Условное
обозначение средней арифметической
величины через М (от латинского слова
Media) чаще применяется в медицинских и
педагогических исследованиях. В
математической статистике предпочитают
обозначение через ![]() .
.
Средняя арифметическая величина является
производной, обобщающей количественные
признаки ряда однородных показателей
(совокупности). Выражая одним числом
определенную совокупность, она как бы
ослабляет влияние случайных индивидуальных
отклонений, и акцентирует некую обобщенную
количественную характеристику, наиболее
типичное свойство изучаемого ряда
показателей.
Определяя
значение средней арифметической
величины, следует придерживаться
некоторых правил.
1.
Средняя арифметическая величина может
характеризовать только те признаки
изучаемого объекта, которые присущи
всей совокупности, но в разной
количественной мере (например, уровень
развития быстроты движений характерен
для каждого человека, хотя и в разной
количественной мере). Средняя арифметическая
величина не может характеризовать
количественную меру тех признаков,
которые одной части совокупности
присущи, а другой нет, т. е. она не может
отражать присутствие или отсутствие
того или иного признака (например, умение
или неумение выполнять то или иное
двигательное действие).
2.
Средняя арифметическая величина должна
включать все показатели, полученные в
данном исследовании. Произвольное
исключение даже некоторых из них
неизбежно приведет к искажению конечного
результата.
3.
Средняя арифметическая величина обязана
отражать только однородную совокупность.
Нельзя, например, определять средний
уровень физического развития школьников,
не разделив их предварительно по возрасту
и полу.
4.
Средняя арифметическая величина должна
вычисляться на достаточно большой
совокупности, размеры которой определяются
в каждом конкретном случае отдельно
(см. «Подбор исследуемых»).
5.
Необходимо стремиться к тому, чтобы
средняя арифметическая величина имела
четкие и простые свойства, позволяющие
легко и быстро ее вычислять.
6.
Средняя арифметическая величина должна
обладать достаточной устойчивостью к
действию случайных факторов. Только в
этом случае она будет отражать
действительное состояние изучаемого
явления, а не его случайные изменения.
7.
Точность вычисления средней арифметической
величины должна соответствовать
содержанию изучаемого педагогического
явления. В некоторых случаях нет
необходимости в расчетах с большой
точностью, в других — большая точность
нужна при вычислениях, но совершенно
не нужна в выводах. Например, при расчете
средних величин числа подтягиваний на
перекладине можно пользоваться и сотыми
долями целого, но представлять и выводах,
что исследуемые в среднем подтянулись
7,83 раза, было бы неграмотна, так как
невозможно измерение с подобной
точностью. В этом случае необходимо в
выводах представлять числа, округленные
до целых единиц.
В
простейшем случае этот показатель
вычисляется путем сложения всех
полученных значений (которые называются
вариантами) и деления суммы на число
вариант:
![]()
где
S — знак суммирования;
V
— полученные в исследовании значения
(варианты);
п
— число вариант.
По
этой формуле вычисляется так называемая
простая средняя арифметическая величина.
Применяется она в тех случаях, когда
имеется небольшое число вариант.
При
большом числе вариант прибегают к
вычислению так называемой взвешенной
средней арифметической величины. С этой
целью строят ряд распределения, или
вариационный ряд, который представляет
собой ряд вариант и их частот,
характеризующих какой-нибудь признак
в убывающем или возрастающем порядке.
Например, в нашем случае измерение
точности попадания мячом в цель дало
125 вариант, т. е. в группе I, где применялась
методика обучения «А», одноразово
исследовалось 125 детей с числовым
выражением от 0 (точное попадание в цель)
до 21,5 см (максимальное отклонение от
цели). Каждое числовое выражение
встречалось в исследовании один и более
раз, например «0» встретился 28 раз.
Другими словами, 28 участников эксперимента
точно попали в цель. Этот показатель
называется числом наблюдений или
частотой вариант и условно обозначается
буквой «Р» (число наблюдений составляет
часть числа вариант).
Для
упрощения числовых операций все 125
вариант разбиваются на классы с величиной
интервала 1,9 см. Число классов зависит
от величины колебаний вариант (разности
между максимальной и минимальной
вариантами), наличия вариант для каждого
класса (если, например, для первого
класса — «0 — 1,9» — нет соответствующих
вариант, т.е. ни один исследуемый не имел
точных попаданий или отклонений от цели
в пределах от 0 до 1,9 см, то подобный класс
не вносится в вариационный ряд) и,
наконец, требуемой точности вычисления,
(чем больше классов, тем точность
вычисления выше). Вполне понятно, что
чем больше величина интервала, тем
меньше число классов при одной и той же
величине колебаний вариант.
После
разбивки вариант по классам в каждом
классе определяется срединная варианта
«Vc»,
и для каждой срединной варианты
проставляется число наблюдений. Пример
этих операций, и дальнейший ход вычислений
приведены в следующей таблице:
|
Классы |
Серединные |
Число |
VCP |
VC-M=d |
d2 |
d2P |
|
0 |
1 |
28 |
28 |
-4.6 |
21.16 |
592.48 |
|
2 |
3 |
29 |
87 |
-2.6 |
6.76 |
196.04 |
|
4 |
5 |
22 |
110 |
-0.6 |
0.36 |
7.92 |
|
6 |
7 |
13 |
91 |
1.4 |
1.96 |
25.48 |
|
8 |
9 |
11 |
99 |
3.4 |
11.56 |
127.16 |
|
10 |
11 |
13 |
143 |
5.4 |
29.16 |
379.08 |
|
12 |
13 |
4 |
52 |
7.4 |
54.76 |
219.04 |
|
14 |
15 |
2 |
30 |
9.4 |
88.36 |
176.72 |
|
16 |
17 |
1 |
17 |
11.4 |
130.00 |
130.00 |
|
18 |
19 |
1 |
19 |
13.4 |
179.60 |
179.60 |
|
20 |
21 |
1 |
21 |
15.4 |
237.20 |
237.20 |
|
125 |
697 |
2270.72 |
Очередность
числовых операций:
1)
вычислить сумму числа наблюдений (в
нашем примере она равна 125);
2)
вычислить произведение каждой срединной
варианты на ее частоту (например, 1*28 =
28);
3)
вычислить сумму произведений срединных
вариант на их частоты (в нашем примере
она равна 697);
4)
вычислить взвешенную среднюю арифметическую
величину по формуле:
![]()
Средняя
арифметическая величина позволяет
сравнивать и оценивать группы изучаемых
явлений в целом. Однако для характеристики
группы явлений только этой величины
явно недостаточно, так как размер
колебаний вариант, из которых она
складывается, может быть различным.
Поэтому в характеристику группы явлений
необходимо ввести такой показатель,
который давал бы представление о величине
колебаний вариант около их средней
величины.
Вычисление
средней ошибки среднего арифметического.
Условное обозначение средней ошибки
среднего арифметического — т. Следует
помнить, что под «ошибкой» в статистике
понимается не ошибка исследования, а
мера представительства данной величины,
т. е. мера, которой средняя арифметическая
величина, полученная на выборочной
совокупности (в нашем примере — на 125
детях), отличается от истинной средней
арифметической величины, которая была
бы получена на генеральной совокупности
(в нашем примере это были бы все дети
аналогичного возраста, уровня
подготовленности и т. д.). Например, в
приведенном ранее примере определялась
точность попадания малым мячом в цель
у 125 детей и была получена средняя
арифметическая величина примерно равная
5,6 см. Теперь надо установить, в какой
мере эта величина будет характерна,
если взять для исследования 200, 300, 500 и
больше аналогичных детей. Ответ на этот
вопрос и даст вычисление средней ошибки
среднего арифметического, которое
производится по формуле:
![]()
Для
приведенного примера величина средней
ошибки среднего арифметического будет
равна:
![]()
Следовательно,
M±m = 5,6±0,38. Это означает, что полученная
средняя арифметическая величина (M =
5,6) может иметь в других аналогичных
исследованиях значения от 5,22 (5,6 — 0,38 =
5,22) до 5,98 (5,6+0,38 = 5,98).
Соседние файлы в предмете Ветеринарная генетика
- #
- #
- #
Вычисление среднего арифметического отклонения заболеваемости (летальности, иммунизации)
Страницы работы
Содержание работы
Лабораторное
занятие №7
Тема:
Вычисление среднего арифметического отклонения заболеваемости (летальности,
иммунизации)
Цель
– научиться изучать величину средней арифметической и ее ошибки.
Задачи:
1. Изучить
основные обозначения.
2. Построить
основную и вспомогательную таблицы.
3. Вычислить
величину средней арифметической.
4. Вычислить
величину ошибки средней арифметической.
Вариационная статистика – наука, разрабатывающая изучение метода варьирующего
признака на массовых материалах в различных областях знания. Варьирующими
признаками принято называть такие, которые проявляют определенную
закономерность в изменчивости значений.
В качестве варьирующих могут быть такие показатели развития эпизоотического
процесса, как количество неблагополучных пунктов, коэффициент очаговости,
заболеваемость, летальность, уровень вакцинации животных и так далее. Взятые за
ряд лет по годам и связанные в определенные таблицы.
При переработки показателей эпизоотического процесса, для вычисления средней
арифметической, среднего квадратического отклонения, ошибки средней
арифметической, критерия средней арифметической, критерия достоверности и
вероятности, варьирующие величины обозначаются специальными терминами,
символами, принятыми в вариационной статистике.
Основные
обозначения:
V(X)
– величина варьирующего признака (показатель);
n
– число варьирующих признаков (показателей, участвующих в обработке);
Σ
(большая греческая сигма) – общепринятое обозначение арифметического
действия (суммы);
![]() (
(![]() ) – среднее арифметическое
) – среднее арифметическое
варьирующих признаков (показателей участвующих в обработке);
![]() (S) – сигма малая, показатель среднего
(S) – сигма малая, показатель среднего
квадратического отклонения;
m (Sx) – искомая
ошибка средней арифметической;
n-1=V – число
степеней свободы; (ню)
t – критерий
достоверности (существенности);
P –уровень
вероятности (существенности);
r – коэффициент
парной корреляции;
R – коэффициент
множественной корреляции;
Таблица
28.
Заболеваемость
лептоспирозом крупного рогатого скота в России
в
2001-2010 гг. (количество заболевших животных на 10 тысяч поголовья)
|
Край |
Годы |
Средний показатель за 10 лет M±m |
p |
|||||||||
|
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
2009 |
2010 |
|||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|||
|
Хабаровский |
3,41 |
4,89 |
4,49 |
5,54 |
3,61 |
1,80 |
1,83 |
1,08 |
1,24 |
0,80 |
2,87±0,58 |
<0,001 |
|
Красноярский |
3,44 |
2,0 |
2,63 |
3,33 |
1,83 |
1,19 |
0,91 |
0,43 |
0,36 |
0,28 |
1,69±0,41 |
<0,001 |
|
Краснодарский |
4,33 |
3,58 |
5,95 |
1,91 |
1,03 |
0,32 |
0,28 |
0,51 |
0,12 |
0,64 |
1,86±0,68 |
<0,001 |
Таблица
29.
Разброс
вариационного ряда по заболеваемости крупного рогатого скота лептоспирозом по
Хабаровскому краю
|
n |
V |
V-M |
(V-M)² |
|
1 |
3.41 |
0.54 |
0.29 |
|
2 |
4.89 |
2.02 |
4.08 |
|
3 |
4.49 |
1.62 |
2.62 |
|
4 |
5.54 |
2.67 |
7.13 |
|
5 |
3.61 |
0.74 |
0.55 |
|
6 |
1.80 |
-1.07 |
1.14 |
|
7 |
1.83 |
-1.04 |
1.08 |
|
8 |
1.08 |
-1.79 |
3.20 |
|
9 |
1.24 |
-1.63 |
2.66 |
|
10 |
0.8 |
-2.07 |
4.28 |
|
n=10 |
Σv=28.69 M=2.87 |
Σ(V-M)²=27.05 |
Из приведенного примера видно, что число показателей (n)
равно 10. Следовательно, число вариантов (показателей заболеваемости, анализ за
2001-2010 гг.) также равно 10.
Вычисление средней арифметической (М)
Средняя арифметическая определяется путем деления суммы (ΣV)
вариантов на число вариантов, участвующих в обработке (п) по формуле:
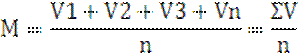
На нашем примере общая сумма вариантов (показателей) ΣV
равна
28,69 откуда средняя арифметическая составит:
М=![]()
Вычисление
среднего квадратического отклонения:
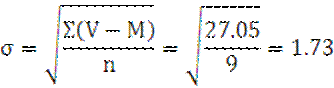
m=±![]()
М±m=2.87±0.58
Таблица
30.
Разброс
вариационного ряда по заболеваемости крупного рогатого скота лептоспирозом в
Красноярском крае
|
№ |
V |
V-M |
(V-M)² |
|
1 |
3,44 |
1,80 |
3,24 |
|
2 |
2,00 |
0,36 |
0,13 |
|
3 |
2,63 |
0,99 |
0,98 |
|
4 |
3,33 |
1,69 |
2,86 |
|
5 |
1,87 |
0,19 |
0,04 |
|
6 |
1,19 |
-0,45 |
0,20 |
|
7 |
0,91 |
-0,73 |
0,53 |
|
8 |
0,43 |
-1,21 |
1,46 |
|
9 |
0,36 |
-1,28 |
1,64 |
|
10 |
0,28 |
-1,36 |
1,85 |
|
n=10 |
Σv M=1,64 |
Σ(V-M)²=12,93 |
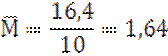
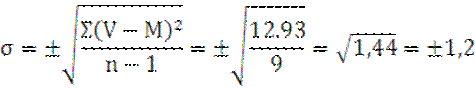
m=±![]()
M±m=1.64
± 0.4
Таблица
31.
Разброс
вариационного ряда по заболеваемости крупного рогатого скота лептоспирозом в
Краснодарском крае
|
№ |
V |
V-M |
(V-M)² |
|
1 |
4,33 |
2,46 |
6,05 |
|
2 |
3,58 |
1,71 |
2,92 |
|
3 |
5,95 |
4,08 |
16,65 |
|
4 |
1,91 |
0,04 |
0,01 |
|
5 |
1,03 |
-0,84 |
0,70 |
|
6 |
0,32 |
-1,55 |
2,40 |
|
7 |
0,28 |
-1,59 |
2,53 |
|
8 |
0,51 |
1,36 |
1,85 |
|
9 |
0,12 |
1,75 |
3,06 |
|
10 |
0,64 |
1,23 |
1,51 |
|
n=10 |
Σv=18,67 M=1,87 |
Σ(V-M)²=37,68 |
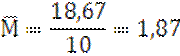
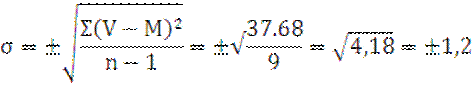
m=±![]()
M±m=1,87
± 0.68
Вычисление
ошибки средней арифметической (М)
При
малом числе показателей, участвующих в обработке (п<30) ошибку средней
арифметической определяют по формуле:
M=±
![]() а при 30 m
а при 30 m
= ± ![]()
В
нашем примере: m= ±![]()
Среднюю
арифметическую принято записывать с ее ошибкой:M±m
Ошибка
средней арифметической дает возможность:
1.
Определить
в каких пределах находится средняя величина. Выборочные статистические величины
правильно отражают свойства генеральной совокупности, если ошибка (m)
укладывается в своей средней (М) не менее двух раз.
2.
Выяснить
степень достоверности между двумя сравниваемыми выборочными средними.
Таким образом, в нашем примере средняя арифметическая М=2,87, ошибка средней
арифметической m=±0,58. Средний
показатель за 10 лет при этих данных будет М±m
=
2.87±0.58 (по Хабаровскому краю). Средний показатель заболеваемости крупного
рогатого скота лептоспирозом в Красноярском крае M±m
=
1.64±0.40, Красноярском крае M±m
= 1.64±0.68.
Контрольные
вопросы:
1.
Основные
обозначения величин.
2.
Что
означает средняя арифметическая величина и ее формула.
3.
Вычислить
среднюю арифметическую величину.
4.
Что
означает ошибка средней арифметической, ее формула.
5.
Вычислить
ошибку средней арифметической на конкретном примере.
Похожие материалы
- Сезонность лептоспироза свиней. Сезонность лептоспироза свиней в Хабаровском краев
- Чума плотоядных в г. Благовещенске по данным ветеринарной клиники ИП Чубин
- Определение удельного веса инфекционного заболевания
Информация о работе
Тип:
Отчеты по лабораторным работам
Вариационная статистика (от лат. variatio — изменение) — раздел математической статистики, изучает распределение варьирующих количеств, признаков в совокупностях объектов (исследуемых группах). Показатель изучаемого признака изменяется (варьирует) от объекта к объекту (например, количество эритроцитов в крови животных одного вида, пола и возраста). Точность результатов статистического измерения зависит от числа наблюдений. Методы вариационной статистики применяются для обработки количественно выраженных данных в пределах качественно однородных групп и позволяют оценить изменчивость (варьирование) исследуемых величин, исключить случайное и по ограниченной выборке оценить параметры генеральной совокупности. Вариационная статистика также позволяет измерять взаимную связь (корреляционную зависимость) двух и более признаков одной совокупности (например, зависимость между ростом и массой тела) и решать другие задачи.
Методы расчета относительных величин. Абсолютные величины отражают количественную сторону действительности, абсолютные размеры изучаемого явления. Абсолютные величины используются при характеристике общей совокупности (численность населения, общее число врачей в стране и др.), а также при оценке редко встречающихся явлений (число особо опасных инфекций, число людей с аномалиями развития). Абсолютные величины, как правило, не используют для статистического анализа, поскольку они мало пригодны для сравнения. Для сравнения изучаемых явлений используют производные величины, которые подразделяются на относительные и средние величины. Относительные величины используются при анализе альтернативных (есть явление или отсутствует) признаков.
В биологической статистике используют следующие виды относительных величин: экстенсивные коэффициенты; интенсивные коэффициенты; коэффициенты соотношения; коэффициенты наглядности.
Экстенсивные коэффициенты характеризуют отношение части к целому, то есть определяют долю (удельный вес), процент части в целом, принятом за 100%. Используются для характеристики структуры статистической совокупности (табл. 4). Например: удельный вес (доля) животных с определенной окраской среди всех животных этого вида в процентах; (отношение числа серебристо-голубых норок к общему числу норок на звероферме, умноженное на 100%).
Таблица 4.
Распределение норок выращенных на звероферме по окраске
| Тип норок | Количество животных | Доля от общего количества (%) |
| Коричневые | 120 | 24 |
| Серебристо-голубые | 160 | 32 |
| Сапфировые | 180 | 36 |
| Черные скандинавские | 40 | 8 |
| Всего | 500 | 100 |
Интенсивные коэффициенты отражают частоту (уровень, распространенность) явления в однородной среде. На практике их применяют для оценки заболеваемости, медико-демографических процессов. Например: число случаев заболеваний 100 работающих; число заболевших гипертонической болезнью на 1000 жителей; число родившихся на 1000 человек (определяется как отношение числа родившихся за год к средней численности населения административной территории, умноженное на 1000). Вычисление интенсивного показателя производится по формуле:

Основание – единица с нулями: 100, 1000, 10000, 100000. В результате полученные данные выражаются в процентах (%), промилле (‰), продецимилле (%00), просантимилле (%000)
Коэффициенты соотношения (показатель частоты, распространенности явления в разнородных средах) характеризуют численное соотношение двух не связанных между собой, самостоятельных совокупностей. Методика расчета показателей соотношения сходна с методикой вычисления интенсивных показателей, хотя они различны по существу.

Показатели соотношения используются для характеристики уровня и качества обеспеченности медицинской помощью: число коек на 10000 человек; число врачей на 10000 жителей; число лекарственных препаратов, произведенных на 1000 жителей (отношение числа выпущенных лекарственных препаратов, к численности населения административной территории, умноженное на 1000).
Показатель наглядности применяется с целью более наглядного и доступного сравнения рядов абсолютных, относительных и средних величин. Коэффициент наглядности определяет, на сколько процентов или во сколько раз произошло увеличение или уменьшение сравниваемых величин. Используется для характеристики динамики явления. При вычислении показателей наглядности одна из сравниваемых величин принимается за 100% или за единицу, а остальные величины с помощью пропорции пересчитываются в коэффициенты по отношению к этому числу. Чаще всего за 100% принимается первая исходная величина, но за 100 может быть принята величина и из середины, конца ряда.
Методы расчета средних величин
Оценить размер признака, изменяющегося по своей величине в совокупности, позволяет лишь его обобщающая характеристика, называемая средней величиной. В биологических исследованиях широко используются средние величины, которые рассчитывают из рядов распределения или вариационных рядов. Вариационным рядом называют двойной ряд чисел, показывающий, каким образом числовые значения признака связаны с их повторяемостью в данной статистической совокупности. Вариационные ряды бывают следующих видов:
а) ранжированный, не ранжированный;
б) сгруппированный, не сгруппированный;
в) прерывный, непрерывный.
Ранжированный ряд — упорядоченный ряд; варианты располагаются последовательно по нарастанию или убыванию числовых значений.
Не ранжированный ряд — варианты располагаются бессистемно.
Прерывный (дискретный) ряд — варианты выражены в виде целых (дискретных) чисел (окна в избе).
Непрерывный ряд – варианты могут быть выражены дробными числами.
Не сгруппированный ряд (безинтервальный) – каждому значению варианты соответствует определенное число частот. Такой вариационный ряд целесообразно строить в тех случаях, когда разница между минимальным и максимальным значением вариантов невелика, особенно если признак варьирует дискретно.
Сгруппированный ряд (интервальный) – варианты соединены в группы, объединяющие их по величине в пределах определенного интервала.
В вариационном ряду количественное выражение изучаемого признака называется вариантой или (у некоторых авторов) датой и изображается буквой V. Последовательность построения вариационного ряда рассмотрим на примере данных о количестве ягнят у овец романовской породы. Результаты исследования оказались следующие: 3, 1,5, 4, 2, 4, 6, 1, 3, 3, 5, 6, 2, 2, 4, 5, 6, 7, 4, 3, 5, 2, 3, 4, 5, 6, 7, 5, 4, 8, 3, 5, .5
Чтобы составить вариационный ряд, найдем и отметим максимальную и минимальную варианты. В нашем примере минимальная варианта Vmin — 1, максимальная Vmax — 8. Разность между минимальной и максимальной вариантами называется размахом варьирования или амплитудой изменчивости.
Для составления вариационного ряда расположим варианты в восходящем порядке и определим, сколько раз каждая варианта встречается в нашей выборке.
Число, показывающее, сколько раз встречается в данной выборке каждая варианта, называется частотой и изображается буквой p. Сумма частот равна количеству взятых для исследования объектов (наблюдений).
| Число ягнят (V) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Частота встречаемости признака (p) | 2 | 4 | 6 | 6 | 8 | 4 | 2 | 1 |
Полученный вариационный ряд полностью соответствует требованиям, предъявляемым к группировке данных, поскольку первоначальный материал стал более «обозримым», и в результате простейших преобразований мы сделали явной ранее завуалированную информацию. В частности, хорошо видно, что большая часть значений признака сгруппирована в середине ряда, тогда как крайние значения вариант встречаются относительно редко.
Если же изучаемый признак непрерывен (таковы размерно-весовые характеристики), то для построения вариационного ряда сначала весь диапазон изменчивости признака разбивается на серию равных интервалов (классов вариант), затем подсчитывают, сколько вариант попало в каждый интервал. Число классов для больших выборок (n > 100) должно быть не менее 7 и не более 12, их оптимальное число можно приблизительно определить по эмпирической формуле:
k = 1 + 3.32 lg(n), где п – объем выборки (число вариант в выборке).
Составим для примера вариационный ряд для непрерывного признака – по данным о весе 63 взрослых землероек (г):
| 9.2 | 11.6 | 8.1 | 9.1 | 10.1 | 9.6 | 9.3 | 9.7 | 9.9 | 9.9 | 9.6 |
| 7.6 | 10.0 | 9.7 | 8.4 | 8.6 | 9.0 | 8.8 | 8.6 | 9.3 | 11.9 | 9.3 |
| 9.2 | 10.2 | 11.2 | 8.1 | 10.3 | 9.2 | 9.8 | 9.9 | 9.3 | 9.1 | 9.4 |
| 9.6 | 7.3 | 8.3 | 8.8 | 9.2 | 8.0 | 8.6 | 8.8 | 9.0 | 9.5 | 9.1 |
| 8.5 | 8.8 | 9.7 | 11.5 | 10.5 | 9.8 | 10.0 | 9.4 | 8.7 | 10.0 | 7.9 |
| 8.6 | 8.7 | 9.1 | 8.2 | 9.2 | 9.4 | 8.8 | 9.8 |
1) Все операции могут быть выполнены вручную. Вначале следует определить объем выборки n = 63.
2) Рассчитать пределы размаха изменчивости значений, лимит – разность между максимальным и минимальным значением:
Lim = Vmax−Vmin = 11.9−7.3 = 4.6.
3) Найти число классов вариационного ряда по формуле:
k = 1+3.32×lg(63) = 6.973811 ≈ 7.
Желательное число классов вариационного ряда можно определить по количеству наблюдений исходя из таблицы 5.
Таблица 5
Число классов вариационного ряда в зависимости от числа наблюдений
| Количество наблюдений | Число классов |
| 25 — 40 | 5 — 6 |
| 40 – 60 | 6 — 8 |
| 60 — 100 | 7- 10 |
| 100 — 200 | 8- 12 |
| Более 200 | 10 — 15 |
4) Найти длину интервала dx (допустимо округление):
dx = Lim/k = 4.6/7 ≈ 0.7.
5) Установить границы классов; в качестве первой границы имеет смысл взять округленное минимальное значение: Vmin = 7.
6) Вычислить центральное значение признака в каждом классе; исходным берется значение центра первого интервала; для первого класса 7–7.7, для второго – 7.8–8.4…
7) Произвести разноску вариант в соответствующие классы с подсчетом их числа методом конверта (табл. 2):
1 2 3 4 5 6 7 8 9 10.
![]()
Теперь полученные данные можно занести в таблицу (табл.6), а также представить графически, в виде полигона частот (ломаной кривой) или гистограммы (столбиками).
Таблица 6
Методика составления интервального вариационного ряд по данным о весе взрослых землероек (г)
| Классы | Центр классового интервала, (V) | Подсчет
частот |
Частоты, (p) |
| 7–7.7 | 7.35 |  |
2 |
| 7.8–8.4 | 8.05 |  |
7 |
| 8.5–9.1 | 8.75 |  |
18 |
| 9.2–9.8 | 9.45 |  |
22 |
| 9.9–10.5 | 10.15 |  |
10 |
| 10.6–11.2 | 10.85 |  |
1 |
| 11.3–11.9 | 11.55 |  |
3 |
| Сумма | 63 |
Одной из важнейших обобщающих характеристик вариационного ряда является средняя величина признака (обычно обозначается буквой М или Х). Существует несколько видов средних (средняя арифметическая – простая и взвешенная, средняя гармоническая, средняя квадратичная), но в практике биологических исследований наибольшее значение имеет средняя арифметическая – величина, вокруг которой «концентрируются» варианты.
В число прочих констант вариационного ряда входит медиана (Me) – значение, делящее размах выборки пополам, и мода (Mo) – класс (или значение), представленный наибольшим числом вариант. В вариационном ряду это варианта, имеющая наибольшую частоту встречаемости. Обычно мода является величиной, довольно близкой к средней арифметической, совпадает с ней при полной симметрии распределения. Медиана – варианта, делящая вариационный ряд на две равные половины. При нечетном числе наблюдений медианой является варианта, имеющая в вариационном ряду порядковый номер (n + 1): 2. Средняя арифметическая величина (М) в отличие от моды и медианы опирается на все произведенные наблюдения, поэтому является важной характеристикой для всего распределения.
В зависимости от вида вариационного ряда используется тот или иной способ расчета средней. Средняя арифметическая для простого ряда, где каждая варианта встречается один раз, вычисляется по формуле: М =  , где
, где  — знак суммы, V –отдельные значения вариант, n –число наблюдений. Средняя арифметическая взвешенная определяется по формуле: М=
— знак суммы, V –отдельные значения вариант, n –число наблюдений. Средняя арифметическая взвешенная определяется по формуле: М=  , где — знак суммы, V –отдельные значения вариант, n – число наблюдений (т.е. сумма всех частот, n=Σ p), р – частота встречаемости вариант. Пусть получены результаты определения средней величины выводка у рыжих полевок (экз./ самку) по месяцам: май 5.0, июнь 5.4, июль 6.2, август 6.0, сентябрь 4.5, причем известно число определений (самок) для каждого месяца: 22, 43, 103, 33 и 5. Взвешенная средняя арифметическая составит:
, где — знак суммы, V –отдельные значения вариант, n – число наблюдений (т.е. сумма всех частот, n=Σ p), р – частота встречаемости вариант. Пусть получены результаты определения средней величины выводка у рыжих полевок (экз./ самку) по месяцам: май 5.0, июнь 5.4, июль 6.2, август 6.0, сентябрь 4.5, причем известно число определений (самок) для каждого месяца: 22, 43, 103, 33 и 5. Взвешенная средняя арифметическая составит:
M = (5∙22 + 5.4∙43 + 6.2∙103 + 6∙33 + 4.5∙5) / (22 + 43 + 103 + 33 + 5) = 5.8.
Одним из наиболее простых и достаточно точных способов расчета средней арифметической является способ моментов, основанный на том, что алгебраическая сумма отклонений каждой варианты вариационного ряда от средней арифметической равна нулю. М= А + i , где А – условно принятая средняя или мода, а — отклонение каждой варианты от условно принятой средней, р – частота встречаемости вариант, n –число наблюдений, i – интервал или расстояние между соседними вариантами.
, где А – условно принятая средняя или мода, а — отклонение каждой варианты от условно принятой средней, р – частота встречаемости вариант, n –число наблюдений, i – интервал или расстояние между соседними вариантами.
Методика расчета средней величины по способу моментов
| Число ягнят (V) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Частота встречаемости признака (p) | 2 | 4 | 6 | 6 | 8 | 4 | 2 | 1 | Σ р = n =33 |
| а | — 4 | — 3 | — 2 | — 1 | 0 | +1 | +2 | +3 | |
| ар | — 8 | -12 | -12 | -6 | 0 | +4 | +4 | +3 | Σар=-27 |
| а2р | 32 | 36 | 24 | 6 | 0 | 4 | 8 | 9 | Σа2р=119 |
Этапы расчета средней арифметической по способу моментов:
- За условно принятую среднюю (или моду) А принимают варианту, чаще других повторяющуюся в вариационном ряду, например А = Мо = 5.
- Определяем а – условное отклонение от условной средней; для этого из каждой варианты вычитаем условную среднюю а = (V – А).
- Умножаем условное отклонение (а) на частоту (р) каждой варианты и получаем произведение (а×р).
- Получаем сумму Σ а×р = -27
- Определяем интервал между группами вариант i =1
- Определяем момент первой степени

- Рассчитываем среднюю арифметическую по способу моментов
М= А + i
Таким образом, можно сделать вывод, что в среднем у овец романовской породы рождается 4,2 ягненка.
Основные свойства средней величины: 1) имеет абстрактный характер, так как является обобщающей величиной: в ней стираются случайные колебания; 2) занимает срединное положение в строго симметричном ряду; 3) сумма отклонений всех вариант от средней величины равна нулю. Данное свойство средней величины используется для проверки правильности расчета средней. Она оценивается по уровню колеблемости вариационного ряда. Критериями такой оценки могут служить: амплитуда (разница между крайними вариантами); среднее квадратическое отклонение, показывающее, как отличаются варианты от рассчитанной средней величины; коэффициент вариации.
Среднеквадратическое отклонение ( ) наиболее точно характеризует степень разнообразия варьирующего признака, без чего нельзя достаточно полно охарактеризовать явление. Для простого вариационного ряда (р = 1) среднеквадратическое отклонение рассчитывается по формуле
) наиболее точно характеризует степень разнообразия варьирующего признака, без чего нельзя достаточно полно охарактеризовать явление. Для простого вариационного ряда (р = 1) среднеквадратическое отклонение рассчитывается по формуле  . Для взвешенного вариационного ряда по формуле:
. Для взвешенного вариационного ряда по формуле:  , где d = V – M — отклонение каждой варианты от средней арифметической. При числе наблюдений меньше 30 в знаменателе этих формул берется не n, а n – 1 (так называемое в статистике число степеней свободы). При числе наблюдений более 30 уменьшение знаменателя на единицу не имеет практического значения, т.к. существенно не сказывается на конечном результате. Значительно упрощает вычисления расчет среднего квадратического отклонения по способу моментов.
, где d = V – M — отклонение каждой варианты от средней арифметической. При числе наблюдений меньше 30 в знаменателе этих формул берется не n, а n – 1 (так называемое в статистике число степеней свободы). При числе наблюдений более 30 уменьшение знаменателя на единицу не имеет практического значения, т.к. существенно не сказывается на конечном результате. Значительно упрощает вычисления расчет среднего квадратического отклонения по способу моментов.  где, величина
где, величина  называется моментом первой степени, а
называется моментом первой степени, а  — моментом второй степени.
— моментом второй степени.
Для нашего примера среднеквадратическое отклонение равно:

Степень разнообразия (колеблемости) признака в вариационном ряду можно оценить по коэффициенту вариации, который является относительной мерой разнообразия признака, так как исчисляется как процентное отношение среднего квадратического отклонения к средней величине.
Сυ =  =
=  %
%
При вариации менее 10% отмечается слабое разнообразие, при вариации 10—20% — среднее, а при вариации более 20% — сильное разнообразие признака.
Коэффициент вариации находит применение и в селекционной работе. Например, при сравнении двух сходных по продуктивности и качественным показателям сортов предпочтение должно быть отдано тому из них, который при равных условиях обладает меньшей изменчивостью.
Из теории статистики и эмпирических исследований известно, что выборка, репрезентативно отражающая генеральную совокупность, как правило, обладает следующими свойствами:
Указанная закономерность, получившая название нормального распределения, является одной из ключевых в вариационной статистике и её следует запомнить. Термин “нормальное распределение” введен в биологическую лексику Гальтоном в 1889 году. Однако ещё задолго до этого оно было хорошо известно математикам, которые это распределение часто называют законом Гаусса – Лапласа. Как видно из рисунка 1, нормальное распределение или распределение Гаусса — Лапласа графически может быть отображено симметричной колоколообразной кривой, вершиной которой является свойственная генеральной совокупности средняя величина. При нормальном типе распределения число случаев наблюдений с различной величиной признака располагается симметрично по отношению к середине ряда: от меньшего значения признака к большему его значению. При этом наибольшее число случаев наблюдений приходится на середину ряда.
Распределение вариантов в конкретной выборке далеко не всегда полностью совпадает с нормальным. Наиболее типичными несоответствиями являются: асимметрия, то есть смещение вершины распределения относительно среднего значения, и эксцесс — выраженная плоско — или островершинность распределения [Лакин,1990 и др.]. При ассиметричном распределении наибольшее число случаев наблюдений скапливается не на уровне середины ряда, а сдвигается в сторону меньшего значения признака (правосторонняя асимметрия) или в сторону большего значения признака (левосторонняя асимметрия), или же скапливается по концам ряда (двугорбое бимодальное распределение). Правосторонняя асимметрия характерна, например, для распределения такого признака, как число детей в семье. Как известно, в большинстве семей имеется 1-2детей. С увеличением числа детей в семьях соответственно уменьшается число семей. Однако в большинстве случаев всё же можно использовать тесты, основанные на предположении о нормальности распределения. Дело в том, что при возрастании объёма выборки форма выборочного распределения средней арифметической приближается к нормальной. Отсюда следует, что для статистического анализа всегда предпочтительнее иметь многочисленную выборку (n>30).

Рис.1. Диаграмма нормального распределения.
В биологии и медицине с величиной М ± 1σ связано понятие нормы; отклонения от средней (в любую сторону) больше, чем на 1σ, но меньше чем на 2σ, считаются субнормальными (выше или ниже нормы), а при отклонении от средней больше, чем на 2σ, варианты считаются значительно отличающимися от нормы (патология).
Наконец, среднее квадратическое отклонение является важным компонентом при расчете средней ошибки средней арифметической (ошибки репрезентативности), которая является мерой точности и достоверности результатов выборочных статистических величин. Средняя ошибка средней арифметической – m (отношение среднего квадратического отклонения к квадратному корню из общего числа наблюдений — объектов). Статистические ошибки присущи только выборочным характеристикам, возникая в процессе отбора вариант из генеральной совокупности. Ошибка является именованной величиной и выражается в единицах измерения основного параметра. Ошибку средней находят по формулам:
m = ±  — для большой выборки, а для малой выборки, где (n<30) средняя ошибка средней арифметической — m = ±
— для большой выборки, а для малой выборки, где (n<30) средняя ошибка средней арифметической — m = ±  , так как чем меньше выборка, тем больше ошибка. Полученный результат записывается как М ± m, это означает, что средняя генеральной совокупности находится в пределах от М — m до М + m.
, так как чем меньше выборка, тем больше ошибка. Полученный результат записывается как М ± m, это означает, что средняя генеральной совокупности находится в пределах от М — m до М + m.
Совершенно очевидно, что наилучшим методом для повышения точности исследования является увеличение объёма наблюдений. Иными словами, ошибка статистического параметра, вычисленного по данным выборки, будет тем меньше, чем больше число наблюдений, составляющих эту выборку.
Мерой достоверности среднего показателя наряду с его ошибкой являются доверительные границы и достоверность разности между двумя средними величинами.