Урок 18. Exceptions.
Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except.
Иерархия исключений выглядит вот так:
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
Exception – то, на чем фактически строятся все остальные ошибки;
AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
NameError – возникает, когда локальное или глобальное имя не найдено;
OSError – возникает, когда функция получает связанную с системой ошибку;
SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
Traceback (most recent call last): File "<string>", line 1, in <fragment> ZeroDivisionError: integer division or modulo by zero
try: 1 / 0 except ZeroDivisionError: print("You cannot divide by zero!")
>>> You cannot divide by zero!
Если мы обратимся к урокам элементарной математики, то вспомним, что на ноль делить нельзя. В Пайтоне данная операция вызовет ошибку, как мы можем видеть в примере выше. Чтобы поймать ошибку, мы завернем операцию в оператор try/except.
«Голое» исключение
Есть еще один способ поймать ошибку:
try: 1 / 0 except: print("You cannot divide by zero!") # ЭТО СРАБОТАЕТ, НО ТАК ДЕЛАТЬ НЕЛЬЗЯ
На жаргоне Пайтона, это известно как голое исключение, что означает, что будут найдены вообще все исключения. Причина, по которой так делать не рекомендуется, заключается в том, что вы не узнаете, что именно за исключение вы выловите. Когда у вас возникло что-то в духе ZeroDivisionError, вы хотите выявить фрагмент, в котором происходит деление на ноль. В коде, написанном выше, вы не можете указать, что именно вам нужно выявить. Давайте взглянем еще на несколько примеров:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except KeyError: print("That key does not exist!")
my_list = [1, 2, 3, 4, 5] try: my_list[6] except IndexError: print("That index is not in the list!")
В первом примере, мы создали словарь из трех элементов. После этого, мы попытались открыть доступ ключу, которого в словаре нет. Так как ключ не в словаре, возникает KeyError, которую мы выявили. Второй пример показывает список, длина которого состоит из пяти объектов. Мы попытались взять седьмой объект из индекса.
Помните, что списки в Пайтоне начинаются с нуля, так что когда вы говорите 6, вы запрашиваете 7. В любом случае, в нашем списке только пять объектов, по этой причине возникает IndexError, которую мы выявили. Вы также можете выявить несколько ошибок за раз при помощи одного оператора. Для этого существует несколько различных способов. Давайте посмотрим:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except IndexError: print("This index does not exist!") except KeyError: print("This key is not in the dictionary!") except: print("Some other error occurred!")
Это самый стандартный способ выявить несколько исключений. Сначала мы попробовали открыть доступ к несуществующему ключу, которого нет в нашем словаре. При помощи try/except мы проверили код на наличие ошибки KeyError, которая находится во втором операторе except. Обратите внимание на то, что в конце кода у нас появилась «голое» исключение. Обычно, это не рекомендуется, но вы, возможно, будете сталкиваться с этим время от времени, так что лучше быть проинформированным об этом. Кстати, также обратите внимание на то, что вам не нужно использовать целый блок кода для обработки нескольких исключений. Обычно, целый блок используется для выявления одного единственного исключения. Изучим второй способ выявления нескольких исключений:
try: value = my_dict["d"] except IndexError, KeyError: print("An IndexError or KeyError occurred!")
Обратите внимание на то, что в данном примере мы помещаем ошибки, которые мы хотим выявить, внутри круглых скобок. Проблема данного метода в том, что трудно сказать какая именно ошибка произошла, так что предыдущий пример, мы рекомендуем больше чем этот. Зачастую, когда происходит ошибка, вам нужно уведомить пользователя, при помощи сообщения.
В зависимости от сложности данной ошибки, вам может понадобиться выйти из программы. Иногда вам может понадобиться выполнить очистку, перед выходом из программы. Например, если вы открыли соединение с базой данных, вам нужно будет закрыть его, перед выходом из программы, или вы можете закончить с открытым соединением. Другой пример – закрытие дескриптора файла, к которому вы обращаетесь. Теперь нам нужно научиться убирать за собой. Это очень просто, если использовать оператор finally.
Оператор finally
Оператор finally очень прост в использовании. Давайте взглянем на нижеизложенный пример:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except KeyError: print("A KeyError occurred!") finally: print("The finally statement has executed!")
Если вы запустите это код, оно отобразиться и в операторе except и в finally. Весьма просто, не так ли? Теперь вы можете использовать оператор finally, чтобы убрать за собой. Вы можете также вписать код exit в конце оператора finally.
Попробуйте except или else
Оператор try/except также имеет пункт else. Он работает только в том случае, если в вашем коде нет ни единой ошибки. Давайте потратим немного времени и взглянем на парочку примеров:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["a"] except KeyError: print("A KeyError occurred!") else: print("No error occurred!")
Мы видим словарь, состоящий из трех элементов, и в операторе try/except мы открываем доступ к существующему ключу. Это работает, так что ошибка KeyError не возникает. Так как ошибки нет, else работает, и надпись “No error occurred!” появляется на экране. Теперь добавим оператор finally:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["a"] except KeyError: print("A KeyError occurred!") else: print("No error occurred!") finally: print("The finally statement ran!")
В данном коде работают и оператор else и finally. Большую часть времени вы не будете сталкиваться с оператором else, используемый в том или ином коде, который следует за оператором try/except, если ни одна ошибка не была найдена. Единственное полезное применение оператора else, которое я видел, это когда вы хотите запустить вторую часть кода, в которой может быть ошибка. Конечно, если ошибка возникает в else, то она не будет поймана.
Оператор raise
Если в вашем коде какие-либо данные не соответсвуют вашим ожиданиям, вы всегда можете вызвать исключение если вам это необходимо, для этого используется ключевое слово raise.
def even_the_odds(odds): if odds % 2 != 1: raise ValueError("Did not get an odd number") return odds + 1
Любое исключение завершает наш код, а значит, что до возврата в случае исключения функция не дойдет.
Мы можем использовать raise внутри любой конструкции, допустим нам нужно отправлять ошибку на сторонний сервис, но не обрабатывать её
try: do_stuff(resource) except SomeException as e: log_error(e) raise # re-raise the error finally: free_expensive_resource(resource)
raise в этом случае просто повторится
еще один такой пример
try: 5 / 0 except ZeroDivisionError: print("Got an error") raise
Имейте в виду, однако, что кто-то еще выше в стеке вызовов может все же перехватить исключение и как-то обработать его. Готовый вывод может быть неприятным в этом случае, потому что это произойдет в любом случае (пойман или не пойман). Поэтому может быть лучше создать другое исключение, содержащее ваш комментарий о ситуации, а также исходное исключение:
try: 5 / 0 except ZeroDivisionError as e: raise ZeroDivisionError("Got an error", e)
в переменной e будет хранится вся информация о исключении, и таким рейзом мы вызовем нужный нам тип исключения, с нашим коментарием, и всей системной информацией.
Исключения тоже объекты
Исключением являются только обычные объекты Python , которые наследуют от встроенного BaseException . Сценарий Python может использовать raise заявление , чтобы прервать выполнение, в результате чего Python для печати трассировки стеки из стека вызовов в этой точке и представление экземпляра исключения.
Например:
>>> def failing_function(): ... raise ValueError('Example error!') >>> failing_function() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in failing_function ValueError: Example error!
который говорит , что ValueError с сообщением ‘Example error!’ был поднят нашей failing_function() , который был выполнен в интерпретаторе.
Код вызова может выбрать обработку любых исключений, которые может вызвать вызов:
>>> try: ... failing_function() ... except ValueError: ... print('Handled the error') Handled the error
Или вывесли оригинальный текст:
>>> try: ... failing_function() ... except ValueError as e: ... print('Caught exception', repr(e)) Caught exception ValueError('Example error!',)
Создание пользовательских типов исключений
Создайте класс , унаследованный от Exception :
class FooException(Exception): pass try: raise FooException("insert description here") except FooException: print("A FooException was raised.")
или другой тип исключения:
class NegativeError(ValueError): pass def foo(x): # function that only accepts positive values of x if x < 0: raise NegativeError("Cannot process negative numbers") ... # rest of function body try: result = foo(int(input("Enter a positive integer: "))) # raw_input in Python 2.x except NegativeError: print("You entered a negative number!") else: print("The result was " + str(result))
Урок 18. Exceptions.
Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except.
Иерархия исключений выглядит вот так:
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
Exception – то, на чем фактически строятся все остальные ошибки;
AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
NameError – возникает, когда локальное или глобальное имя не найдено;
OSError – возникает, когда функция получает связанную с системой ошибку;
SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
Traceback (most recent call last): File "<string>", line 1, in <fragment> ZeroDivisionError: integer division or modulo by zero
try: 1 / 0 except ZeroDivisionError: print("You cannot divide by zero!")
>>> You cannot divide by zero!
Если мы обратимся к урокам элементарной математики, то вспомним, что на ноль делить нельзя. В Пайтоне данная операция вызовет ошибку, как мы можем видеть в примере выше. Чтобы поймать ошибку, мы завернем операцию в оператор try/except.
«Голое» исключение
Есть еще один способ поймать ошибку:
try: 1 / 0 except: print("You cannot divide by zero!") # ЭТО СРАБОТАЕТ, НО ТАК ДЕЛАТЬ НЕЛЬЗЯ
На жаргоне Пайтона, это известно как голое исключение, что означает, что будут найдены вообще все исключения. Причина, по которой так делать не рекомендуется, заключается в том, что вы не узнаете, что именно за исключение вы выловите. Когда у вас возникло что-то в духе ZeroDivisionError, вы хотите выявить фрагмент, в котором происходит деление на ноль. В коде, написанном выше, вы не можете указать, что именно вам нужно выявить. Давайте взглянем еще на несколько примеров:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except KeyError: print("That key does not exist!")
my_list = [1, 2, 3, 4, 5] try: my_list[6] except IndexError: print("That index is not in the list!")
В первом примере, мы создали словарь из трех элементов. После этого, мы попытались открыть доступ ключу, которого в словаре нет. Так как ключ не в словаре, возникает KeyError, которую мы выявили. Второй пример показывает список, длина которого состоит из пяти объектов. Мы попытались взять седьмой объект из индекса.
Помните, что списки в Пайтоне начинаются с нуля, так что когда вы говорите 6, вы запрашиваете 7. В любом случае, в нашем списке только пять объектов, по этой причине возникает IndexError, которую мы выявили. Вы также можете выявить несколько ошибок за раз при помощи одного оператора. Для этого существует несколько различных способов. Давайте посмотрим:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except IndexError: print("This index does not exist!") except KeyError: print("This key is not in the dictionary!") except: print("Some other error occurred!")
Это самый стандартный способ выявить несколько исключений. Сначала мы попробовали открыть доступ к несуществующему ключу, которого нет в нашем словаре. При помощи try/except мы проверили код на наличие ошибки KeyError, которая находится во втором операторе except. Обратите внимание на то, что в конце кода у нас появилась «голое» исключение. Обычно, это не рекомендуется, но вы, возможно, будете сталкиваться с этим время от времени, так что лучше быть проинформированным об этом. Кстати, также обратите внимание на то, что вам не нужно использовать целый блок кода для обработки нескольких исключений. Обычно, целый блок используется для выявления одного единственного исключения. Изучим второй способ выявления нескольких исключений:
try: value = my_dict["d"] except IndexError, KeyError: print("An IndexError or KeyError occurred!")
Обратите внимание на то, что в данном примере мы помещаем ошибки, которые мы хотим выявить, внутри круглых скобок. Проблема данного метода в том, что трудно сказать какая именно ошибка произошла, так что предыдущий пример, мы рекомендуем больше чем этот. Зачастую, когда происходит ошибка, вам нужно уведомить пользователя, при помощи сообщения.
В зависимости от сложности данной ошибки, вам может понадобиться выйти из программы. Иногда вам может понадобиться выполнить очистку, перед выходом из программы. Например, если вы открыли соединение с базой данных, вам нужно будет закрыть его, перед выходом из программы, или вы можете закончить с открытым соединением. Другой пример – закрытие дескриптора файла, к которому вы обращаетесь. Теперь нам нужно научиться убирать за собой. Это очень просто, если использовать оператор finally.
Оператор finally
Оператор finally очень прост в использовании. Давайте взглянем на нижеизложенный пример:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["d"] except KeyError: print("A KeyError occurred!") finally: print("The finally statement has executed!")
Если вы запустите это код, оно отобразиться и в операторе except и в finally. Весьма просто, не так ли? Теперь вы можете использовать оператор finally, чтобы убрать за собой. Вы можете также вписать код exit в конце оператора finally.
Попробуйте except или else
Оператор try/except также имеет пункт else. Он работает только в том случае, если в вашем коде нет ни единой ошибки. Давайте потратим немного времени и взглянем на парочку примеров:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["a"] except KeyError: print("A KeyError occurred!") else: print("No error occurred!")
Мы видим словарь, состоящий из трех элементов, и в операторе try/except мы открываем доступ к существующему ключу. Это работает, так что ошибка KeyError не возникает. Так как ошибки нет, else работает, и надпись “No error occurred!” появляется на экране. Теперь добавим оператор finally:
my_dict = {"a":1, "b":2, "c":3} try: value = my_dict["a"] except KeyError: print("A KeyError occurred!") else: print("No error occurred!") finally: print("The finally statement ran!")
В данном коде работают и оператор else и finally. Большую часть времени вы не будете сталкиваться с оператором else, используемый в том или ином коде, который следует за оператором try/except, если ни одна ошибка не была найдена. Единственное полезное применение оператора else, которое я видел, это когда вы хотите запустить вторую часть кода, в которой может быть ошибка. Конечно, если ошибка возникает в else, то она не будет поймана.
Оператор raise
Если в вашем коде какие-либо данные не соответсвуют вашим ожиданиям, вы всегда можете вызвать исключение если вам это необходимо, для этого используется ключевое слово raise.
def even_the_odds(odds): if odds % 2 != 1: raise ValueError("Did not get an odd number") return odds + 1
Любое исключение завершает наш код, а значит, что до возврата в случае исключения функция не дойдет.
Мы можем использовать raise внутри любой конструкции, допустим нам нужно отправлять ошибку на сторонний сервис, но не обрабатывать её
try: do_stuff(resource) except SomeException as e: log_error(e) raise # re-raise the error finally: free_expensive_resource(resource)
raise в этом случае просто повторится
еще один такой пример
try: 5 / 0 except ZeroDivisionError: print("Got an error") raise
Имейте в виду, однако, что кто-то еще выше в стеке вызовов может все же перехватить исключение и как-то обработать его. Готовый вывод может быть неприятным в этом случае, потому что это произойдет в любом случае (пойман или не пойман). Поэтому может быть лучше создать другое исключение, содержащее ваш комментарий о ситуации, а также исходное исключение:
try: 5 / 0 except ZeroDivisionError as e: raise ZeroDivisionError("Got an error", e)
в переменной e будет хранится вся информация о исключении, и таким рейзом мы вызовем нужный нам тип исключения, с нашим коментарием, и всей системной информацией.
Исключения тоже объекты
Исключением являются только обычные объекты Python , которые наследуют от встроенного BaseException . Сценарий Python может использовать raise заявление , чтобы прервать выполнение, в результате чего Python для печати трассировки стеки из стека вызовов в этой точке и представление экземпляра исключения.
Например:
>>> def failing_function(): ... raise ValueError('Example error!') >>> failing_function() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in failing_function ValueError: Example error!
который говорит , что ValueError с сообщением ‘Example error!’ был поднят нашей failing_function() , который был выполнен в интерпретаторе.
Код вызова может выбрать обработку любых исключений, которые может вызвать вызов:
>>> try: ... failing_function() ... except ValueError: ... print('Handled the error') Handled the error
Или вывесли оригинальный текст:
>>> try: ... failing_function() ... except ValueError as e: ... print('Caught exception', repr(e)) Caught exception ValueError('Example error!',)
Создание пользовательских типов исключений
Создайте класс , унаследованный от Exception :
class FooException(Exception): pass try: raise FooException("insert description here") except FooException: print("A FooException was raised.")
или другой тип исключения:
class NegativeError(ValueError): pass def foo(x): # function that only accepts positive values of x if x < 0: raise NegativeError("Cannot process negative numbers") ... # rest of function body try: result = foo(int(input("Enter a positive integer: "))) # raw_input in Python 2.x except NegativeError: print("You entered a negative number!") else: print("The result was " + str(result))
Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except. В данном разделе мы рассмотрим следующие понятия:
- Базовые типы исключений;
- Обработка исключений при помощи try/except;
- Узнаем, как работает try/except/finally;
- Выясним, как работает оператор else совместно с try/except;
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Вы уже сталкивались со множеством исключений. Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
- Exception – то, на чем фактически строятся все остальные ошибки;
- AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
- IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
- ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
- IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
- KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
- KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
- NameError – возникает, когда локальное или глобальное имя не найдено;
- OSError – возникает, когда функция получает связанную с системой ошибку;
- SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
- TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
- ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
- ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто. В целом, если вы заинтересованы, вы можете узнать больше о них в документации Пайтон.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
|
1 / 0 Traceback (most recent call last): File «<string>», line 1, in <fragment> ZeroDivisionError: integer division or modulo by zero |
|
try: 1 / 0 except ZeroDivisionError: print(«You cannot divide by zero!») |
Если мы обратимся к урокам элементарной математики, то вспомним, что на ноль делить нельзя. В Пайтоне данная операция вызовет ошибку, как мы можем видеть в примере выше. Чтобы поймать ошибку, мы завернем операцию в оператор try/except.
«Голое» исключение
Есть еще один способ поймать ошибку:
|
try: 1 / 0 except: print(«You cannot divide by zero!») |
Но мы его не рекомендуем. На жаргоне Пайтона, это известно как голое исключение, что означает, что будут найдены вообще все исключения. Причина, по которой так делать не рекомендуется, заключается в том, что вы не узнаете, что именно за исключение вы выловите. Когда у вас возникло что-то в духе ZeroDivisionError, вы хотите выявить фрагмент, в котором происходит деление на ноль. В коде, написанном выше, вы не можете указать, что именно вам нужно выявить. Давайте взглянем еще на несколько примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«That key does not exist!») |
|
my_list = [1, 2, 3, 4, 5] try: my_list[6] except IndexError: print(«That index is not in the list!») |
В первом примере, мы создали словарь из трех элементов. После этого, мы попытались открыть доступ ключу, которого в словаре нет. Так как ключ не в словаре, возникает KeyError, которую мы выявили. Второй пример показывает список, длина которого состоит из пяти объектов. Мы попытались взять седьмой объект из индекса.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Помните, что списки в Пайтоне начинаются с нуля, так что когда вы говорите 6, вы запрашиваете 7. В любом случае, в нашем списке только пять объектов, по этой причине возникает IndexError, которую мы выявили. Вы также можете выявить несколько ошибок за раз при помощи одного оператора. Для этого существует несколько различных способов. Давайте посмотрим:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except IndexError: print(«This index does not exist!») except KeyError: print(«This key is not in the dictionary!») except: print(«Some other error occurred!») |
Это самый стандартный способ выявить несколько исключений. Сначала мы попробовали открыть доступ к несуществующему ключу, которого нет в нашем словаре. При помощи try/except мы проверили код на наличие ошибки KeyError, которая находится во втором операторе except. Обратите внимание на то, что в конце кода у нас появилась «голое» исключение. Обычно, это не рекомендуется, но вы, возможно, будете сталкиваться с этим время от времени, так что лучше быть проинформированным об этом. Кстати, также обратите внимание на то, что вам не нужно использовать целый блок кода для обработки нескольких исключений. Обычно, целый блок используется для выявления одного единственного исключения. Изучим второй способ выявления нескольких исключений:
|
try: value = my_dict[«d»] except (IndexError, KeyError): print(«An IndexError or KeyError occurred!») |
Обратите внимание на то, что в данном примере мы помещаем ошибки, которые мы хотим выявить, внутри круглых скобок. Проблема данного метода в том, что трудно сказать какая именно ошибка произошла, так что предыдущий пример, мы рекомендуем больше чем этот. Зачастую, когда происходит ошибка, вам нужно уведомить пользователя, при помощи сообщения.
В зависимости от сложности данной ошибки, вам может понадобиться выйти из программы. Иногда вам может понадобиться выполнить очистку, перед выходом из программы. Например, если вы открыли соединение с базой данных, вам нужно будет закрыть его, перед выходом из программы, или вы можете закончить с открытым соединением. Другой пример – закрытие дескриптора файла, к которому вы обращаетесь. Теперь нам нужно научиться убирать за собой. Это очень просто, если использовать оператор finally.
Оператор finally
Оператор finally очень прост в использовании. Давайте взглянем на нижеизложенный пример:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«A KeyError occurred!») finally: print(«The finally statement has executed!») |
Если вы запустите это код, оно отобразиться и в операторе except и в finally. Весьма просто, не так ли? Теперь вы можете использовать оператор finally, чтобы убрать за собой. Вы можете также вписать код exit в конце оператора finally.
Попробуйте except или else
Оператор try/except также имеет пункт else. Он работает только в том случае, если в вашем коде нет ни единой ошибки. Давайте потратим немного времени и взглянем на парочку примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») |
Мы видим словарь, состоящий из трех элементов, и в операторе try/except мы открываем доступ к существующему ключу. Это работает, так что ошибка KeyError не возникает. Так как ошибки нет, else работает, и надпись“No error occurred!” появляется на экране. Теперь добавим оператор finally:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») finally: print(«The finally statement ran!») |
В данном коде работают и оператор else и finally. Большую часть времени вы не будете сталкиваться с оператором else, используемый в том или ином коде, который следует за оператором try/except, если ни одна ошибка не была найдена. Единственное полезное применение оператора else, которое я видел, это когда вы хотите запустить вторую часть кода, в которой может быть ошибка. Конечно, если ошибка возникает в else, то она не будет поймана.
Подведем итоги
Теперь вы можете выявлять исключения в вашем коде. Если вы обнаружили, что в вашем коде есть ошибка, то теперь вы знаете, как выявить её и спокойно выйти из программы, или продолжить спокойно работать.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
python-scripts.com
Обработка исключений в Python
автор
9-12 минут
Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except. В данном разделе мы рассмотрим следующие понятия:
- Базовые типы исключений;
- Обработка исключений при помощи try/except;
- Узнаем, как работает try/except/finally;
- Выясним, как работает оператор else совместно с try/except;
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Вы уже сталкивались со множеством исключений. Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
- Exception – то, на чем фактически строятся все остальные ошибки;
- AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
- IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
- ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
- IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
- KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
- KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
- NameError – возникает, когда локальное или глобальное имя не найдено;
- OSError – возникает, когда функция получает связанную с системой ошибку;
- SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
- TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
- ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
- ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто. В целом, если вы заинтересованы, вы можете узнать больше о них в документации Пайтон.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
|
1 / 0 Traceback (most recent call last): File «<string>», line 1, in <fragment> ZeroDivisionError: integer division or modulo by zero |
|
try: 1 / 0 except ZeroDivisionError: print(«You cannot divide by zero!») |
Если мы обратимся к урокам элементарной математики, то вспомним, что на ноль делить нельзя. В Пайтоне данная операция вызовет ошибку, как мы можем видеть в примере выше. Чтобы поймать ошибку, мы завернем операцию в оператор try/except.
«Голое» исключение
Есть еще один способ поймать ошибку:
|
try: 1 / 0 except: print(«You cannot divide by zero!») |
Но мы его не рекомендуем. На жаргоне Пайтона, это известно как голое исключение, что означает, что будут найдены вообще все исключения. Причина, по которой так делать не рекомендуется, заключается в том, что вы не узнаете, что именно за исключение вы выловите. Когда у вас возникло что-то в духе ZeroDivisionError, вы хотите выявить фрагмент, в котором происходит деление на ноль. В коде, написанном выше, вы не можете указать, что именно вам нужно выявить. Давайте взглянем еще на несколько примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«That key does not exist!») |
|
my_list = [1, 2, 3, 4, 5] try: my_list[6] except IndexError: print(«That index is not in the list!») |
В первом примере, мы создали словарь из трех элементов. После этого, мы попытались открыть доступ ключу, которого в словаре нет. Так как ключ не в словаре, возникает KeyError, которую мы выявили. Второй пример показывает список, длина которого состоит из пяти объектов. Мы попытались взять седьмой объект из индекса.
Помните, что списки в Пайтоне начинаются с нуля, так что когда вы говорите 6, вы запрашиваете 7. В любом случае, в нашем списке только пять объектов, по этой причине возникает IndexError, которую мы выявили. Вы также можете выявить несколько ошибок за раз при помощи одного оператора. Для этого существует несколько различных способов. Давайте посмотрим:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except IndexError: print(«This index does not exist!») except KeyError: print(«This key is not in the dictionary!») except: print(«Some other error occurred!») |
Это самый стандартный способ выявить несколько исключений. Сначала мы попробовали открыть доступ к несуществующему ключу, которого нет в нашем словаре. При помощи try/except мы проверили код на наличие ошибки KeyError, которая находится во втором операторе except. Обратите внимание на то, что в конце кода у нас появилась «голое» исключение. Обычно, это не рекомендуется, но вы, возможно, будете сталкиваться с этим время от времени, так что лучше быть проинформированным об этом. Кстати, также обратите внимание на то, что вам не нужно использовать целый блок кода для обработки нескольких исключений. Обычно, целый блок используется для выявления одного единственного исключения. Изучим второй способ выявления нескольких исключений:
|
try: value = my_dict[«d»] except (IndexError, KeyError): print(«An IndexError or KeyError occurred!») |
Обратите внимание на то, что в данном примере мы помещаем ошибки, которые мы хотим выявить, внутри круглых скобок. Проблема данного метода в том, что трудно сказать какая именно ошибка произошла, так что предыдущий пример, мы рекомендуем больше чем этот. Зачастую, когда происходит ошибка, вам нужно уведомить пользователя, при помощи сообщения.
В зависимости от сложности данной ошибки, вам может понадобиться выйти из программы. Иногда вам может понадобиться выполнить очистку, перед выходом из программы. Например, если вы открыли соединение с базой данных, вам нужно будет закрыть его, перед выходом из программы, или вы можете закончить с открытым соединением. Другой пример – закрытие дескриптора файла, к которому вы обращаетесь. Теперь нам нужно научиться убирать за собой. Это очень просто, если использовать оператор finally.
Оператор finally
Оператор finally очень прост в использовании. Давайте взглянем на нижеизложенный пример:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«A KeyError occurred!») finally: print(«The finally statement has executed!») |
Если вы запустите это код, оно отобразиться и в операторе except и в finally. Весьма просто, не так ли? Теперь вы можете использовать оператор finally, чтобы убрать за собой. Вы можете также вписать код exit в конце оператора finally.
Попробуйте except или else
Оператор try/except также имеет пункт else. Он работает только в том случае, если в вашем коде нет ни единой ошибки. Давайте потратим немного времени и взглянем на парочку примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») |
Мы видим словарь, состоящий из трех элементов, и в операторе try/except мы открываем доступ к существующему ключу. Это работает, так что ошибка KeyError не возникает. Так как ошибки нет, else работает, и надпись“No error occurred!” появляется на экране. Теперь добавим оператор finally:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») finally: print(«The finally statement ran!») |
В данном коде работают и оператор else и finally. Большую часть времени вы не будете сталкиваться с оператором else, используемый в том или ином коде, который следует за оператором try/except, если ни одна ошибка не была найдена. Единственное полезное применение оператора else, которое я видел, это когда вы хотите запустить вторую часть кода, в которой может быть ошибка. Конечно, если ошибка возникает в else, то она не будет поймана.
Подведем итоги
Теперь вы можете выявлять исключения в вашем коде. Если вы обнаружили, что в вашем коде есть ошибка, то теперь вы знаете, как выявить её и спокойно выйти из программы, или продолжить спокойно работать.
В
модели компилятора синтаксический
анализатор получает строку лексем с
выхода лексического
анализатора, как показано на рис. 21, и
проверяет,
может ли эта строка порождаться
грамматикой исходного языка. Он также
сообщает обо всех выявленных ошибках.
Кроме того, он должен уметь обрабатывать
обычно часто
встречающиеся ошибки и продолжать
работу
с оставшейся частью программы.
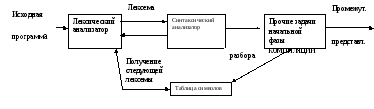
Дерево
Рис. 21. Место
синтаксического анализатора в модели
компилятора
Имеется три основных
типа синтаксических анализаторов
грамматик.
-
Универсальные
методы разбора, такие как алгоритмы
Кока-Янгера-Касами или Эрли, могут
работать с любой грамматикой. Однако
эти методы слишком неэффективны для
использования в промышленных компиляторах. -
Нисходящие (сверху
вниз) методы синтаксического анализа.
Нисходящие синтаксические
анализаторы строят дерево разбора
сверху (от корня) вниз (к листьям). Входной
поток синтаксического анализатора
сканируется посимвольно слева направо. -
Восходящие (снизу
вверх) методы синтаксического анализа.
Восходящие методы начинают построение
дерева разбора с листьев и идут к корню.
Входной поток также сканируется
посимвольно слева направо.
Восходящие
и нисходящие методы синтаксического
анализа наиболее распространены в
компиляторах.
Наиболее
эффективные нисходящие и восходящие
методы работают только с подклассами
грамматик, однако некоторые из этих
подклассов, такие как LL-
и LR-грамматики,
достаточно выразительны для описания
большинства синтаксических конструкций
языков программирования. Реализованные
вручную синтаксические анализа-торы
чаще работают с LL-грамматиками.
Синтаксические
анализаторы для несколько
большего класса LR-грамматик
обычно создаются с помощью автоматизированных
инструментов.
Выходом
синтаксического анализатора является
некоторое
представление дерева разбора входного
потока лексем, выданного лексическим
анализатором. На практике имеется
множество задач, которые могут сопровождать
процесс
разбора, — например, сбор информации о
различных лексемах в таблице символов,
исполнение
проверки типов и других видов семантического
анализа, а также создание промежуточного
кода.
5.3 Обработка синтаксических ошибок
Если
компилятор будет иметь дело исключительно
с корректными программами, его разработка
и реализация существенно упрощаются.
Однако программисты пишут программы с
ошибками, и хороший компилятор должен
помочь программисту обнаружить их и
локализовать. Большинство
спецификаций
языков программирования не определяет
реакции компилятора на ошибки — этот
вопрос отдается на откуп разработчикам
компилятора. Однако планирование
системы обработки ошибок с самого начала
работы над компилятором может, как
упростить
его структуру, так и улучшить его реакцию
на ошибки.
Любая
программа потенциально содержит
множество ошибок самого разного
уровня. Например, ошибки могут быть
-
лексическими,
такими как неверно записанные
идентификаторы, ключевые слова или
операторы;
-
синтаксическими,
например арифметические выражения с
несбалансированными скобками;
-
семантическими,
такими как операторы, применяемые к
несовместимым с ними операндам;
-
логическими,
например бесконечная рекурсия.
Основные
действия по выявлению ошибок и
восстановлению после них решаются на
этапе синтаксического
анализа. Одна из причин этого состоит
в том, что
многие ошибки по природе своей являются
синтаксическими или проявляются, когда
поток
лексем, идущий от лексического анализатора,
нарушает определяющие язык программирования
грамматические правила. Вторая причина
заключается в точности современных
методов разбора — они очень эффективно
выявляют синтаксические ошибки в
программе. Определение присутствия в
программе семантических или логических
ошибок
— задача более сложная.
Обработчик
ошибок синтаксического анализатора
имеет очень просто формулируемые
цели:
-
он должен ясно и
точно сообщать о наличии ошибок;
-
он должен
обеспечивать быстрое восстановление
после ошибки, чтобы продолжить поиск
последующих ошибок.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Синтакси́ческий ана́лиз (или разбор, жарг. (b) па́рсинг ← англ. (b) parsing) в лингвистике (b) и информатике (b) — процесс сопоставления линейной последовательности лексем (b) (слов, токенов) естественного (b) или формального языка (b) с его формальной грамматикой (b) . Результатом обычно является дерево разбора (синтаксическое дерево). Обычно применяется совместно с лексическим анализом (b) .
Синтаксический анализатор (b) (жарг. (b) па́рсер ← англ. (b) parser) — это программа или часть программы, выполняющая синтаксический анализ.

В ходе синтаксического анализа исходный текст преобразуется в структуру данных (b) , обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки.
Как правило, результатом синтаксического анализа является синтаксическое строение предложения, представленное либо в виде дерева зависимостей (b) , либо в виде дерева составляющих (b) , либо в виде некоторого сочетания первого и второго способов представления.
Область применения
Всё что угодно, имеющее «синтаксис (b) », поддается автоматическому анализу.
- Языки программирования (b) — разбор исходного кода языков программирования, в процессе трансляции (b) (компиляции (b) или интерпретации (b) );
- Структурированные данные — данные, языки их описания, оформления и т. д. Например, XML (b) , HTML (b) , CSS (b) , JSON (b) , ini-файлы, специализированные конфигурационные файлы и т. п.;
- Построение индекса (b) в поисковой системе (b) ;
- SQL (b) -запросы (DSL (b) -язык);
- Математические выражения;
- Регулярные выражения (b) (которые, в свою очередь, могут использоваться для автоматизации лексического анализа (b) );
- Формальные грамматики (b) ;
- Лингвистика (b) — естественные языки. Например, машинный перевод (b) и другие генераторы текстов (b) .
- Извлечение данных веб-страниц — веб-скрейпинг (b) , является частным случаем парсинга[1].
Типы алгоритмов
- Нисходящий парсер (b) (англ. (b) top-down parser) — продукции грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов (b) .
- Метод рекурсивного спуска (b)
- LL-анализатор (b)
- Восходящий парсер (b) [en] (англ. (b) bottom-up parser) — продукции восстанавливаются из правых частей, начиная с токенов и заканчивая стартовым символом.
- LR-анализатор (b)
- GLR-парсер (b)
Восстановление после ошибок
Простейший способ реагирования на некорректную входную цепочку лексем — завершить синтаксический анализ и вывести сообщение об ошибке. Однако часто оказывается полезным найти за одну попытку синтаксического анализа как можно больше ошибок. Именно так ведут себя трансляторы большинства распространённых языков программирования.
Таким образом, перед обработчиком ошибок синтаксического анализатора стоят следующие задачи:
- он должен ясно и точно сообщать о наличии ошибок;
- он должен обеспечивать быстрое восстановление после ошибки, чтобы продолжать поиск других ошибок;
- он не должен существенно замедлять обработку корректной входной цепочки.
Ниже описаны наиболее известные стратегии восстановления после ошибок.
Восстановление в режиме паники
При обнаружении ошибки синтаксический анализатор пропускает входные лексемы по одной, пока не будет найдена одна из специально определённого множества синхронизирующих лексем. Обычно такими лексемами являются разделители, например: ;, ) или }. Набор синхронизирующих лексем должен определять разработчик анализируемого языка. При такой стратегии восстановления может оказаться, что значительное количество символов будут пропущены без проверки на наличие дополнительных ошибок. Данная стратегия восстановления наиболее проста в реализации.
Восстановление на уровне фразы
Иногда при обнаружении ошибки синтаксический анализатор может выполнить локальную коррекцию входного потока так, чтобы это позволило ему продолжать работу. Например, перед точкой с запятой, отделяющей различные операторы в языке программирования, синтаксический анализатор может закрыть все ещё не закрытые круглые скобки. Это более сложный в проектировании и реализации способ, однако в некоторых ситуациях, он может работать значительно лучше восстановления в режиме паники. Естественно, данная стратегия бессильна, если настоящая ошибка произошла до точки обнаружения ошибки синтаксическим анализатором.
Продукции ошибок
Знание наиболее распространённых ошибок позволяет расширить грамматику языка продукциями, порождающими ошибочные конструкции. При срабатывании таких продукций регистрируется ошибка, но синтаксический анализатор продолжает работать в обычном режиме.
Средства разработки анализаторов
Отдельные этапы разработки и построения трансляторов могут быть автоматизированы и выполнены компьютером. (b)
Вот некоторые из наиболее известных средств разработки анализаторов[2]:
- ANTLR (b) — генератор парсеров
- Bison (b) — генератор парсеров
- Coco/R (b) — генератор сканера и парсера
- GOLD (b) — парсер
- JavaCC (b) — генератор парсеров для языка Java (b)
- Lemon Parser (b) — генератор парсеров
- Lex (b) — генератор сканеров
- Ragel (b) — генератор встраиваемых парсеров
- Spirit Parser Framework (b) — генератор парсеров
- SYNTAX
- Syntax Definition Formalism (b) [en]
- UltraGram
- VivaCore
- Yacc (b) — генератор парсеров
См. также сравнение генераторов парсеров (b) [en].
См. также
- Компилятор компиляторов (b)
- Синтаксически управляемая трансляция (b)
- Регулярные выражения (b)
Примечания
- ↑ Тим Джонс М. Извлечение информация из Интернета при использовании языка Ruby. (22 мая 2014). Дата обращения: 13 декабря 2019. Архивировано 13 декабря 2019 года.
- ↑ Ela Kumar. Natural Language Processing. — I. K. International Pvt Ltd, 2011. — P. 100. — ISBN 978-93-80578-77-4.
Литература
- А. Ахо (b) , Дж. Ульман. (b) Теория синтаксического анализа, перевода и компиляции. Т. 1. Пер. с англ. В. Н. Агафонова под ред. В. М. Курочкина (b) . М.: Мир, 1978. 614 с.
- А. Ахо, Дж. Ульман. Теория синтаксического анализа, перевода и компиляции. Т. 2. Пер. с англ. А. Н. Бирюкова и В. А. Серебрякова (b) под ред. В. М. Курочкина. М.: Мир, 1978. 487 с.
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс (b) , 2008. — ISBN 978-5-8459-1349-4.
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: «Вильямс» (b) , 2002. — С. 256. — ISBN 5-8459-0360-2.
Ссылки
- Трансляция кода (рус.)
What are the syntax errors?
PHP belongs to the C-style and imperative programming languages. It has rigid grammar rules, which it cannot recover from when encountering misplaced symbols or identifiers. It can’t guess your coding intentions.

Most important tips
There are a few basic precautions you can always take:
-
Use proper code indentation, or adopt any lofty coding style.
Readability prevents irregularities. -
Use an IDE or editor for PHP with syntax highlighting.
Which also help with parentheses/bracket balancing.
-
Read the language reference and examples in the manual.
Twice, to become somewhat proficient.
How to interpret parser errors
A typical syntax error message reads:
Parse error: syntax error, unexpected T_STRING, expecting ‘
;‘ in file.php on line 217
Which lists the possible location of a syntax mistake. See the mentioned file name and line number.
A moniker such as T_STRING explains which symbol the parser/tokenizer couldn’t process finally. This isn’t necessarily the cause of the syntax mistake, however.
It’s important to look into previous code lines as well. Often syntax errors are just mishaps that happened earlier. The error line number is just where the parser conclusively gave up to process it all.
Solving syntax errors
There are many approaches to narrow down and fix syntax hiccups.
-
Open the mentioned source file. Look at the mentioned code line.
-
For runaway strings and misplaced operators, this is usually where you find the culprit.
-
Read the line left to right and imagine what each symbol does.
-
-
More regularly you need to look at preceding lines as well.
-
In particular, missing
;semicolons are missing at the previous line ends/statement. (At least from the stylistic viewpoint. ) -
If
{code blocks}are incorrectly closed or nested, you may need to investigate even further up the source code. Use proper code indentation to simplify that.
-
-
Look at the syntax colorization!
-
Strings and variables and constants should all have different colors.
-
Operators
+-*/.should be tinted distinct as well. Else they might be in the wrong context. -
If you see string colorization extend too far or too short, then you have found an unescaped or missing closing
"or'string marker. -
Having two same-colored punctuation characters next to each other can also mean trouble. Usually, operators are lone if it’s not
++,--, or parentheses following an operator. Two strings/identifiers directly following each other are incorrect in most contexts.
-
-
Whitespace is your friend.
Follow any coding style. -
Break up long lines temporarily.
-
You can freely add newlines between operators or constants and strings. The parser will then concretize the line number for parsing errors. Instead of looking at the very lengthy code, you can isolate the missing or misplaced syntax symbol.
-
Split up complex
ifstatements into distinct or nestedifconditions. -
Instead of lengthy math formulas or logic chains, use temporary variables to simplify the code. (More readable = fewer errors.)
-
Add newlines between:
- The code you can easily identify as correct,
- The parts you’re unsure about,
- And the lines which the parser complains about.
Partitioning up long code blocks really helps to locate the origin of syntax errors.
-
-
Comment out offending code.
-
If you can’t isolate the problem source, start to comment out (and thus temporarily remove) blocks of code.
-
As soon as you got rid of the parsing error, you have found the problem source. Look more closely there.
-
Sometimes you want to temporarily remove complete function/method blocks. (In case of unmatched curly braces and wrongly indented code.)
-
When you can’t resolve the syntax issue, try to rewrite the commented out sections from scratch.
-
-
As a newcomer, avoid some of the confusing syntax constructs.
-
The ternary
? :condition operator can compact code and is useful indeed. But it doesn’t aid readability in all cases. Prefer plainifstatements while unversed. -
PHP’s alternative syntax (
if:/elseif:/endif;) is common for templates, but arguably less easy to follow than normal{code}blocks.
-
-
The most prevalent newcomer mistakes are:
-
Missing semicolons
;for terminating statements/lines. -
Mismatched string quotes for
"or'and unescaped quotes within. -
Forgotten operators, in particular for the string
.concatenation. -
Unbalanced
(parentheses). Count them in the reported line. Are there an equal number of them?
-
-
Don’t forget that solving one syntax problem can uncover the next.
-
If you make one issue go away, but other crops up in some code below, you’re mostly on the right path.
-
If after editing a new syntax error crops up in the same line, then your attempted change was possibly a failure. (Not always though.)
-
-
Restore a backup of previously working code, if you can’t fix it.
- Adopt a source code versioning system. You can always view a
diffof the broken and last working version. Which might be enlightening as to what the syntax problem is.
- Adopt a source code versioning system. You can always view a
-
Invisible stray Unicode characters: In some cases, you need to use a hexeditor or different editor/viewer on your source. Some problems cannot be found just from looking at your code.
-
Try
grep --color -P -n "[x80-xFF]" file.phpas the first measure to find non-ASCII symbols. -
In particular BOMs, zero-width spaces, or non-breaking spaces, and smart quotes regularly can find their way into the source code.
-
-
Take care of which type of linebreaks are saved in files.
-
PHP just honors n newlines, not r carriage returns.
-
Which is occasionally an issue for MacOS users (even on OS X for misconfigured editors).
-
It often only surfaces as an issue when single-line
//or#comments are used. Multiline/*...*/comments do seldom disturb the parser when linebreaks get ignored.
-
-
If your syntax error does not transmit over the web:
It happens that you have a syntax error on your machine. But posting the very same file online does not exhibit it anymore. Which can only mean one of two things:-
You are looking at the wrong file!
-
Or your code contained invisible stray Unicode (see above).
You can easily find out: Just copy your code back from the web form into your text editor.
-
-
Check your PHP version. Not all syntax constructs are available on every server.
-
php -vfor the command line interpreter -
<?php phpinfo();for the one invoked through the webserver.
Those aren’t necessarily the same. In particular when working with frameworks, you will them to match up.
-
-
Don’t use PHP’s reserved keywords as identifiers for functions/methods, classes or constants.
-
Trial-and-error is your last resort.
If all else fails, you can always google your error message. Syntax symbols aren’t as easy to search for (Stack Overflow itself is indexed by SymbolHound though). Therefore it may take looking through a few more pages before you find something relevant.
Further guides:
- PHP Debugging Basics by David Sklar
- Fixing PHP Errors by Jason McCreary
- PHP Errors – 10 Common Mistakes by Mario Lurig
- Common PHP Errors and Solutions
- How to Troubleshoot and Fix your WordPress Website
- A Guide To PHP Error Messages For Designers — Smashing Magazine
White screen of death
If your website is just blank, then typically a syntax error is the cause.
Enable their display with:
error_reporting = E_ALLdisplay_errors = 1
In your php.ini generally, or via .htaccess for mod_php,
or even .user.ini with FastCGI setups.
Enabling it within the broken script is too late because PHP can’t even interpret/run the first line. A quick workaround is crafting a wrapper script, say test.php:
<?php
error_reporting(E_ALL);
ini_set("display_errors", 1);
include("./broken-script.php");
Then invoke the failing code by accessing this wrapper script.
It also helps to enable PHP’s error_log and look into your webserver’s error.log when a script crashes with HTTP 500 responses.
What are the syntax errors?
PHP belongs to the C-style and imperative programming languages. It has rigid grammar rules, which it cannot recover from when encountering misplaced symbols or identifiers. It can’t guess your coding intentions.
Most important tips
There are a few basic precautions you can always take:
-
Use proper code indentation, or adopt any lofty coding style.
Readability prevents irregularities. -
Use an IDE or editor for PHP with syntax highlighting.
Which also help with parentheses/bracket balancing. -
Read the language reference and examples in the manual.
Twice, to become somewhat proficient.
How to interpret parser errors
A typical syntax error message reads:
Parse error: syntax error, unexpected T_STRING, expecting ‘
;‘ in file.php on line 217
Which lists the possible location of a syntax mistake. See the mentioned file name and line number.
A moniker such as T_STRING explains which symbol the parser/tokenizer couldn’t process finally. This isn’t necessarily the cause of the syntax mistake, however.
It’s important to look into previous code lines as well. Often syntax errors are just mishaps that happened earlier. The error line number is just where the parser conclusively gave up to process it all.
Solving syntax errors
There are many approaches to narrow down and fix syntax hiccups.
-
Open the mentioned source file. Look at the mentioned code line.
-
For runaway strings and misplaced operators, this is usually where you find the culprit.
-
Read the line left to right and imagine what each symbol does.
-
-
More regularly you need to look at preceding lines as well.
-
In particular, missing
;semicolons are missing at the previous line ends/statement. (At least from the stylistic viewpoint. ) -
If
{code blocks}are incorrectly closed or nested, you may need to investigate even further up the source code. Use proper code indentation to simplify that.
-
-
Look at the syntax colorization!
-
Strings and variables and constants should all have different colors.
-
Operators
+-*/.should be tinted distinct as well. Else they might be in the wrong context. -
If you see string colorization extend too far or too short, then you have found an unescaped or missing closing
"or'string marker. -
Having two same-colored punctuation characters next to each other can also mean trouble. Usually, operators are lone if it’s not
++,--, or parentheses following an operator. Two strings/identifiers directly following each other are incorrect in most contexts.
-
-
Whitespace is your friend.
Follow any coding style. -
Break up long lines temporarily.
-
You can freely add newlines between operators or constants and strings. The parser will then concretize the line number for parsing errors. Instead of looking at the very lengthy code, you can isolate the missing or misplaced syntax symbol.
-
Split up complex
ifstatements into distinct or nestedifconditions. -
Instead of lengthy math formulas or logic chains, use temporary variables to simplify the code. (More readable = fewer errors.)
-
Add newlines between:
- The code you can easily identify as correct,
- The parts you’re unsure about,
- And the lines which the parser complains about.
Partitioning up long code blocks really helps to locate the origin of syntax errors.
-
-
Comment out offending code.
-
If you can’t isolate the problem source, start to comment out (and thus temporarily remove) blocks of code.
-
As soon as you got rid of the parsing error, you have found the problem source. Look more closely there.
-
Sometimes you want to temporarily remove complete function/method blocks. (In case of unmatched curly braces and wrongly indented code.)
-
When you can’t resolve the syntax issue, try to rewrite the commented out sections from scratch.
-
-
As a newcomer, avoid some of the confusing syntax constructs.
-
The ternary
? :condition operator can compact code and is useful indeed. But it doesn’t aid readability in all cases. Prefer plainifstatements while unversed. -
PHP’s alternative syntax (
if:/elseif:/endif;) is common for templates, but arguably less easy to follow than normal{code}blocks.
-
-
The most prevalent newcomer mistakes are:
-
Missing semicolons
;for terminating statements/lines. -
Mismatched string quotes for
"or'and unescaped quotes within. -
Forgotten operators, in particular for the string
.concatenation. -
Unbalanced
(parentheses). Count them in the reported line. Are there an equal number of them?
-
-
Don’t forget that solving one syntax problem can uncover the next.
-
If you make one issue go away, but other crops up in some code below, you’re mostly on the right path.
-
If after editing a new syntax error crops up in the same line, then your attempted change was possibly a failure. (Not always though.)
-
-
Restore a backup of previously working code, if you can’t fix it.
- Adopt a source code versioning system. You can always view a
diffof the broken and last working version. Which might be enlightening as to what the syntax problem is.
- Adopt a source code versioning system. You can always view a
-
Invisible stray Unicode characters: In some cases, you need to use a hexeditor or different editor/viewer on your source. Some problems cannot be found just from looking at your code.
-
Try
grep --color -P -n "[x80-xFF]" file.phpas the first measure to find non-ASCII symbols. -
In particular BOMs, zero-width spaces, or non-breaking spaces, and smart quotes regularly can find their way into the source code.
-
-
Take care of which type of linebreaks are saved in files.
-
PHP just honors n newlines, not r carriage returns.
-
Which is occasionally an issue for MacOS users (even on OS X for misconfigured editors).
-
It often only surfaces as an issue when single-line
//or#comments are used. Multiline/*...*/comments do seldom disturb the parser when linebreaks get ignored.
-
-
If your syntax error does not transmit over the web:
It happens that you have a syntax error on your machine. But posting the very same file online does not exhibit it anymore. Which can only mean one of two things:-
You are looking at the wrong file!
-
Or your code contained invisible stray Unicode (see above).
You can easily find out: Just copy your code back from the web form into your text editor.
-
-
Check your PHP version. Not all syntax constructs are available on every server.
-
php -vfor the command line interpreter -
<?php phpinfo();for the one invoked through the webserver.
Those aren’t necessarily the same. In particular when working with frameworks, you will them to match up.
-
-
Don’t use PHP’s reserved keywords as identifiers for functions/methods, classes or constants.
-
Trial-and-error is your last resort.
If all else fails, you can always google your error message. Syntax symbols aren’t as easy to search for (Stack Overflow itself is indexed by SymbolHound though). Therefore it may take looking through a few more pages before you find something relevant.
Further guides:
- PHP Debugging Basics by David Sklar
- Fixing PHP Errors by Jason McCreary
- PHP Errors – 10 Common Mistakes by Mario Lurig
- Common PHP Errors and Solutions
- How to Troubleshoot and Fix your WordPress Website
- A Guide To PHP Error Messages For Designers — Smashing Magazine
White screen of death
If your website is just blank, then typically a syntax error is the cause.
Enable their display with:
error_reporting = E_ALLdisplay_errors = 1
In your php.ini generally, or via .htaccess for mod_php,
or even .user.ini with FastCGI setups.
Enabling it within the broken script is too late because PHP can’t even interpret/run the first line. A quick workaround is crafting a wrapper script, say test.php:
<?php
error_reporting(E_ALL);
ini_set("display_errors", 1);
include("./broken-script.php");
Then invoke the failing code by accessing this wrapper script.
It also helps to enable PHP’s error_log and look into your webserver’s error.log when a script crashes with HTTP 500 responses.
Открытость операционной системы Android позволяет устанавливать приложения разными способами. Это можно делать как через специализированные приложения вроде Google Play, так и через APK-файлы, то есть вручную. И в тот момент, когда пользователь выбирает второй вариант установки, при попытке открыть APK на экране появляется ошибка при синтаксическом анализе пакета. Проблема является довольно частой, но, к счастью, поддается решению. Давайте посмотрим, что мы можем сделать при возникновении синтаксической ошибки.

Чаще всего ошибка появляется на старых версиях Андроид
Содержание
- 1 Что такое синтаксический анализ пакета
- 2 Как исправить синтаксический анализ пакета
- 2.1 Как переименовать файл
- 2.2 Файл поврежден
- 2.3 Старая версия Андроид
- 2.4 Как переместить файл
- 3 Где скачать APK
Что такое синтаксический анализ пакета
Сначала разберемся, с чем мы имеем дело, и какое отношение к Android имеет синтаксис, знакомый нам по школьному курсу русского языка. В лингвистике синтаксической ошибкой называют нарушение связи слов в предложении. В программировании это понятие имеет схожее значение и, если не углубляться в подробности, ошибка синтаксического анализа на Андроид — проблема, вызванная отсутствием совместимости между действующей конфигурацией операционной системы и APK (пакетом).
⚡ Подпишись на Androidinsider в Дзене, где мы публикуем эксклюзивные материалы
Подобного рода неполадки чаще всего дают о себе знать на устройствах со старой версией Android. Но это не значит, что исправить ошибку синтаксического анализа пакета можно только обновлением Андроид. Просто старые версии операционной системы имеют ряд особенностей, которые не позволяют установить каждый APK, несмотря на заявленную совместимость.
Как исправить синтаксический анализ пакета

Попробуйте установить приложение через Google Play
Поскольку ошибка при синтаксическом анализе пакета Андроид возникает в процессе ручной установки APK, в первую очередь рекомендую инсталлировать приложение через магазин Google Play. Там все файлы проверяются на вирусы, а несовместимый софт даже не отображается в списке. Если ваше приложение отсутствует в магазине, попробуйте установить APK в соответствии с рекомендациями, изложенными здесь. Если и это не поможет — действуйте по нашей инструкции, и решение точно найдется.
❗ Поделись своим мнением или задай вопрос в нашем телеграм-чате
Как переименовать файл
Как я уже сказал, ошибка при синтаксическом анализе обычно возникает на смартфонах со старым Android. Особенностью устройств на ранних версиях операционной системы является то, что они не могут прочитать содержимое APK-файла с большим количеством символов. Тот же Android 7 вводят в ступор лишние точки в названии. Следовательно, для решения проблемы нужно переименовать файл:
- Найдите проблемный APK.
- Выделите файл.
- Нажмите кнопку «Еще».
- Выберите опцию «Переименовать».
- Присвойте файлу короткое имя, состоящее из латинских символов.

Присвойте файлу имя попроще
С высокой долей вероятности после внесения изменений в название файла ошибка синтаксического анализа пакета при установке исчезнет. Если нет — воспользуйтесь следующим вариантом решения проблемы.
Файл поврежден
Также неполадки при синтаксическом анализе пакета бывают вызваны повреждением APK. Что я имею в виду? Во-первых, файл мог загрузиться не до конца. Естественно, в таком случае установочный пакет будет не полным, и смартфон не сможет прочитать его содержимое. Почему это произошло — другой вопрос. Либо в процессе загрузки прервалось интернет-соединение, либо на смартфоне закончилась память. Что делать в таком случае — читайте тут.
🔥 Загляни в телеграм-канал Сундук Али-Бабы, где мы собрали лучшие товары с АлиЭкспресс
Еще не стоит исключать вероятность изначального повреждения файла. То есть APK мог быть залит на сайт, откуда вы его скачивали, в неисправном виде. Единственная рекомендация в такой ситуации — скачать APK-файл через другой источник. В конце я приведу несколько примеров, откуда загрузить APK бесплатно и безопасно.
Старая версия Андроид

Возможно, стоит задумать об обновлении ОС или покупке нового смартфона
Конечно, проблема могла возникнуть и по причине устаревшей версии Android. Да, подавляющее большинство приложений работает и на Android 7, но с каждым обновлением системные требования становятся более жесткими. Поэтому настоятельно рекомендую проверить версию Андроид на телефоне, в чем вам поможет отдельный материал. Затем сопоставьте ее с требованиями, указанными на странице приложения.
Отмечу также, что многие люди жалуются на ошибку при синтаксическом анализе пакета на телевизоре. Если на вашем ТВ-приемнике установлена операционная система Android TV, то при установке APK обязательно проверяйте совместимость. Приложение изначально должно быть предназначено для телевизионного Андроид.
Как переместить файл
Если при синтаксическом анализе пакета возникла неполадка, убедитесь, что сам APK-файл находится во внутренней памяти телефона. Конечно, приложения можно устанавливать и с карты памяти. Однако, если вы покупали дешевую MicroSD-карту, такая возможность будет заблокирована из-за низкой скорости записи или повреждения файловой системы. Для решения проблемы нужно просто переместить файл во внутреннюю память:
- Выделите APK-файл.
- Нажмите кнопку «Переместить».
- Укажите любую папку на внутреннем накопителе и подтвердите перемещение.

Устанавливайте приложения через APK, которые хранятся во внутренней памяти
Наконец, выделю еще несколько факторов, которые теоретически могли стать причиной появления ошибки при синтаксическом анализе пакета Android. Это конфликт с одним из установленных на телефоне приложений и блокировка неизвестных APK антивирусом. Обязательно учитывайте данные факторы.
⚡ Подпишись на Androidinsider в Пульс Mail.ru, чтобы получать новости из мира Андроид первым
Где скачать APK
Итак, у APK ошибка при синтаксическом анализе пакета очень часто возникает по причине неисправного или поврежденного файла. Минимизировать риски помогают специальные веб-магазины, откуда можно бесплатно скачать APK:
- APKMirror;
- APKPure;
- APK Store.
Подробнее о каждом из этих магазинов мы рассказывали здесь, так что не забывайте читать и другие материалы на нашем сайте, которые помогут вам оставаться в курсе новостей, а также решить распространенные проблемы.
Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except. В данном разделе мы рассмотрим следующие понятия:
- Базовые типы исключений;
- Обработка исключений при помощи try/except;
- Узнаем, как работает try/except/finally;
- Выясним, как работает оператор else совместно с try/except;
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Вы уже сталкивались со множеством исключений. Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
- Exception – то, на чем фактически строятся все остальные ошибки;
- AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
- IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
- ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
- IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
- KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
- KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
- NameError – возникает, когда локальное или глобальное имя не найдено;
- OSError – возникает, когда функция получает связанную с системой ошибку;
- SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
- TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
- ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
- ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто. В целом, если вы заинтересованы, вы можете узнать больше о них в документации Пайтон.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
|
1 / 0 Traceback (most recent call last): File «<string>», line 1, in <fragment> ZeroDivisionError: integer division or modulo by zero |
|
try: 1 / 0 except ZeroDivisionError: print(«You cannot divide by zero!») |
Если мы обратимся к урокам элементарной математики, то вспомним, что на ноль делить нельзя. В Пайтоне данная операция вызовет ошибку, как мы можем видеть в примере выше. Чтобы поймать ошибку, мы завернем операцию в оператор try/except.
«Голое» исключение
Есть еще один способ поймать ошибку:
|
try: 1 / 0 except: print(«You cannot divide by zero!») |
Но мы его не рекомендуем. На жаргоне Пайтона, это известно как голое исключение, что означает, что будут найдены вообще все исключения. Причина, по которой так делать не рекомендуется, заключается в том, что вы не узнаете, что именно за исключение вы выловите. Когда у вас возникло что-то в духе ZeroDivisionError, вы хотите выявить фрагмент, в котором происходит деление на ноль. В коде, написанном выше, вы не можете указать, что именно вам нужно выявить. Давайте взглянем еще на несколько примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«That key does not exist!») |
|
my_list = [1, 2, 3, 4, 5] try: my_list[6] except IndexError: print(«That index is not in the list!») |
В первом примере, мы создали словарь из трех элементов. После этого, мы попытались открыть доступ ключу, которого в словаре нет. Так как ключ не в словаре, возникает KeyError, которую мы выявили. Второй пример показывает список, длина которого состоит из пяти объектов. Мы попытались взять седьмой объект из индекса.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Помните, что списки в Пайтоне начинаются с нуля, так что когда вы говорите 6, вы запрашиваете 7. В любом случае, в нашем списке только пять объектов, по этой причине возникает IndexError, которую мы выявили. Вы также можете выявить несколько ошибок за раз при помощи одного оператора. Для этого существует несколько различных способов. Давайте посмотрим:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except IndexError: print(«This index does not exist!») except KeyError: print(«This key is not in the dictionary!») except: print(«Some other error occurred!») |
Это самый стандартный способ выявить несколько исключений. Сначала мы попробовали открыть доступ к несуществующему ключу, которого нет в нашем словаре. При помощи try/except мы проверили код на наличие ошибки KeyError, которая находится во втором операторе except. Обратите внимание на то, что в конце кода у нас появилась «голое» исключение. Обычно, это не рекомендуется, но вы, возможно, будете сталкиваться с этим время от времени, так что лучше быть проинформированным об этом. Кстати, также обратите внимание на то, что вам не нужно использовать целый блок кода для обработки нескольких исключений. Обычно, целый блок используется для выявления одного единственного исключения. Изучим второй способ выявления нескольких исключений:
|
try: value = my_dict[«d»] except (IndexError, KeyError): print(«An IndexError or KeyError occurred!») |
Обратите внимание на то, что в данном примере мы помещаем ошибки, которые мы хотим выявить, внутри круглых скобок. Проблема данного метода в том, что трудно сказать какая именно ошибка произошла, так что предыдущий пример, мы рекомендуем больше чем этот. Зачастую, когда происходит ошибка, вам нужно уведомить пользователя, при помощи сообщения.
В зависимости от сложности данной ошибки, вам может понадобиться выйти из программы. Иногда вам может понадобиться выполнить очистку, перед выходом из программы. Например, если вы открыли соединение с базой данных, вам нужно будет закрыть его, перед выходом из программы, или вы можете закончить с открытым соединением. Другой пример – закрытие дескриптора файла, к которому вы обращаетесь. Теперь нам нужно научиться убирать за собой. Это очень просто, если использовать оператор finally.
Оператор finally
Оператор finally очень прост в использовании. Давайте взглянем на нижеизложенный пример:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«d»] except KeyError: print(«A KeyError occurred!») finally: print(«The finally statement has executed!») |
Если вы запустите это код, оно отобразиться и в операторе except и в finally. Весьма просто, не так ли? Теперь вы можете использовать оператор finally, чтобы убрать за собой. Вы можете также вписать код exit в конце оператора finally.
Попробуйте except или else
Оператор try/except также имеет пункт else. Он работает только в том случае, если в вашем коде нет ни единой ошибки. Давайте потратим немного времени и взглянем на парочку примеров:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») |
Мы видим словарь, состоящий из трех элементов, и в операторе try/except мы открываем доступ к существующему ключу. Это работает, так что ошибка KeyError не возникает. Так как ошибки нет, else работает, и надпись“No error occurred!” появляется на экране. Теперь добавим оператор finally:
|
my_dict = {«a»:1, «b»:2, «c»:3} try: value = my_dict[«a»] except KeyError: print(«A KeyError occurred!») else: print(«No error occurred!») finally: print(«The finally statement ran!») |
В данном коде работают и оператор else и finally. Большую часть времени вы не будете сталкиваться с оператором else, используемый в том или ином коде, который следует за оператором try/except, если ни одна ошибка не была найдена. Единственное полезное применение оператора else, которое я видел, это когда вы хотите запустить вторую часть кода, в которой может быть ошибка. Конечно, если ошибка возникает в else, то она не будет поймана.
Подведем итоги
Теперь вы можете выявлять исключения в вашем коде. Если вы обнаружили, что в вашем коде есть ошибка, то теперь вы знаете, как выявить её и спокойно выйти из программы, или продолжить спокойно работать.
Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Ошибки и исключения.
Программируя на Питоне, вы наверняка встречались с различными ошибками. Самые простые из них – синтаксические. Такие ошибки обнаруживаются во время трансляции кода на Питоне и появляются чаще всего из-за невнимательности программиста. Второй тип ошибок – ошибки пользователя или операционной системы, которые называются иначе исключительными ситуациями, например, деление на нуль. Необходимо постараться предусмотреть возможность обработки таких ошибок (о том, как это сделать будет рассказано далее). Самые сложные ошибки – логические, которые возникают из-за неправильной(то есть непредусмотренной создателем) работы программы. Способов избежать таких ошибок нет – надо быть внимательным при написании своего кода, правильно его отлаживать и писать максимально комментированным, чтобы упростить обнаружение ошибок, как самим автором, так и теми, кто собирается этот код модифицировать.
Ошибки такого типа обычно находятся интерпретатором:
>>> while 1 print ‘Hello world’
while 1 print ‘Hello world’
SyntaxError: invalid syntax #Неверный синтаксис команды
Старайтесь избегать подобных ошибок(хотя, конечно, полностью от них избавиться не удастся), так как они легко могут превратиться в логические.
Возникают либо при ошибке работы пользователя, либо при ошибке в логике программы. Исключительных ситуаций существует много: деление на нуль, использование несуществующего модуля или переменной, многие стандартные функции также генерируют исключения в случае неверной работы. Приведём примеры таких ситуаций:
Traceback (most recent call last):
ZeroDivisionError: integer division or modulo # Деление на нуль
Traceback (most recent call last):
#Нет такого имени переменной
Traceback (most recent call last):
TypeError: illegal argument type for built-in operation #Смешение разных типов
Конечно, всё было бы отлично, если пользователя удовлетворяли подобные сообщения, я лично в этом сильно сомневаюсь. Кроме этого, исключения могут генерировать ся в любой момент программы, что может вызвать потерю данных. По всем этим причинам желательно предусматривать возможность перехватывать исключения. Для этого используется блок try, который исполняет операторы внутри блока, но если возбуждается исключение, то оператор try ищет обработчик исключения(прерывая исполнение блока кода внутри try), обозначаемый except имя_исключения . Если обработчик не найден, то он ищется в других блоках try, если он не найден, то возникает непредвиденное(unhandled) исключение, которое отображается, как в предыдущем примере. Блок try выполняется до конца при отсутствии исключительных ситуаций, блоки except при этом пропускаются:
. x = int(raw_input(«Введите число «)) #Здесь может возникнуть исключение
. break #Если всё правильно, то выходим из бесконечного while
. except ValueError: #А вот здесь обрабатывается исключение неверного формата числа
. print »Ой-ой. Неправильное число. Попробуйте снова. «
Оператор except может принимать несколько имён исключений, оформленных в скобках через запятую:
. except (RuntimeError, TypeError, NameError):
Обработчики исключений могут принимать некоторые параметры, причём их число и последовательность специфична для каждого типа исключения. Также есть возможность создавать обработчик исключений по умолчанию, который обрабатывает все исключения, для которых не был определён конкретный обработчик:
import string, sys
except IOError, (errno, strerror):
print «I/O ошибка(%s): %s» % (errno, strerror)
print «Не могу преобразовать это в целое.»
print «Неожиданная ошибка:», sys.exc_info()[0] #Имя последнего исключения
raise #Возбуждение данного исключения ещё раз(см. далее)
В блоке try имеется дополнительный оператор else, который выполняется, при отсутствии исключений в блоке try:
for arg in sys.argv[1:]:
print ‘не могу открыть’, arg
print arg, ‘имеет длину в ‘, len(f.readlines()), ‘ строк’
Обработчики исключений способны обрабатывать исключения не только непосредственно в блоке try, но и в функциях, вызываемых из этого блока, например:
. this_fails() #Функция, вызывающая исключительную ситуацию
. except ZeroDivisionError, detail:
. print ‘Возбуждено исключение:’, detail
Возбуждено исключение: integer division or modulo
Программное возбуждение исключений.
Если вы пишете библиотеки функций, то одним из способов сообщить вызывающей программе о том, что случилась непредвиденная ситуация, является возбуждения исключений. Для этой цели используется оператор raise, который возбуждает заданное исключение. Оператор raise имеет следующий синтаксис: raise имя_исключения[, аргумент_исключения, аргумент_исключения . ]. Если raise вызывается без аргументов, то она возбуждает повторно самое последнее исключение:
>>> raise NameError, ‘HiThere’
Traceback (most recent call last):
raise без параметров часто используется в промежуточных обработчиках исключений:
. raise NameError, ‘HiThere’
. print ‘Произошла ошибка!’
Traceback (most recent call last):
В Питоне можно создавать собственные типы исключений в виде классов. Но эта тема будет рассмотрена в разделе классы и объектно-ориентированное программирование, потому что все исключения – это классы.
Часто исключения бывают критическими, то есть после того, как они возникнут дальнейшее продолжение программы не является целесообразным. Но при завершении программы необходимо, например, закрыть все файлы, записать несохранённые данные на диск, послать отчёт автору. Для этого используется конструкция try. __finally:
. print ‘Goodbye, world!’
Traceback (most recent call last):
__finally блок выполняется независимо от того произошло исключение или нет, если исключение произошло, то оно возбуждается ещё раз. Оператор try может иметь или блоки except или __finally, но не одновременно. Блок __finally выполняется даже во вложенных try, поэтому использование вложенных try(с except) и внешнего с __finally способно отловить и корректно обработать любые возникшие исключения.
Справочник
Исключения (exceptions) — ещё один тип данных в python. Исключения необходимы для того, чтобы сообщать программисту об ошибках. Самый простой пример исключения — деление на ноль. Если попробовать запустить такую программу
она завершится с ошибкой
ZeroDivisionError — это название исключения, а division by zero — его краткое описание. Также Python сообщит номер строки, где это исключение возникло.
Разумеется, возможны и другие исключения. Например, при попытке сложить строку и число
произойдет исключение TypeError
В этом примере генерируется исключение TypeError. Подсказки дают нам полную информацию о том, где порождено исключение, и с чем оно связано.
Рассмотрим иерархию встроенных в python исключений, хотя иногда вам могут встретиться и другие, так как программисты могут создавать собственные исключения.
BaseException — базовое исключение, от которого берут начало все остальные.
- SystemExit — исключение, порождаемое функцией sys.exit при выходе из программы.
- KeyboardInterrupt — порождается при прерывании программы пользователем (обычно сочетанием клавиш Ctrl+C).
- GeneratorExit — порождается при вызове метода close объекта generator.
- Exception — а вот тут уже заканчиваются полностью системные исключения (их лучше не трогать) и начинаются обыкновенные, с которыми можно работать.
- StopIteration — порождается встроенной функцией next, если в итераторе больше нет элементов.
- ArithmeticError — арифметическая ошибка.
- FloatingPointError — порождается при неудачном выполнении операции с плавающей запятой. На практике встречается нечасто.
- OverflowError — возникает, когда результат арифметической операции слишком велик для представления. Не появляется при обычной работе с целыми числами (так как python поддерживает длинные числа), но может возникать в некоторых других случаях.
- ZeroDivisionError — деление на ноль.
- IndexError — индекс не входит в диапазон элементов.
- KeyError — несуществующий ключ (в словаре, множестве или другом объекте).
- UnboundLocalError — сделана ссылка на локальную переменную в функции, но переменная не определена ранее.
- BlockingIOError
- ChildProcessError — неудача при операции с дочерним процессом.
- ConnectionError — базовый класс для исключений, связанных с подключениями.
- BrokenPipeError
- ConnectionAbortedError
- ConnectionRefusedError
- ConnectionResetError
- IndentationError — неправильные отступы.
- TabError — смешивание в отступах табуляции и пробелов.
- UnicodeEncodeError — исключение, связанное с кодированием unicode.
- UnicodeDecodeError — исключение, связанное с декодированием unicode.
- UnicodeTranslateError — исключение, связанное с переводом unicode.
Warning — Базовый класс для исключений-предупреждений. Данное семейство исключений представляет собой различные категории предупреждений.
- BYTESWARNING — Предупреждения, связанные с возможными проблемами при работе с байтами. Данная категория предупреждений используется в случаях возможных ошибок при работе с бйтами (bytes и bytearray).
- DeprecationWarning — Категория предупреждений о функциональности нежелательной к использованию. Эту категорию обычно используют для указания на то, что некая часть функциональности морально устарела (возможно ей на смену пришла более совершенная) и не рекомендуется к использованию.
- FUTUREWARNING — Категория, описывающая предупреждения об изменениях в будущем. Предупреждения данной категории призваны оповещать о грядущих [семантических] изменениях.
Пример предупреждения о грядущих изменениях из numpy :
FutureWarning: comparison to ‘ None ‘ will result in an elementwise object comparison in the future. - IMPORTWARNING — предупреждение о вероятной ошибке при импорте модуля. Предупреждения данной категории могут использоваться, например, в случаях внесения изменений в систему импорта при помощи перехватчиков (хуков).
- PendingDeprecationWarning — Категория предупреждений о функциональности, которая вскоре должна стать нежелательной к использованию.
- ResourceWarning — Предупреждения, связанные с возможными проблемами при работе с ресурсами. Примером использования данной категории предупреждений можут служить указание на необходимость закрытия сокета, что необходимо для высвобождения ресурсов.
- RuntimeWarning — Предупреждение о сомнительном поведении во время исполнения. Категория может быть использована для обозначения сомнительного поведения приложения, например, если код выявил вероятные погрешности в вычислениях.
- SyntaxWarning — Предупреждение об использовании сомнительных синтаксических конструкций. Категория используется в случаях, когда замечены вероятные синтаксические ошибки.
- UnicodeWarning — Предупреждения, связанные с возможными проблемами при работе с Юникод.
- USERWARNING — Класс для пользовательских предупреждений. Может использоваться пользователями в качестве базового класса для создания собственных иерархий предупреждений.
Теперь, зная, когда и при каких обстоятельствах могут возникнуть исключения, мы можем их обрабатывать. Для обработки исключений используется конструкция try — except.
Первый пример применения этой конструкции:
В блоке try мы выполняем инструкцию, которая может породить исключение, а в блоке except мы перехватываем их. При этом перехватываются как само исключение, так и его потомки. Например, перехватывая ArithmeticError, мы также перехватываем FloatingPointError, OverflowError и ZeroDivisionError.
Также возможна инструкция except без аргументов, которая перехватывает вообще всё (и прерывание с клавиатуры, и системный выход и т. д.). Поэтому в такой форме инструкция except практически не используется, а используется except Exception. Однако чаще всего перехватывают исключения по одному, для упрощения отладки (вдруг вы ещё другую ошибку сделаете, а except её перехватит).
Ещё две инструкции, относящиеся к нашей проблеме, это finally и else. Finally выполняет блок инструкций в любом случае, было ли исключение, или нет (применима, когда нужно непременно что‑то сделать, к примеру, закрыть файл). Инструкция else выполняется в том случае, если исключения не было.
Обработка исключений в Python

Что вы предпринимаете, когда с работой вашей программы что-то идет не так? Допустим, вы пытаетесь открыть файл, но вы ввели неверный путь, или вы хотите узнать информацию у пользователей и они пишут какую-то бессмыслицу. Вы не хотите, чтобы ваша программа крэшилась, по-этому вы выполняете обработку исключений. В Пайтоне, конструкция всегда обернута в то, что называется try/except. В данном разделе мы рассмотрим следующие понятия:
- Базовые типы исключений;
- Обработка исключений при помощи try/except;
- Узнаем, как работает try/except/finally;
- Выясним, как работает оператор else совместно с try/except;
Начнем со знакомства с самыми обычными исключениями, которые вы увидите в Пайтоне. Обратите внимание на то, что ошибка и исключение – два разных слова, описывающие одно и то же, в контексте обработки исключений.
Основные исключения
Вы уже сталкивались со множеством исключений. Ниже изложен список основных встроенных исключений (определение в документации к Пайтону):
- Exception – то, на чем фактически строятся все остальные ошибки;
- AttributeError – возникает, когда ссылка атрибута или присвоение не могут быть выполнены;
- IOError – возникает в том случае, когда операция I/O (такая как оператор вывода, встроенная функция open() или метод объекта-файла) не может быть выполнена, по связанной с I/O причине: «файл не найден», или «диск заполнен», иными словами.
- ImportError – возникает, когда оператор import не может найти определение модуля, или когда оператор не может найти имя файла, который должен быть импортирован;
- IndexError – возникает, когда индекс последовательности находится вне допустимого диапазона;
- KeyError – возникает, когда ключ сопоставления (dictionary key) не найден в наборе существующих ключей;
- KeyboardInterrupt – возникает, когда пользователь нажимает клавишу прерывания(обычно Delete или Ctrl+C);
- NameError – возникает, когда локальное или глобальное имя не найдено;
- OSError – возникает, когда функция получает связанную с системой ошибку;
- SyntaxError — возникает, когда синтаксическая ошибка встречается синтаксическим анализатором;
- TypeError – возникает, когда операция или функция применяется к объекту несоответствующего типа. Связанное значение представляет собой строку, в которой приводятся подробные сведения о несоответствии типов;
- ValueError – возникает, когда встроенная операция или функция получают аргумент, тип которого правильный, но неправильно значение, и ситуация не может описано более точно, как при возникновении IndexError;
- ZeroDivisionError – возникает, когда второй аргумент операции division или modulo равен нулю;
Существует много других исключений, но вы вряд ли будете сталкиваться с ними так же часто. В целом, если вы заинтересованы, вы можете узнать больше о них в документации Пайтон.
Как обрабатывать исключения?
Обработка исключений в Пайтон – это очень просто. Потратим немного времени и напишем несколько примеров, которые их вызовут. Мы начнем с одной из самых элементарных проблем: деление на ноль.
224
11.1. Типы ошибок
Если программа, представленная компилятору, написана с ошибками, не на «исходном» языке, «недружелюбный» компилятор может просто проинформировать пользователя об этом, не указав, где произошла ошибка. Большинство пользователей не удовлетворит такой подход, поскольку они ожидают от компилятора:
1)точного указания, где находится (первая) ошибка программирования;
2)продолжения компиляции (или, по крайней мере, анализа) про-
граммы после обнаружения первой ошибки с целью обнаружения остальных.
Основные причины возникновения ошибок программирования можно классифицировать следующим образом.
Программист не совсем понимает язык, на котором он пишет, и использует неправильную конструкцию программы.
Программист недостаточно осторожен в применении конструкции языка и забывает описать идентификатор или согласовать открывающую скобку с закрывающей и т.д.
Программист неправильно пишет слово языка или какого-либо другой символ в программе.
Ошибки, обусловленные этими тремя факторами, по-разному обнаруживаются компилятором. Ошибки первого типа вылавливаются синтаксическим анализатором, и генерируется сообщение с указанием того символа, на котором поток программы стал недействительным. Ошибки второго типа распадаются на две категории. Те, которые относятся к контекстным свойствам языка (отсутствие идентификатора и д.р.), обнаруживаются процедурой выборки из таблицы символов во время синтаксического анализа. Такие ошибки, как недостающие скобки, обнаруживаются самим анализатором во время выполнения фазы одного из проходов. Ошибки третьего типа обычно выявляются во время лексического анализа.
Существуют ошибки еще одного типа, когда программа пытается выполнить деление на ноль или считывание за пределами файла. Они называются ошибками времени прогона, и обычно их нельзя обнаружить в процессе компиляции. Наша задача проанализировать методы диагностики всех видов ошибок фазы компиляции и рассмотреть -ме тоды их коррекции.
225
11.2. Лексические ошибки
Задача лексического анализатора – сгруппировать последовательность литер в символы исходного языка. При этом он работает исключительно с локальной информацией. В его распоряжении имеется небольшой объем памяти, и он не осуществляет предварительного просмотра. В тех случаях, когда лексический анализатор окажется не в состоянии сгруппировать какие-либо последовательности литер в символы (лексемы), будут возникать ошибки. Лексические ошибки можно разделить на следующие группы.
Одна из литер оказывается недействительной, т.е. она не может быть включена ни в один из символов. В таком случае лексический анализатор либо игнорирует эту литеру, либо заменяет ее какой-либо другой.
При попытке собрать выделенное слово языка выясняется, что последовательность букв не соответствует ни одному из этих .словВ этом случае можно воспользоваться алгоритмом подбора слова, чтобы идентифицировать слово, имеющее несколько другое написание. Например, realab представить как real ab.
Собирая числа, лексический анализатор может испытывать затруднения с последовательностью вида 42.34.41. Возможное решение здесь
– допустить, какая бы ошибка не была, что предполагалось одно число, и предупредить программиста, что вместо этого числа принято конкретное число по умолчанию.
Отсутствие в программе какой-либо литеры приводит к тому, что лексический анализатор не может отделить один символ от другого. Например, если в А+В пропущен знак «+», то лексический анализатор просто пропустит идентификатор АВ, не оповещая об ошибке на этой стадии. Однако отсутствие знака «+» в 1+А вызовет ошибку, хотя лексический анализатор не будет знать, к какой группе ошибок отнести 1А – к недопустимым идентификаторам или еще чему-либо.
Обычно проблему для лексического анализатора создают недостающие кавычки строки символов
string food=”BREFD
Следовательно, в остальной части программы открывающие и закрывающие кавычки могут быть перепутаны. В результате обрушится лавина сообщений об ошибках. «Смышленый» анализатор смог бы обнаружить неправдоподобную последовательность литер внутри кавычек (например, end) и исправить ошибку, поставив в нужном месте кавычки.
226
Многие компиляторы завершают свою работу тем проходом, где обнаружена ошибка. Однако современная тенденция построения компиляторов базируется на принципе обнаружения максимального числа ошибок. Таким образом желательно, чтобы компилятор продвинулся в своей работе как можно дальше. Поэтому лексический анализатор должен передать следующему проходу (фазе) последовательность действительных символов (а необязательно действительную последовательность символов). Для правильных в лексическом смысле программ это не представляет трудностей. При лексически неправильных программах приходится или игнорировать последовательность символов, или включать дополнительные. Может потребоваться изменить написание символов, разбить строки на действительные символы. Игнорировать последовательность литерсамое простое средство, но оно практически всегда приводит к возникновению синтаксических ошибок. Методы исправления лексическим анализатором недопустимых входов зависят от обстоятельств, и на практике их выбор определяется компилируемым языком.
11.3. Ошибки в употреблении скобок
Ошибки, связанные с употреблением скобок, обнаруживаются относительно легко. Обычно компиляторы содержат фазу, предшествующую полному синтаксическому анализу, на которой производится согласование скобок. Если применять скобки только одного типа, например «(» и «)», проверку можно осуществлять с помощью целочисленного счетчика. Этот счетчик первоначально устанавливается на нуль, затем увеличивается на единицу для каждой открывающей скобки и уменьшается на единицу для каждой закрывающей скобки. Последовательность скобок считается допустимой в том случае, когда:
1)счетчик ни при каких обстоятельствах не становится отрицательным;
2)при завершении работы счетчик будет на нуле.
Вбольшинстве языков программирования встречаются различные типы скобок, например
{}
|
[ |
] |
|
begin |
end |
|
if |
fi |
|
case |
esac |
В этом случае необходимо согласовывать каждую закрывающую с соответствующей открывающей скобкой. Алгоритм согласования ско-
227
бок читает скобочную структуру слева направо, помещая каждую открывающую скобку в вершину стека. Когда встречается закрывающая скобка, соответствующая открывающая скобка удаляется из стека. Последовательность скобок считается допустимой, если:
1)при чтении закрывающей скобки не окажется, что она не соответствует открывающей, помещенной в вершине стека;
2)при завершении работы стек станет пустым.
Ошибка в употреблении скобок должна отразиться в четком сообщении, типа
BRACKET MISMATCH.
Если ошибка возникла из-за того, что не достает закрывающей скобки, то тип последней можно вывести на основании той скобки, которая находится в вершине стека. Один из возможных путей исправления ошибки заключается в том, что берется предполагаемая недостающая закрывающая скобка, открывающая скобка удаляется из стека, и выдается сообщение с указанием предполагаемого источника ошибки.
Диагностическое сообщение появится, однако, не в том месте, где был допущен пропуск скобки, так как ошибка останется незамеченной до тех пор, пока не встретится другая закрывающая скобка иного типа. При продолжении синтаксического анализа желательно, чтобы скобочная структура была исправлена. Пример
if b then x else (p+q´r**2 fi.
Здесь пропущена закрывающая скобка «)». Это не обнаружится до тех пор, пока не встретиться fi. Однако неясно, где должна стоять эта скобка: после r, после q, после p или 2. Выяснить, что предполагал программист, невозможно. Поэтому самый легкий способ«исправления» — поставить закрывающую скобку непосредственно передfi. Синтаксический анализатор продолжает работать, а на выход выдается сообщение о введенных изменениях.
11.4. Синтаксические ошибки
Термин «синтаксическая ошибка» употребляется для обозначения ошибки, обнаруживаемой контекстно-свободным синтаксическим анализатором. Современные анализаторы обладают этим важным свойством – обнаруживать синтаксически неправильную программу на первом недопустимом символе, т.е. они могут генерировать сообщения при чтении символа, который не должен следовать за прочитанной к тому времени последовательностью символов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #