывать ошибки как исключения внутри блока except.
[python_ad_block]
Итак, теперь давайте используем полученные знания для обработки исключений в Python. Приступим!
Обработка ZeroDivisionError
Рассмотрим функцию divide(), показанную ниже. Она принимает два аргумента – num и div – и возвращает частное от операции деления num/div.
def divide(num,div):
return num/div
Вызов функции с разными аргументами возвращает ожидаемый результат:
res = divide(100,8) print(res) # Output # 12.5 res = divide(568,64) print(res) # Output # 8.875
Этот код работает нормально, пока вы не попробуете разделить число на ноль:
divide(27,0)
Вы видите, что программа выдает ошибку ZeroDivisionError:
# Output
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-19-932ea024ce43> in <module>()
----> 1 divide(27,0)
<ipython-input-1-c98670fd7a12> in divide(num, div)
1 def divide(num,div):
----> 2 return num/div
ZeroDivisionError: division by zero
Можно обработать деление на ноль как исключение, выполнив следующие действия:
- В блоке
tryпоместите вызов функцииdivide(). По сути, вы пытаетесь разделитьnumнаdiv(try в переводе с английского — «пытаться», — прим. перев.). - В блоке
exceptобработайте случай, когдаdivравен 0, как исключение. - В результате этих действий при делении на ноль больше не будет выбрасываться ZeroDivisionError. Вместо этого будет выводиться сообщение, информирующее пользователя, что он попытался делить на ноль.
Вот как все это выглядит в коде:
try:
res = divide(num,div)
print(res)
except ZeroDivisionError:
print("You tried to divide by zero :( ")
При корректных входных данных наш код по-прежнему работает великолепно:
divide(10,2) # Output # 5.0
Когда же пользователь попытается разделить на ноль, он получит уведомление о возникшем исключении. Таким образом, программа завершается корректно и без ошибок.
divide(10,0) # Output # You tried to divide by zero :(
Обработка TypeError
В этом разделе мы разберем, как использовать try и except для обработки TypeError в Python.
Рассмотрим функцию add_10(). Она принимает число в качестве аргумента, прибавляет к нему 10 и возвращает результат этого сложения.
def add_10(num):
return num + 10
Вы можете вызвать функцию add_10() с любым числом, и она будет работать нормально, как показано ниже:
result = add_10(89) print(result) # Output # 99
Теперь попробуйте вызвать функцию add_10(), передав ей в качестве аргумента не число, а строку.
add_10 ("five")
Ваша программа вылетит со следующим сообщением об ошибке:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-9844e949c84e> in <module>()
----> 1 add_10("five")
<ipython-input-13-2e506d74d919> in add_10(num)
1 def add_10(num):
----> 2 return num + 10
TypeError: can only concatenate str (not "int") to str
Сообщение об ошибке TypeError: can only concatenate str (not "int") to str говорит о том, что можно сложить только две строки, а не добавить целое число к строке.
Обработаем TypeError:
- В блок try мы помещаем вызов функции
add_10()с my_num в качестве аргумента. Если аргумент допустимого типа, исключений не возникнет. - В противном случае срабатывает блок
except, в который мы помещаем вывод уведомления для пользователя о том, что аргумент имеет недопустимый тип.
Это показано ниже:
my_num = "five"
try:
result = add_10(my_num)
print(result)
except TypeError:
print("The argument `num` should be a number")
Поскольку теперь вы обработали TypeError как исключение, при передаче невалидного аргумента ошибка не возникает. Вместо нее выводится сообщение, что аргумент имеет недопустимый тип.
The argument `num` should be a number
Обработка IndexError
Если вам приходилось работать со списками или любыми другими итерируемыми объектами, вы, вероятно, сталкивались с IndexError.
Это связано с тем, что часто бывает сложно отслеживать все изменения в итерациях. И вы можете попытаться получить доступ к элементу по невалидному индексу.
В этом примере список my_list состоит из 4 элементов. Допустимые индексы — 0, 1, 2 и 3 и -1, -2, -3, -4, если вы используете отрицательную индексацию.
Поскольку 2 является допустимым индексом, вы видите, что элемент с этим индексом (C++) распечатывается:
my_list = ["Python","C","C++","JavaScript"] print(my_list[2]) # Output # C++
Но если вы попытаетесь получить доступ к элементу по индексу, выходящему за пределы допустимого диапазона, вы столкнетесь с IndexError:
print(my_list[4])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-437bc6501dea> in <module>()
1 my_list = ["Python","C","C++","JavaScript"]
----> 2 print(my_list[4])
IndexError: list index out of range
Теперь вы уже знакомы с шаблоном, и вам не составит труда использовать try и except для обработки данной ошибки.
В приведенном ниже фрагменте кода мы пытаемся получить доступ к элементу по индексу search_idx.
search_idx = 3
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Здесь search_idx = 3 является допустимым индексом, поэтому в результате выводится соответствующий элемент — JavaScript.
Если search_idx находится за пределами допустимого диапазона индексов, блок except перехватывает IndexError как исключение, и больше нет длинных сообщений об ошибках.
search_idx = 4
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Вместо этого отображается сообщение о том, что search_idx находится вне допустимого диапазона индексов:
Sorry, the list index is out of range
Обработка KeyError
Вероятно, вы уже сталкивались с KeyError при работе со словарями в Python.
Рассмотрим следующий пример, где у нас есть словарь my_dict.
my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
search_key = "non-existent key"
print(my_dict[search_key])
В словаре my_dict есть 3 пары «ключ-значение»: key1:value1, key2:value2 и key3:value3.
Теперь попытаемся получить доступ к значению, соответствующему несуществующему ключу non-existent key.
Как и ожидалось, мы получим KeyError:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-2a61d404be04> in <module>()
1 my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
2 search_key = "non-existent key"
----> 3 my_dict[search_key]
KeyError: 'non-existent key'
Вы можете обработать KeyError почти так же, как и IndexError.
- Пробуем получить доступ к значению, которое соответствует ключу, определенному
search_key. - Если
search_key— валидный ключ, мы распечатываем соответствующее значение. - Если ключ невалиден и возникает исключение — задействуется блок except, чтобы сообщить об этом пользователю.
Все это можно видеть в следующем коде:
try:
print(my_dict[search_key])
except KeyError:
print("Sorry, that's not a valid key!")
# Output:
# Sorry, that's not a valid key!
Если вы хотите предоставить дополнительный контекст, например имя невалидного ключа, это тоже можно сделать. Возможно, ключ оказался невалидным из-за ошибки в написании. Если вы укажете этот ключ в сообщении, это поможет пользователю исправить опечатку.
Вы можете сделать это, перехватив невалидный ключ как <error_msg> и используя его в сообщении, которое печатается при возникновении исключения:
try:
print(my_dict[search_key])
except KeyError as error_msg:
print(f"Sorry,{error_msg} is not a valid key!")
Обратите внимание, что теперь в сообщении об ошибки указано также и имя несуществующего ключа:
Sorry, 'non-existent key' is not a valid key!
Обработка FileNotFoundError
При работе с файлами в Python часто возникает ошибка FileNotFoundError.
В следующем примере мы попытаемся открыть файл my_file.txt, указав его путь в функции open(). Мы хотим прочитать файл и вывести его содержимое.
Однако мы еще не создали этот файл в указанном месте.
my_file = open("/content/sample_data/my_file.txt")
contents = my_file.read()
print(contents)
Поэтому, попытавшись запустить приведенный выше фрагмент кода, мы получим FileNotFoundError:
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-4873cac1b11a> in <module>()
----> 1 my_file = open("my_file.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.txt'
А с помощью try и except мы можем сделать следующее:
- Попробуем открыть файл в блоке
try. - Обработаем
FileNotFoundErrorв блокеexcept, сообщив пользователю, что он попытался открыть несуществующий файл. - Если блок
tryзавершается успешно и файл действительно существует, прочтем и распечатаем содержимое. - В блоке
finallyзакроем файл, чтобы не терять ресурсы. Файл будет закрыт независимо от того, что происходило на этапах открытия и чтения.
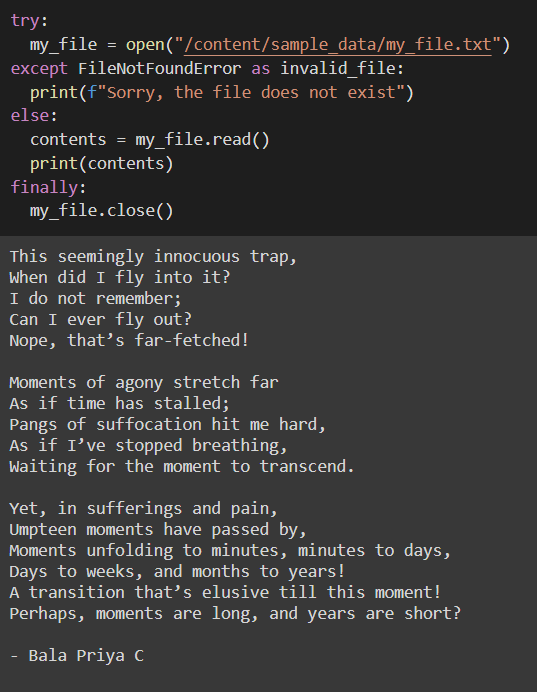
try:
my_file = open("/content/sample_data/my_file.txt")
except FileNotFoundError:
print(f"Sorry, the file does not exist")
else:
contents = my_file.read()
print(contents)
finally:
my_file.close()
Обратите внимание: мы обработали ошибку как исключение, и программа завершает работу, отображая следующее сообщение:
Sorry, the file does not exist
Теперь рассмотрим случай, когда срабатывает блок else. Файл my_file.txt теперь присутствует по указанному ранее пути.
Вот содержимое этого файла:
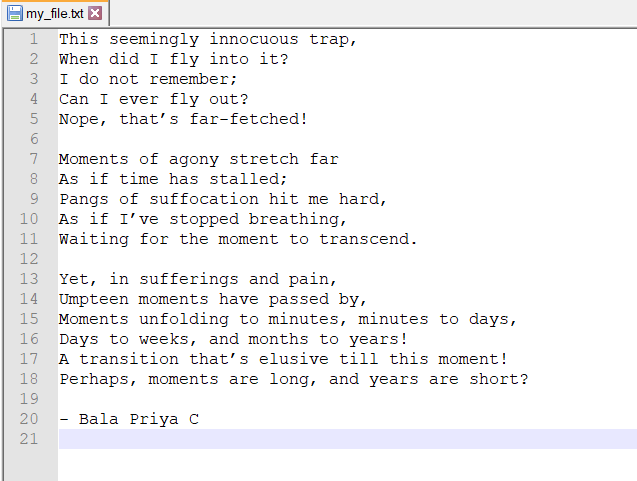
Теперь повторный запуск нашего кода работает должным образом.
На этот раз файл my_file.txt присутствует, поэтому запускается блок else и содержимое распечатывается, как показано ниже:
Надеемся, теперь вы поняли, как обрабатывать исключения при работе с файлами.
Заключение
В этом руководстве мы рассмотрели, как обрабатывать исключения в Python с помощью try и except.
Также мы разобрали на примерах, какие типы исключений могут возникать и как при помощи except ловить наиболее распространенные ошибки.
Надеемся, вам понравился этот урок. Успехов в написании кода!
Перевод статьи «Python Try and Except Statements – How to Handle Exceptions in Python».
This topic has been deleted. Only users with topic management privileges can see it.
-
Добрый день, прошу совета опытных ребят, поделитесь самым рабочим паттерном по работе с ошибками и исключениями.
Имеем — проект на 20 функций, в каждой 10-20 действий.
Вопрос — как можно, красиво и универсально обрабатывать ошибки?
Это мой первый проект, потому на данный момент, исходя из примеров и документации, для себя вижу пока что одно решение «в лоб»:
- каждое действие оборачивать в блок «Игнор ошибок» где при ошибке делаем «Скриншот» + отправка мне в телеграмм извещения ( или сервер, не суть ), с указанием места где произошла ошибка в коде, или простое игнорирование.
Получается нужно два типа реагирования на ошибки:
-
когда точно знаю что элемент на странице обязан быть, а его нет, таким образом можно предположить что веб-ресурс поменял вёрстку, мы пропускаем функцию или совсем стопаем проект, зависит от условий в разных местах.
-
когда элемент не обязательно должен существовать, и нам нужно просто тихо проигнорировать и идти дальше
Проблема — если оборачивать каждое действие в игнор, это очень сильно увеличит общее количество кода ( блоков ), ухудшит общую читаемость, восприятие и тд.
Чего хотелось бы — не изобретать велосипед, а сразу сделать правильно. Поделитесь опытом друзья)
-
@centerdevs выполнить код практически любой экшен можно выполнить в нем, и там конструируйте чсто вам хочется и как хочется. Читаемость не сильно повысится, но вам будет понятнее. Игнорировать ошибки это и есть универсальный обработчик вы замечали что он в консоль выводит какая последняя ошибка?, никто не мешает вам дополнить например номером кубика если вы кодите на них или еще что либо. Но читаемость на кубиках это довольно необычно) когда у вас 1000+ действий вы все равно запутаетесь.
upd Самый простой способ на кубиках это выносить из main все второстепенное в отдельные функции. тогда будет хоть как то понятнее типа такого -
@f0cus
воу! то есть можно из «выполнить код» вызывать весь функционал БАС? я даже не знал об этом, я так и делал как у Вас на скрине, это все ровно достаточно не удобно, действительно.
Как я понимаю, https://raw.githubusercontent.com/bablosoft/BAS/master/Engine/text/apilist.txt это список всего функционала который нам доступен для работы из кода? Вы не могли бы показать пример кусочка кода своего, как это +- организовано? Или возможно где-то есть видео-текст мануал который я пропустил, где приводится пример такой работы.
-
@centerdevs https://community.bablosoft.com/topic/6815/aurora-v1-1-0-новая-версия-библиотеки
Там есть api баса. Но учтите вам нужно сразу внимательно почитать по форуму все темы с запросом асинхронные функции иначе будет много непоняток.
Такого примера нет, потому что это как бэ не заявляется. Но работает. Кубики это для тех кто не имеет навыков программирования. Есть еще создать в конструкторе, почему то не очень популярно а экшен вполне себе рабочий.
upd Да учтите главное бас понимает ecmascript 262 никаких ecmdscript 8 -7 10 только ecmascript 262. -
@f0cus said in Универсальное решение по обработке ошибок BAS?:
ecmdscript 8
Вот это я очень важный этап пропустил когда приступил к созданию проекта)) Походу сейчас буду переписывать все свои кубики в код)
Поискал по форуму, не нашел живых примеров организации такой работы, понимаю что каждому удобно по своему.
Но, как в идеале опытным путём организовывать работу через код, как делать отладку?
Какие варианты вижу:
-
Весь проект находится в одном блоке «Выполнить код», в него добавляются вызовы по мере создания проекта. То есть, сначала действие тестируется в отдельном кубике «Выполнить код», а потом уже переносится в общий файл с кодом. Таким образом получим один раздутый «Выполнить код» который будет оперировать всем на свете.
-
Разделить код на некоторые функциональные части, ака Функции на кубиках. То есть мы получим вместо одного файла, допустим 5 файлов «Выполнить код», например Регистрация, Подтверждение, Логин, Парсинг, Постинг. И там уже будет код отвечающий за эти действия.
Каким образом делаете Вы и почему?)
Тут вижу проблему с отладкой, то есть когда я в отдельном кубике отладил действие, и хочу перекинуть его в общий код, то мне в какой-то момент надо отладить общий код)) вдруг там что-то начало мешать друг другу, ну или просто ошибка где-то. Нужно будет как-то отлавливать уже ошибки в общем коде, который большой и который не так удобно контроллировать.
-
-
@centerdevs Сначала? да со временем вы набьете руку и будете вызывать их напрямую без тестирования обращаясь через api. Начните с простого. Перенесите одно действие в выполнить код, посмотрите как работает, второе, и так далее. Вам просто нужно будет поиграть с басом. Понять как он работает. все section_ что то вас не интересуют. только сами действия. Не надо сразу запрашивать из кода через клиента=) или открывать страницу это асинхрон. С ними у вас еще будет возможность ‘пообщатся’).
Через кубик логирование тоже возможно. log() никаких console.log(). Ну если вы не во встроенном языке в ноде все как в ноде 8.6.0 и она отдельная тема.
upd маленькие var что_то в записи пойдут дальше, в запуске нет. При выполнении всех асинхронов маленькие var обнуляются. Т.е если у вас в коде что то асинхронное и потом будут действия то переносите через [[]] Можете массивы можете объекты можете JSON бас со всем эти прекрасно работает. -
@centerdevs, не стоит писать весь скрипт в «Выполнить код», могут возникнуть проблемы куда серьезней чем «Как обработать ошибки»
-
@f0cus, ну например утечка памяти забивающая 32гб озу за 5 мин
-
@GhostZ Бывает. я что бы такого не было response и request все равно разношу по разным выполнить код. и да по моему сборщик мусора у баса включается только после кубика. но это не точно.
-
Большое спасибо за советы друзья)
+- всё понял, но пока что полная картинка не вырисовалась как сделать по людски, возможно кто-то может поделиться неактуальным проектом у которого достаточно большой код и который организован именно на Выполнить код а не на кубиках, это было бы лучшим примером ) Рыскаю по всему форуму, те проекты что выкладывают участники, все на кубиках.
Я так понимаю текущий проект переделывать ради кода нет смысла всё таки. Есть смысл дальше по мере увеличения проекта внедрять именно код а не кубики.
Тогда вопрос по работе с ошибками остается открытым)
Как можно игнорировать все ошибки?) не пропуская при этом следующие действия, чтобы я хотя бы в нужных местах мог поставить исключения, а там где это неважно мог бы просто игнорировать?)
В текущем примере при любой ошибке в Register, дальше дело не пойдет, повторюсь у меня в реальном проекте много действий, если каждое оборачивать в Игнор ошибок, это будет немного неудобно, разве нет простого решения этому?)
-
@centerdevs Лучше игнорировать ошибки устанавливайте не на функции, вы просто не поймете что там было, а на действия. в самих функциях. Т.е найти какой то элемент например или загрузка url и вот его оборачивайте. Что бы это не выглядело в кубиках очень уж страшно у баса есть вот это

Вы же пишете код с нуля и шаблона нет потому каждое можете конечно заморочится и написать модуль с обработкой ошибок установить его и пусть обрабатывает. Но штатно только так. Это не сильно заморочит кубики можно комментировать и можно сворачивать. Как на скрине выше.
-
@f0cus Да, получается придется каждое действие оборачивать в игнор) в котором в случае ошибки можно вызывать функцию которая отправляет мне скриншот и информирует. Пока начну так «в лоб» делать, если приду к какому-нибудь адекватному комплексному решению — поделюсь с сообществом. Большое спасибо Вам за разъяснения и все наводки !)
-
Нашёл интересную штуку, при открытом проекте, можно нажать Менеджер модулей, и создать модуль из текущего проекта, таким образом мы получаем все свои кубики, в виде кода, где каждая функция интерфейсная, становится реальной) и с кодом внутри.
Вот пример тестовый
function Login() { _call(function() { _on_fail(function(){ VAR_LAST_ERROR = _result() VAR_ERROR_ID = ScriptWorker.GetCurrentAction() VAR_WAS_ERROR = false _break(1,true) }) CYCLES.Current().RemoveLabel("function") load("googlecom")! log("Неудачно"); load("http://google.com/")! log("Удачно"); },null)! _if(VAR_WAS_ERROR,function(){ log("Произошла ошибка : " + VAR_LAST_ERROR) })! }Сделал пару тестов методом тыка, при ошибке все ровно обработка дальнейшая прекращается, тут разве что делать какую-то функцию/класс обёртку.
А еще нашел кнопку скрипт, которая показывает код всех кубиков в более реальном как оно показывается в кубиках, с ид-шками итд. По сути тот же код что и выше + указание начала конца кубиков и инфо.
-
@centerdevs Оборачивайте не каждое действие, а зависимые блоки действий, то есть если в одном из них произойдет ошибка, то остальные не будут выполняться. Для более детальной обработки ошибок вы можете создать отдельную функцию, которую будите вызывать после каждого блока игнорирования ошибок.
-
@centerdevs said in Универсальное решение по обработке ошибок BAS?:
Вот так получилось игнорировать ошибку и продолжать выполнение кода, но блок catch не срабатывает при этом.
Этот код неверный, у БАС не все так просто, действия с ! в конце являются асинхронными. Я не буду объяснять как все это работает потому что это плохой путь и не рекомендуется разработчиком БАС.
-
@UserTrue странно, но эту асинхронность сгенерил сам BAS, на скриншоте выше там оригинал того что я экспортировал в модуль.
Так и планирую оборачивать группами которые взаимосвязаны, просто я уже +- нашел все методы для работы через Код, и для организации такой работы мне ведь и в коде нужно как-то игнорировать ошибки и их обрабатывать ) потому стало интересно как это делают собраться, кто работает с БАС через код )
-
@centerdevs said in Универсальное решение по обработке ошибок BAS?:
странно, но эту асинхронность сгенерил сам BAS, на скриншоте выше там оригинал того что я экспортировал в модуль.
Посмотрите внимательный, там где сгенерировал сам БАС нет try/catch у БАС свое api для работы с асинхронностью
-
@UserTrue да, это моя неудачная попытка словить ошибку )
_call(function(){ _on_fail(function(){ VAR_LAST_ERROR = _result() VAR_ERROR_ID = ScriptWorker.GetCurrentAction() log(VAR_ERROR_ID+' '+VAR_LAST_ERROR); }) load("googlecom")! log("1 Удачно"); }, null)! _call(function(){ _on_fail(function(){ VAR_LAST_ERROR = _result() VAR_ERROR_ID = ScriptWorker.GetCurrentAction() log(VAR_ERROR_ID+' '+VAR_LAST_ERROR) }) load("http://google.com/")! log("2 Удачно"); }, null)!Вот таким образом получилось на данный момент ловить ошибку и продолжать работу дальше. Интересно можно ли будет как-то использовать этот _on_fail глобально.
Содержание
Составили подробный классификатор кодов состояния HTTP. Добавляйте в закладки, чтобы был под рукой, когда понадобится.
Что такое код ответа HTTP
Когда посетитель переходит по ссылке на сайт или вбивает её в поисковую строку вручную, отправляется запрос на сервер. Сервер обрабатывает этот запрос и выдаёт ответ — трехзначный цифровой код HTTP от 100 до 510. По коду ответа можно понять реакцию сервера на запрос.
Первая цифра в ответе обозначает класс состояния, другие две — причину, по которой мог появиться такой ответ.
Как проверить код состояния страницы
Проверить коды ответа сервера можно вручную с помощью браузера и в панелях веб‑мастеров: Яндекс.Вебмастер и Google Search Console.
В браузере
Для примера возьмём Google Chrome.
-
Откройте панель разработчика в браузере клавишей F12, комбинацией клавиш Ctrl + Shift + I или в меню браузера → «Дополнительные инструменты» → «Инструменты разработчика». Подробнее об этом рассказывали в статье «Как открыть исходный код страницы».
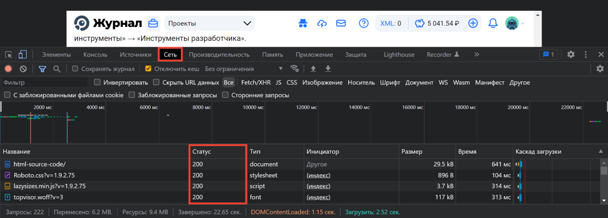
-
Переключитесь на вкладку «Сеть» в Инструментах разработчика и обновите страницу:
В Яндекс.Вебмастере
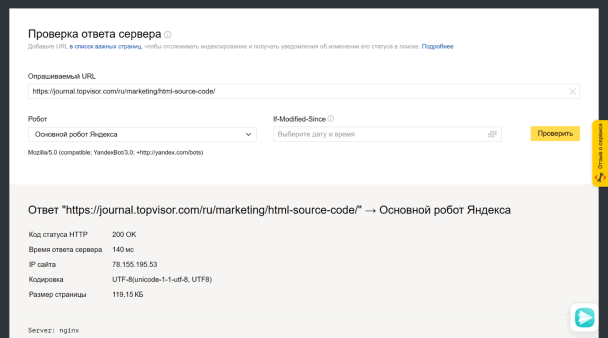
Откройте инструмент «Проверка ответа сервера» в Вебмастере. Введите URL в специальное поле и нажмите кнопку «Проверить»:
Как добавить сайт в Яндекс.Вебмастер и другие сервисы Яндекса
В Google Search Console
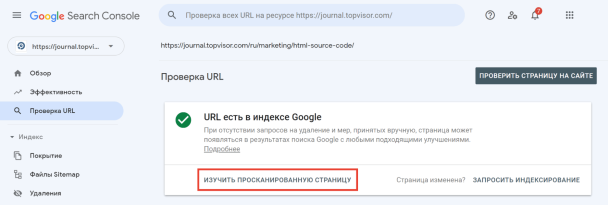
Чтобы посмотреть код ответа сервера в GSC, перейдите в инструмент проверки URL — он находится в самом верху панели:

Введите ссылку на страницу, которую хотите проверить, и нажмите Enter. В результатах проверки нажмите на «Изучить просканированную страницу» в блоке «URL есть в индексе Google».
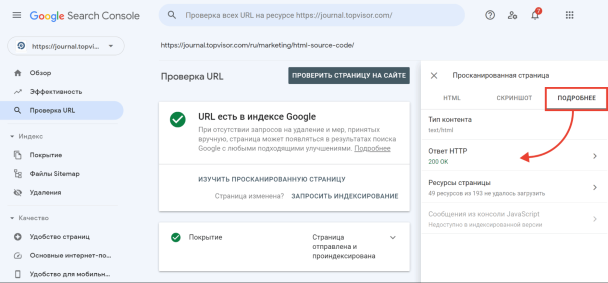
А затем в открывшемся окне перейдите на вкладку «Подробнее»:
Теперь расскажем подробнее про все классы кодов состояния HTTP.
1* класс кодов (информационные сообщения)
Это системный класс кодов, который только информирует о процессе передачи запроса. Такие ответы не являются ошибкой, хотя и могут отображаться в браузере как Error Code.
100 Continue
Этот ответ сообщает, что полученные сведения о запросе устраивают сервер и клиент может продолжать отправлять данные. Такой ответ может требоваться клиенту, если на сервер отправляется большой объём данных.
101 Switching Protocols
Сервер одобрил переключение типа протокола, которое запросил пользователь, и в настоящий момент выполняет действие.
102 Processing
Запрос принят — он находится в обработке, и на это понадобится чуть больше времени.
103 Checkpoint
Контрольная точка — используется в запросах для возобновления после прерывания запросов POST или PUT.
POST отправляет данные на сервер, PUT создает новый ресурс или заменяет существующий данными, представленными в теле запроса.
Разница между ними в том, что PUT работает без изменений: повторное его применение даёт такой же результат, что и в первый раз, а вот повторный вызов одного и того же метода POST часто меняет данные.
Пример — оформленный несколько раз интернет‑заказ. Такое часто происходит как раз по причине неоднократного использования запроса PUT.
105 Name Not Resolved
Не удается преобразовать DNS‑адрес сервера — это означает ошибку в службе DNS. Эта служба преобразует IP‑адреса в знакомые нам доменные имена.
2* класс кодов (успешно обработанные запросы)
Эти коды информируют об успешности принятия и обработки запроса. Также сервер может передать заголовки или тело сообщений.
200 ОК
Все хорошо — HTTP‑запрос успешно обработан (не ошибка).
201 Created
Создано — транзакция успешна, сформирован новый ресурс или документ.
202 Accepted
Принято — запрос принят, но ещё не обработан.
203 Non‑Authoritative Information
Информация не авторитетна — запрос успешно обработан, но передаваемая информация была взята не из первичного источника (данные могут быть устаревшими).
204 No Content
Нет содержимого — запрос успешно обработан, однако в ответе только заголовки без контента сообщения. Не нужно обновлять содержимое документа, но можно применить к нему полученные метаданные.
205 Reset Content
Сбросить содержимое. Запрос успешно обработан — но нужно сбросить введенные данные. Страницу можно не обновлять.
206 Partial Content
Частичное содержимое. Сервер успешно обработал часть GET‑запроса, а другую часть вернул.
GET — метод для чтения данных с сайта. Он говорит серверу, что клиент хочет прочитать какой‑то документ.
Представим интернет‑магазин и страницы каталога. Фильтры, которые выбирает пользователь, передаются благодаря методу GET. GET‑запрос работает с получением данных, а POST‑запрос нужен для отправки данных.
При работе с подобными ответами следует уделить внимание кэшированию.
207 Multi‑Status
Успешно выполнено несколько операций — сервер передал результаты выполнения нескольких независимых операций. Они появятся в виде XML‑документа с объектом multistatus.
226 IM Used
Успешно обработан IM‑заголовок (специальный заголовок, который отправляется клиентом и используется для передачи состояния HTTP).
3* класс кодов (перенаправление на другой адрес)
Эти коды информируют, что для достижения успешной операции нужно будет сделать другой запрос, возможно, по другому URL.
300 Multiple Choices
Множественный выбор — сервер выдает список нескольких возможных вариантов перенаправления (максимум — 5). Можно выбрать один из них.
301 Moved Permanently
Окончательно перемещено — страница перемещена на другой URL, который указан в поле Location.
302 Found/Moved
Временно перемещено — страница временно перенесена на другой URL, который указан в поле Location.
303 See Other
Ищите другую страницу — страница не найдена по данному URL, поэтому смотрите страницу по другому URL, используя метод GET.
304 Not Modified
Модификаций не было — с момента последнего визита клиента изменений не было.
305 Use Proxy
Используйте прокси — запрос к нужному ресурсу можно сделать только через прокси‑сервер, URL которого указан в поле Location заголовка.
306 Unused
Зарезервировано. Код в настоящий момент не используется.
307 Temporary Redirect
Временное перенаправление — запрашиваемый ресурс временно доступен по другому URL.
Этот код имеет ту же семантику, что код ответа 302 Found, за исключением того, что агент пользователя не должен изменять используемый метод HTTP: если в первом запросе использовался POST, то во втором запросе также должен использоваться POST.
308 Resume Incomplete
Перемещено полностью (навсегда) — запрашиваемая страница была перенесена на новый URL, указанный в поле Location заголовка. Метод запроса (GET/POST) менять не разрешается.
4* класс кодов (ошибки на стороне клиента)
Эти коды указывают на ошибки со стороны клиентов.
400 Bad Request
Неверный запрос — запрос клиента не может быть обработан, так как есть синтаксическая ошибка (возможно, опечатка).
401 Unauthorized
Не пройдена авторизация — запрос ещё в обработке, но доступа нет, так как пользователь не авторизован.
Для доступа к запрашиваемому ресурсу клиент должен представиться, послав запрос, включив при этом в заголовок сообщения поле Authorization.
402 Payment Required
Требуется оплата — зарезервировано для использования в будущем. Код предусмотрен для платных пользовательских сервисов, а не для хостинговых компаний.
403 Forbidden
Запрещено — запрос принят, но не будет обработан, так как у клиента недостаточно прав. Может возникнуть, когда пользователь хочет открыть системные файлы (robots, htaccess) или не прошёл авторизацию.
404 Not Found
Не найдено — запрашиваемая страница не обнаружена. Сервер принял запрос, но не нашёл ресурса по указанному URL (возможно, была ошибка в URL или страница была перемещена).
405 Method Not Allowed
Метод не разрешён — запрос был сделан методом, который не поддерживается данным ресурсом. Сервер должен предложить доступные методы решения в заголовке Allow.
406 Not Acceptable
Некорректный запрос — неподдерживаемый поисковиком формат запроса (поисковый робот не поддерживает кодировку или язык).
407 Proxy Authentication Required
Нужно пройти аутентификацию прокси — ответ аналогичен коду 401, только нужно аутентифицировать прокси‑сервер.
408 Request Timeout
Тайм‑аут запроса — запрос клиента занял слишком много времени. На каждом сайте существует свое время тайм‑аута — проверьте интернет‑соединение и просто обновите страницу.
409 Conflict
Конфликт (что‑то пошло не так) — запрос не может быть выполнен из‑за конфликтного обращения к ресурсу (несовместимость двух запросов).
410 Gone
Недоступно — ресурс раньше был размещён по указанному URL, но сейчас удалён и недоступен (серверу неизвестно месторасположение).
411 Length Required
Добавьте длины — сервер отклоняет отправляемый запрос, так как длина заголовка не определена, и он не находит значение Content‑Length.
Нужно исправить заголовки на сервере, и в следующий раз робот сможет проиндексировать страницу.
412 Precondition Failed
Предварительное условие не выполнено — стоит проверить правильность HTTP‑заголовков данного запроса.
413 Request Entity Too Large
Превышен размер запроса — перелимит максимального размера запроса, принимаемого сервером. Браузеры поддерживают запросы от 2 до 8 килобайт.
414 Request‑URI Too Long
Превышена длина запроса — сервер не может обработать запрос из‑за длинного URL. Такая ошибка может возникнуть, например, когда клиент пытается передать чересчур длинные параметры через метод GET, а не POST.
415 Unsupported Media Type
Формат не поддерживается — сервер не может принять запрос, так как данные подгружаются в некорректном формате, и сервер разрывает соединение.
416 Requested Range Not Satisfiable
Диапазон не поддерживается — ошибка возникает в случаях, когда в самом HTTP‑заголовке прописывается некорректный байтовый диапазон.
Корректного диапазона в необходимом документе может просто не быть, или есть опечатка в синтаксисе.
417 Expectation Failed
Ожидания не оправдались — прокси некорректно идентифицировал содержимое поля «Expect: 100‑Continue».
418 I’m a teapot
Первоапрельская шутка разработчиков в 1998 году. В расшифровке звучит как «я не приготовлю вам кофе, потому что я чайник». Не используется в работе.
422 Unprocessable Entity
Объект не обработан — сервер принял запрос, но в нём есть логическая ошибка. Стоит посмотреть в сторону семантики сайта.
423 Locked
Закрыто — ресурс заблокирован для выбранного HTTP‑метода. Можно перезагрузить роутер и компьютер. А также использовать только статистический IP.
424 Failed Dependency
Неуспешная зависимость — сервер не может обработать запрос, так как один из зависимых ресурсов заблокирован.
Выполнение запроса напрямую зависит от успешности выполнения другой операции, и если она не будет успешно завершена, то вся обработка запроса будет прервана.
425 Unordered Collection
Неверный порядок в коллекции — ошибка возникает, если клиент указал номер элемента в неупорядоченном списке или запросил несколько элементов в порядке, отличном от серверного.
426 Upgrade Required
Нужно обновление — в заголовке ответа нужно корректно сформировать поля Upgrade и Connection.
Этот ответ возникает, когда серверу требуется обновление до SSL‑протокола, но клиент не имеет его поддержки.
428 Precondition Required
Нужно предварительное условие — сервер просит внести в запрос информацию о предварительных условиях обработки данных, чтобы выдавать корректную информацию по итогу.
429 Too Many Requests
Слишком много запросов — отправлено слишком много запросов за короткое время. Это может указывать, например, на попытку DDoS‑атаки, для защиты от которой запросы блокируются.
431 Request Header Fields Too Large
Превышена длина заголовков — сервер может и не отвечать этим кодом, вместо этого он может просто сбросить соединение.
Исправляется это с помощью сокращения заголовков и повторной отправки запроса.
434 Requested Host Unavailable
Адрес запрашиваемой страницы недоступен.
444 No Response
Нет ответа — код отображается в лог‑файлах, чтобы подтвердить, что сервер никак не отреагировал на запрос пользователя и прервал соединение. Возвращается только сервером nginx.
Nginx — программное обеспечение с открытым исходным кодом. Его используют для создания веб‑серверов, а также в качестве почтового или обратного прокси‑сервера. Nginx решает проблему падения производительности из‑за роста трафика.
449 Retry With
Повторите попытку — ошибка говорит о необходимости скорректировать запрос и повторить его снова. Причиной становятся неверно указанные параметры (возможно, недостаточно данных).
450 Blocked by Windows Parental Controls
Заблокировано родительским контролем — говорит о том, что с компьютера попытались зайти на заблокированный ресурс. Избежать этой ошибки можно изменением параметров системы родительского контроля.
451 Unavailable For Legal Reasons
Недоступно по юридическим причинам — доступ к ресурсу закрыт, например, по требованию органов государственной власти или по требованию правообладателя в случае нарушения авторских прав.
456 Unrecoverable Error
Неустранимая ошибка — при обработке запроса возникла ошибка, которая вызывает некорректируемые сбои в таблицах баз данных.
499 Client Closed Request
Запрос закрыт клиентом — нестандартный код, используемый nginx в ситуациях, когда клиент закрыл соединение, пока nginx обрабатывал запрос.
5* класс кодов (ошибки на стороне сервера)
Эти коды указывают на ошибки со стороны серверов.
При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя. И его можно использовать в работе.
500 Internal Server Error
Внутренняя ошибка сервера — сервер столкнулся с неким условием, из‑за которого не может выполнить запрос.
Проверяйте, корректно ли указаны директивы в системных файлах (особенно htaccess) и нет ли ошибки прав доступа к файлам. Обратите внимание на ошибки внутри скриптов и их медленную работу.
501 Not Implemented
Не выполнено — код отдается, когда сам сервер не может идентифицировать метод запроса.
Сами вы эту ошибку не исправите. Устранить её может только сервер.
502 Bad Gateway
Ошибка шлюза — появляется, когда сервер, выступая в роли шлюза или прокси‑сервера, получил ответное сообщение от вышестоящего сервера о несоответствии протоколов.
Актуально исключительно для прокси и шлюзовых конфигураций.
503 Service Unavailable
Временно не доступен — сервер временно не имеет возможности обрабатывать запросы по техническим причинам (обслуживание, перегрузка и прочее).
В поле Retry‑After заголовка сервер укажет время, через которое можно повторить запрос.
504 Gateway Timeout
Тайм‑аут шлюза — сервер, выступая в роли шлюза или прокси‑сервера, не получил ответа от вышестоящего сервера в нужное время.
Исправить эту ошибку самостоятельно не получится. Здесь дело в прокси, часто — в веб‑сервере.
Первым делом просто обновите веб‑страницу. Если это не помогло, нужно почистить DNS‑кэш. Для этого нажмите горячие клавиши Windows+R и введите команду cmd (Control+пробел). В открывшемся окне укажите команду ipconfig / flushdns и подтвердите её нажатием Enter.
505 HTTP Version Not Supported
Сервер не поддерживает версию протокола — отсутствует поддержка текущей версии HTTP‑протокола. Нужно обеспечить клиента и сервер одинаковой версией.
506 Variant Also Negotiates
Неуспешные переговоры — с такой ошибкой сталкиваются, если сервер изначально настроен неправильно. По причине ошибочной конфигурации выбранный вариант указывает сам на себя, из‑за чего процесс и прерывается.
507 Insufficient Storage
Не хватает места для хранения — серверу недостаточно места в хранилище. Нужно либо расчистить место, либо увеличить доступное пространство.
508 Loop Detected
Обнаружен цикл — ошибка означает провал запроса и выполняемой операции в целом.
509 Bandwidth Limit Exceeded
Превышена пропускная способность — используется при чрезмерном потреблении трафика. Владельцу площадки следует обратиться к своему хостинг‑провайдеру.
510 Not Extended
Не продлён — ошибка говорит, что на сервере отсутствует нужное для клиента расширение. Чтобы исправить проблему, надо убрать часть неподдерживаемого расширения из запроса или добавить поддержку на сервер.
511 Network Authentication Required
Требуется аутентификация — ошибка генерируется сервером‑посредником, к примеру, сервером интернет‑провайдера, если нужно ввести пароль для получения доступа к сети через платную точку доступа.