1. Основные положения
В основе планирования деятельности
любого предприятия лежит прогнозирование
продаж. Так, в сфере финансов и бухгалтерии
прогнозы являются основой бюджетного
планирования и контроля затрат. Маркетинг
опирается на прогнозирование продаж
при планировании новых видов продукции
и формировании рекламной политики.
Производственные менеджеры на основе
прогноза продаж составляют графики
выполнения производственных операций,
определяют необходимый уровень запасов,
планируют производственные мощности
и размещение оборудования.
Прогнозирование продаж базируется на
оценке спроса. В большинстве случаев
спрос на продукцию можно разбить на
шесть компонентов: средний спрос за
определенный период, тренд, сезонные
колебания, циклические колебания,
случайные выбросы и автокорреляция.
Среднее значение спроса отражает
центральную тенденцию распределений
его значений вокруг какого-то центра.
Если центральная тенденция ярко выражена,
тогда значение центра можно рассматривать
как наиболее типичное для анализируемого
спроса.
Под трендом понимается долгосрочная
составляющая, характеризующая общую
тенденцию изменения спроса в течение
длительного периода времени. Под
тенденцией понимается возрастание или
убывание спроса. Факторами, порождающими
тренд, могут быть, например, изменение
состава населения, инфляция, технологические
изменения, рост цен и др.
Сезонная компонента характеризует
изменения спроса, которые регулярно
повторяются и завершаются в пределах
года. При анализе спроса ее легко
определить, поскольку она характеризуется
всплеском объема продаж. Сезонность
спроса определяется такими факторами,
как, например, погода для сельского
хозяйства, праздничные дни для предприятий
торговли и др.
Циклическая компонента характеризует
повторяющиеся и волнообразные изменения
спроса длительностью более года. Она
отражает цикл деловой активности,
периоды подъема и спада. Циклические
колебания определить сложно, так как
цикл может быть неизвестен или причину
цикла установить невозможно. К основным
факторам, влияющим на циклические
колебания спроса, относятся политические,
экономические, демографические,
социальные и др.
Случайная компонента отражает
быстрые изменения, как правило, малой
длительности. Случайные изменения
спроса вызваны редкими и непредсказуемыми
событиями, такими как природные
катаклизмы, войны, эпидемии и др. Их
можно выявить путем удаления из общего
спроса все остальные компоненты.
Оставшуюся составляющую, если невозможно
выяснить ее причину, относят к случайным
факторам. Случайный спрос с течением
времени может варьировать в широких
пределах.
Автокорреляция отражает свойство
инерционности показателей спроса. Это
означает, что его значения в момент
времени t определенным
образом зависят от его значений в прошлые
периоды. При большой автокорреляции
изменение спроса во времени происходит
незначительно.
В зависимости от периода прогнозирования
выделяют краткосрочное (до трех месяцев),
среднесрочное (от трех месяцев до двух
лет) и долгосрочное прогнозирование
(свыше двух лет). Краткосрочные прогнозы
усредняют случайные изменения и
регулируют краткосрочные колебания.
Среднесрочные прогнозы применяются
при наличии сезонных колебаний, а
долгосрочные прогнозы устанавливают
общие тренды
В наиболее общем виде все методы
прогнозирования можно разделить на две
группы: качественные (основанные на
субъективных оценках и мнениях) и
количественные (основанные на анализе
статистических данных за прошлые
периоды).
Эти методы, хотя и отличаются друг от
друга, тем не менее, в их основе лежат
одинаковые принципы и допущения:
1) большинство методов основано на
анализе данных прошлых периодов;
2) прогнозы редко бывают абсолютно
точными;
3) точность прогноза снижается по мере
увеличения периода прогнозирования;
4) прогнозы для отрасли более точны, чем
для отдельных предприятий.
При выборе модели прогнозирования
необходимо учитывать следующие факторы:
-
горизонт планирования;
-
исходные данные;
-
требуемая точность;
-
бюджет, выделенный для прогноза;
-
уровень квалификации персонала.
Качественные методы прогнозирования
Качественные (экспертные) методы
прогнозирования спроса хорошо подходят
для выработки краткосрочных прогнозов.
К наиболее известным качественным
методам прогнозирования относятся:
мнение специалистов, голосование
торговых агентов, метод Делфи и изучение
покупателей.
Мнение специалистов
Данный метод предполагает составление
прогнозов относительно будущих продаж
на основе усреднения мнений работников
или экспертов подразделений предприятия.
Обычно этот подход используется совместно
с каким-нибудь количественным методом.
Преимуществом данного метода
прогнозирования является быстрая,
простая оценка без расчета статистических
показателей. В случае отсутствия
необходимой для анализа информации
этот метод может оказаться единственным
подходящим способом прогнозирования.
Недостаток метода связан с так называемым
групповым мышлением, когда вырабатывается
согласованная точка зрения. В этом
случае устраняются разногласия,
подавляется мнение служащих нижнего
уровня, происходит изоляция группы от
внешних мнений.
Голосование торговых агентов
В некоторых компаниях для составления
прогнозов привлекаются торговые агенты,
имеющие непосредственный контакт с
покупателями. Результаты, полученные
при голосовании торговых агентов, могут
усредняться и либо использоваться в
качестве прогнозов, либо корректировать
прогнозы, полученные с помощью других
количественных или качественных методов.
К преимуществам данного метода относятся:
1) простота в понимании и использовании;
2) основывается на специальных знаниях
специалистов, близких к практике;
3) позволяет классифицировать информацию
применительно к региону, товару,
покупателю и торговому агенту.
К недостаткам данного метода относится
то, что торговый агент может быть излишне
оптимистичен или, напротив, пессимистичен
относительно ожидаемых продаж.
Метод Делфи
Во избежание недостатков группового
мышления метод Делфи использует опрос
экспертов в индивидуальном порядке,
при этом обеспечивается конфиденциальность
участвующих в исследовании лиц, что
позволяет устранить давление вышестоящего
руководства на специалистов более
низкого уровня. После проведения первого
опроса мнение экспертов анализируется
и обобщается. В случае возникновения
разногласий обобщенная информация и
вопросы вновь направляются к экспертам
для уточнения. Процесс повторяется до
тех пор, пока не выработается единодушное
мнение.
Метод хорошо работает для составления
долгосрочных прогнозов. К главным
недостаткам метода Делфи относятся
низкая надежность и отсутствие
согласованности в общем решении.
Изучение покупателей
Изучение покупателей может проводиться
как самой компанией, так и с привлечением
специализирующихся на исследовании
рынка организаций. Изучение проводится
с применением телефонных контактов,
персонального интервьюирования и
анкетирования. В дальнейшем с помощью
расширенного статистического анализа
результаты опросов обобщаются и
проверяются гипотезы о поведении
покупателей.
Количественные методы прогнозирования
Количественные методы прогнозирования
основаны на анализе временных рядов и
на оценке причинно-следственных связей
спроса и внешних факторов, влияющих на
него.
Под временным рядом (или динамическим
рядом) понимается ряд значений некоторого
показателя, взятых по состоянию на
определенные моменты или периоды
времени. Модели временных рядов
прогнозируют будущее, исходя из прошлых
данных.
Причинное прогнозирование предполагает,
что спрос связан с некоторыми
основополагающими факторами внешней
среды. Такими факторами, влияющими на
спрос, могут быть цена, процентная
ставка, доходы населения и др.
Простое скользящее среднее
Если спрос на изделие стабильный, не
носит сезонного характера и имеет лишь
случайные флуктуации, то для прогноза
можно использовать метод скользящего
среднего. Скользящие средние центрируют
и усредняют значения временного ряда
за небольшой интервал времени, поэтому
этот метод наиболее удобен для предсказания
на короткий период времени.
Формула для вычисления простого
скользящего среднего:
![]()
(1)
где Ft
– прогноз на будущий период;
At-1
– фактические значения в прошлом
периоде;
At-2,
At-3,
At—n
– фактические значения два периода
назад, три периода назад и т.д. до п
периодов назад;
п – интервал (число периодов)
усреднения.
Одним из недостатков метода простого
скользящего среднего является
необходимость статистического учета
и хранения всех прошлых данных. При
ограниченной номенклатуре товаров и
интервале усреднения от трех до шести
периодов это не очень существенно, но
для большой номенклатуры товаров и
значительном интервале усреднения
потребуется значительное количество
данных.
Взвешенное скользящее среднее
При определении простого скользящего
среднего все данные, как прошлых периодов,
так и текущие, имеют одинаковый вес.
Хотя для целей прогнозирования более
важными являются текущие данные, поэтому
для учета значимости текущих данных им
необходимо присваивать больший вес.
Метод взвешенного скользящего среднего
позволяет присваивать любой произвольный
вес каждому элементу базы данных, при
условии, что сумма всех весов равна 1.
Формула для вычисления взвешенного
скользящего среднего:
![]()
(2)
где w1 –
значение веса, присвоенное истекшему
периоду (t — 1)
w2 –
значение веса, присвоенное периоду (t
— 2)
wn
– значение веса, присвоенное периоду
(t — n)
n – общее число
периодов в прогнозе.
Схема присвоения веса может любой,
например, некоторые периоды можно
игнорировать (их вес принять равным
нулю), обычно весовые коэффициенты
устанавливают методом проб и ошибок.
Как правило, близкое прошлое служит
наиболее важным индикатором будущего,
а значит, этому периоду времени присваивают
более высокий вес. Однако если данные
имеют сезонные колебания, то их следует
учитывать при установлении весовых
коэффициентов, т.е. при составлении
прогноза на период сезонного пика
наибольший вес необходимо присваивать
прошлым данным аналогичного периода.
Преимущество метода взвешенного
скользящего среднего перед простым
заключается в возможности влияния на
прогноз, изменяя результаты прошлых
периодов.
Экспоненциальное сглаживание
Главным недостатком методов прогнозирования
на основе простого и взвешенного
скользящего среднего является
необходимость использования большого
количества прошлых данных. Если считать,
что значимость данных уменьшается с
течением времени, то наиболее подходящим
методом усиления влияния последних
периодов является экспоненциальное
сглаживание.
Для прогнозирования будущего методом
экспоненциального сглаживания необходимы
только три вида данных: данные последнего
прогноза, текущий спрос и константа
сглаживания α. Эта константа
определяет уровень сглаживания и
скорость реакции на разницу между
прогнозами и текущими событиями. Выбор
значения константы зависит от стабильности
спроса и от скорости его изменения. Если
спрос стабилен, то α может быть равна
от 5 до 10%. В случае увеличения спроса α
должна иметь более высокое значение,
чтобы придать большую значимость
текущему росту. Чем выше темп роста, тем
выше должна быть скорость реагирования.
Уравнение для однократного экспоненциального
сглаживания имеет следующий вид:
![]()
(3)
где Ft
– экспоненциально сглаженный прогноз
на период t;
Ft-1
– экспоненциально сглаженный прогноз,
сделанный для предшествующего периода;
At-1
– фактический спрос в предшествующем
периоде;
α – константа
сглаживания.
Метод экспоненциального сглаживания
чаще всего используется для прогнозирования.
Недостатком метода экспоненциального
сглаживания является лаговый эффект.
Прогноз запаздывает в периоды роста
или падения спроса и превышает фактические
значения при его уменьшении.
Экспоненциальное сглаживание с трендовым
регулированием
Для преодоления лагового эффекта при
применении метода экспоненциального
сглаживания при росте или падении спроса
экспоненциально сглаженные прогнозы
можно откорректировать введением
тренда. Для этого необходимы две константы
сглаживания. Помимо константы сглаживания
α, в уравнении тренда используют
константу сглаживания тренда δ,
которая уменьшает влияние ошибки, т.е.
разности между действительным значением
и прогнозируемым.
Экспоненциальное сглаживание с трендовым
регулированием производится по следующим
формулам:
![]()
(4)
![]()
(5)
![]()
(6)
где FITt
– прогноз, включающий тренд в периоде
t;
Ft
– экспоненциально сглаженный прогноз
на период t;
Tt
– экспоненциально сглаженный тренд
на период t;
FITt-1
– прогноз, включающий тренд предыдущего
периода;
At-1
– фактический спрос в предыдущем
периоде;
α – константа
сглаживания прогноза;
δ – константа
сглаживания тренда.
К недостаткам метода экспоненциального
сглаживания с регулируемым трендом
относится то, что он не учитывает сезонные
колебания спроса.
Трендовое проектирование
В основе трендового проектирования
лежит линейный регрессионный анализ.
Регрессия представляет собой функциональную
зависимость между двумя или несколькими
коррелированными переменными. Ее
используют для предсказания значения
одной переменной на основе значения
другой. Взаимосвязь обычно устанавливают
на основе наблюдаемых данных. Вначале
по этим полезно построить график, чтобы
посмотреть, является ли эта зависимость
линейной или нет.
Линейную регрессию используют для
прогнозирования, как в моделях временных
рядов, так и в причинных моделях. Когда
зависимая переменная изменяется в
зависимости от времени, имеют дело с
анализом временных рядов. Данная модель
называется трендовым проектированием.
Для трендового проектирования уравнение
регрессии имеет следующий вид:
![]()
(7)
где t – период времени.
Для данного уравнения коэффициенты
регрессии а и b
можно найти методом наименьших квадратов
по формулам:
![]()
(8)
![]()
(9)
где a – отрезок,
отсекаемый на координатной оси Y;
b – величина
наклона прямой;
‾y – среднее всех
значений y;
‾x – среднее
значение всех t;
t – значение t
для каждой точки данных (текущее
значение);
y – значение y
для каждой точки данных (текущее
значение);
n – число точек данных;
Y – значение
зависимой переменной, вычисляемое по
уравнению регрессии.
Главным ограничением модели трендового
проектирования является то, что заранее
допускают, что значения данных на прошлых
и будущих интервалах попадают на прямую
линию. Такое допущение в целом ограничивает
его применение. К нему часто прибегают
при исследованиях на небольших интервалах
времени. Однако продолжительный период
можно представить в виде суммы коротких
отрезков времени, в которых наблюдается
относительная линейность, что позволяет
обойти это ограничение.
Декомпозиция (разложение) временных
рядов
Декомпозиция временного ряда означает
идентификацию и разделение данных
временного ряда на компоненты спроса.
На практике относительно несложно
идентифицировать тренд и сезонные
колебания, значительно сложнее
идентифицировать циклы, автокорреляцию
и случайные компоненты.
Когда в спросе одновременно присутствуют
сезонные и трендовые компоненты, то для
построения качественного прогноза
спроса их необходимо разделить.
Для выделения сезонных колебаний
применяют термин сезонный индекс.
Сезонный индекс – это корректирующий
коэффициент, который необходимо ввести
во временной ряд для учета колебаний
спроса по сезонам года. Он определяется
по формуле:
![]()
(10)
Прогнозирование спроса с учетом сезонных
индексов можно производить двумя
способами: с помощью простого расчета,
основанного на данных прошлого года, и
с использованием тренда.
Прогнозирование спроса на основе данных
прошлого года производится по следующей
схеме:
-
годовой объем продаж разделяется на
число сезонов; -
определяется средний уровень продаж
за каждый сезон прошлого года; -
определяются сезонные индексы по
формуле (3.11); -
определяется средний уровень продаж
за каждый сезон в прогнозируемом году; -
определяется сезонный прогноз на
следующий год с учетом сезонных индексов.
Сезонные индексы могут периодически
обновляться по мере получения новой
информации.
Прогнозирование спроса с учетом сезонных
индексов на основе тренда производится
следующим образом:
1. Разложение временного ряда на
компоненты:
а) определение сезонного компонента;
б) устранение сезонного влияния на
спрос;
в) определение трендовой компоненты.
2. Составление прогноза будущих значений
по каждому компоненту:
а) распространение трендовой компоненты
на будущие периоды;
б) умножение трендовой компоненты на
сезонный.
Каузальное (причинное) прогнозирование
Если какое-то событие влечет за собой
какие-то последствия, то такие связи
называются причинными. Однако, иногда
встречаются взаимосвязи, воспринимаемые
как причинные, но в действительности
ими не являющиеся. Поэтому первым этапом
прогнозирования на основе причинных
связей является определение событий,
которые действительно вызывают
последствия.
Каузальное (причинное) прогнозирование
производится с помощью линейного
регрессионного анализа. В качестве
независимых переменных могут выступать
один или несколько факторов. В случае,
когда независимая переменная определяется
в зависимости от одного фактора, то
строится однофакторное уравнение
регрессии, если определяется ее
зависимость от нескольких факторов, то
– уравнение множественной регрессии.
График линейной регрессии выражается
уравнением
![]()
(11)
где Y – значение
зависимой переменной, относительно
которой решается уравнение;
a – отрезок,
отсекаемый на координатной оси Y;
b – угол наклона
прямой;
X – независимая
переменная.
В ходе процесса прогнозирования неизбежно
возникают ошибки прогноза. Под ошибкой
прогноза понимают расхождение между
прогнозом и действительностью. Хотя в
прогнозировании считается, что, до тех
пор, пока значение прогноза находится
в доверительных границах, эти расхождения
не являются ошибкой.
Ошибки прогноза могут возникать по
разным причинам и иметь различные
источники. Их можно разделить на
систематические, возникающие из-за
погрешности измерения, и случайные. К
источникам систематических ошибок
относятся недостаточное количество
прямых переменных, использование
некорректной зависимости между
переменными, применение неверной
трендовой линии, ошибочный сдвиг
сезонного спроса и наличие необнаруженного
тренда во временных рядах. К случайным
ошибкам относятся те ошибки, которые
нельзя объяснить используемой моделью
прогноза.
Измерение ошибок прогноза производится
с помощью таких показателей, как среднее
абсолютное отклонение, среднеквадратическое
отклонение, средняя абсолютная
относительная ошибка и средняя
относительная ошибка.
Среднее абсолютное отклонение (МАD)
представляет собой среднее значение
ошибки в прогнозе, которое измеряет
разброс прогнозируемых значений от
ожидаемых. МАD вычисляют
как разность между действительным и
прогнозируемым спросом без учета знака,
по следующей формуле:

(12)
где t – номер периода;
А – текущий спрос данного периода;
F – прогнозируемый
спрос данного периода;
n – общее количество
периодов.
Определение среднеквадратического
отклонения (MSE) также
основано на вычислении отклонений от
средней арифметической, однако при ее
вычислении используют не абсолютные
величины, а квадраты величин отклонений.
Она определяется по формуле:
![]()
(13)
Показатель MSE позволяет
выявить отдельные большие отклонения
от фактических данных. На основе MSE
можно отобрать такие способы
прогнозирования, которые стабильно
дают приемлемые средние ошибки, и отсеять
такие способы, которые характеризуются,
как правило, малыми ошибками, но
допускающие иногда очень большую
погрешность.
Средняя абсолютная относительная ошибка
(МАРЕ) применяется в том случае, если
для определения показателя общей ошибки
удобнее использовать не абсолютные, а
относительные величины.
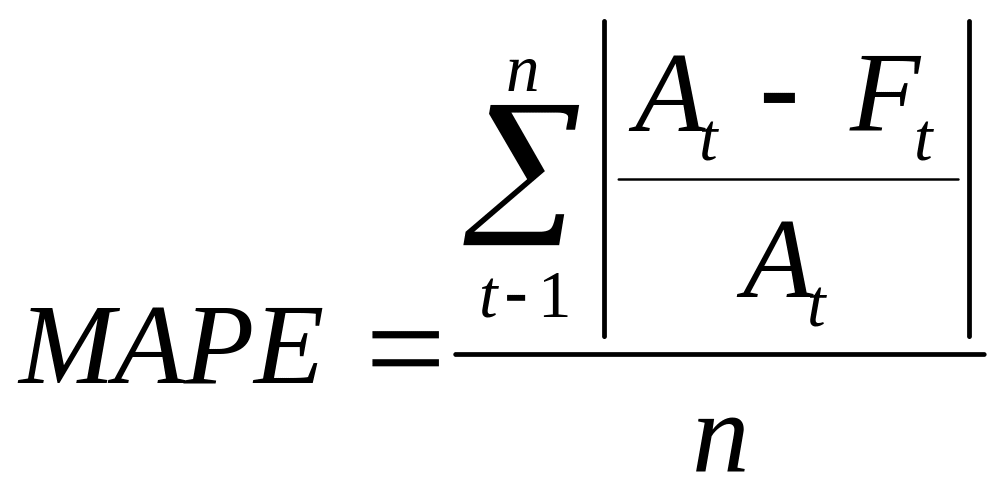
(14)
В случае, когда требуется оценить,
насколько смещенными (т.е. завышенными
или заниженными) являются результаты
прогнозирования, то можно использовать
показатель средней относительной ошибки
МРЕ.
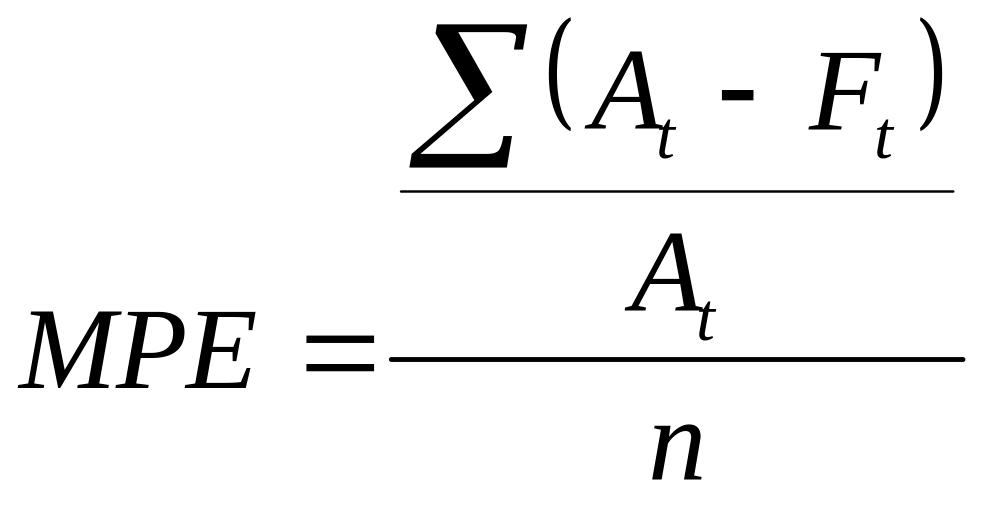
(15)
Если показатель МРЕ близок к нулю,
то смещения нет. Если он отрицательный,
то имеет место завышение прогнозных
оценок; если положительный, то оценки
будут заниженными.
При сравнении двух и более методов
прогнозирования, чем меньше рассмотренные
выше показатели, тем более точный
прогноз.
Выбор метода прогнозирования зависит
от временных и затратных факторов. При
нехватке времени и средств целесообразно
использовать простые и дешевые методы
прогнозирования, такие как модели на
основе скользящих средних или
экспоненциальное сглаживание. Для
проверки надежности какого-либо метода
прогнозирования можно использовать
разные методы измерения ошибок прогноза.
 Рост точности прогноза — это точка роста оборотных средств при неизменном объеме. Чем меньше ошибка прогноза, тем меньше денег необходимо на обслуживание модели прогноза.
Рост точности прогноза — это точка роста оборотных средств при неизменном объеме. Чем меньше ошибка прогноза, тем меньше денег необходимо на обслуживание модели прогноза.
Дополнительные оборотные средства за счет повышения точности прогноза мы получим, если будем использовать модель прогнозирования, которая дает наименьшую среднюю абсолютную ошибку прогноза.
В данной статье мы рассмотрим:
- Как рассчитать среднюю абсолютную ошибку прогноза и выбрать модель, которая дает наименьшую ошибку;
- Сравним модели и оценим, сколько оборотных средств мы можем сохранить за год, если будем использовать модель, которая дает минимальную ошибку прогноза.
По ходу статьи мы разберем
- Что такое ошибка прогноза;
- Как рассчитывается среднее абсолютное отклонение;
и рассчитаем:
- Прогноз с помощью модели «Скользящей средней к 4-м месяцам с аддитивной сезонностью»;
- Прогноз с помощью модели «Логарифмический тренд с сезонностью»;
- Ошибку прогноза для каждой модели;
- Среднее абсолютное отклонение и для каждой модели.
А также сравним модели, опираясь на среднее абсолютное отклонение и оценим экономию оборотных средств за счет использования более точной модели прогнозирования.
Скачайте файл с примером
Что такое ошибка прогноза?
Ошибкой прогноза продаж является разность между фактическими продажами и прогнозом продаж.
Чем меньше ошибка прогноза, тем более точные решения мы приминаем в закупках, производстве, планировании … а следовательно более эффективно распределяем оборотные средства и повышаем оборачиваемость товаров.
Существует несколько методов оценки ошибок. Большинство этих методов состоит в усреднении некоторых функций от разностей между действительными значениями и их прогнозами.
Ошибку прогноза (et) для каждого момента времени во временном ряду мы можем вычистить по формуле:
et = Yt — Y^t ,
где
- Yt — действительное значение временного ряда в момент t — в наших примерах объем продаж,
- Y^t — прогноз значения Yt — в наших примерах прогноз объема продаж.
Ошибка MAD — среднее абсолютное отклонение
Среднее абсолютное отклонение (MAD) измеряет точность прогноза, усредняя величины ошибок прогноза (абсолютные значения каждой ошибки). Чаще всего MAD используют, когда ошибку прогноза необходимо измерить в тех же единицах, что и исходные значения временного ряда.
Формула вычисления ошибки:
![]()
- Yt — действительное значение временного ряда в момент t,
- Y^t — прогноз значения Yt,
- n — номера периодов
Среднее абсолютное отклонение — средняя ошибка (разность между фактом продаж и прогнозом продаж) по модулю.
Рассчитаем прогноз и оценим следующие модели:
- Скользящей средней к 4-м месяцам с аддитивной сезонностью;
- Логарифмический тренд с сезонностью.
Скачайте файл с примером
Для оценки ошибки модели «Скользящей средней к 4-м месяцам с аддитивной сезонностью» рассчитаем:
- Скользящую среднюю к 4-м месяцам;
- Разность между значениями ряда и средними значениями к 4-м месяцам (пункт 1);
- Усредним разность ряда и средней для каждого месяца получим сезонность в абсолютной величание — аддитивную сезонность;
- Продлим значения ряда с помощью скользящей средней к 4-м месяцам и скорректируем её аддитивной сезонностью;
- Модель прогноза для каждого момента времени t;
- Ошибку прогноза;
- Среднее абсолютное отклонение.
1. Скользящую среднюю к 4-м месяцам для каждого момента времени во временном ряду начиная с 5-го периода:

2. Разность между значениями ряда и средними значениями к 4-м месяцам для каждого момента времени t (пункт 1):
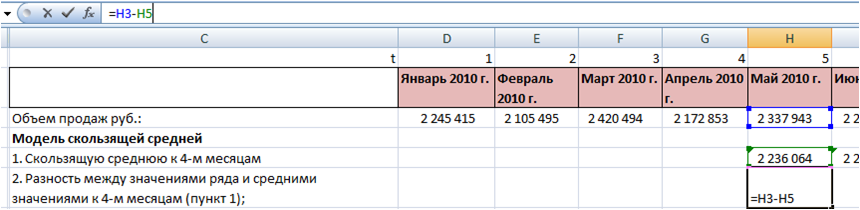
3. Усредним разность ряда и средней для каждого месяца получим сезонность в абсолютной величание — аддитивную сезонность.
Для этого вначале выделим номера месяцев с помощью функции Excel =месяц(дата). Для этого проверяем являются ли наши даты «январь 2010 г.», датой, если нет, то переводим в дату и используя функцию Excel =месяц(дата), получаем номера месяцев:
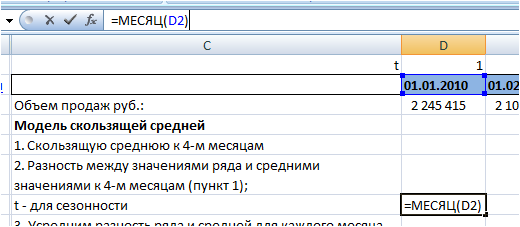
Получаем ряд с пронумерованными месяцами:

Далее усредняем отклонения ряда от средней для каждого месяца, получаем 12 значений аддитивной сезонности.
Для этого используем формулы Excel:
СУММЕСЛИ($D$7:$AY$7 (диапазон с номерами месяцев);D7 (номер месяца, для которого мы рассчитываем сезонность);$D$6:$AY$6 (разность между рядом и средней))
СЧЁТЕСЛИ($D$7:$AY$7(диапазон с номерами месяцев);D7(номер месяца, для которого мы рассчитываем сезонность))
Обязательно фиксируем ссылки на диапазоны с «Номерами месяцев» и «разность между рядом и средней». Подробнее об этом в статье » Как зафиксировать ссылку в Excel»
Подробнее о формулах Excel СУММЕСЛИ и СЧЁТЕСЛИ читайте с статье «Формулы Excel «СУММЕСЛИ» и «СЧЕТЕСЛИ» при расчете сезонности»
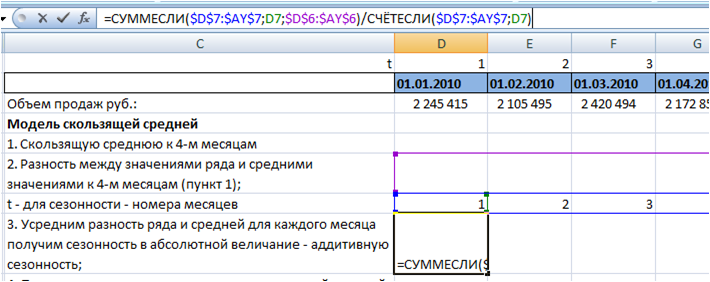
Протянули формулу на 12 месяцев, получили аддитивную сезонность для каждого месяца:

4. Продлим значения ряда с помощью скользящей средней к 4-м месяцам и скорректируем её аддитивной сезонностью.

Скорректируем скользящую рассчитанной аддитивной сезонностью.
Для этого к прогнозному среднему прибавим аддитивную сезонность. Сезонность для каждого месяца подтянем с помощью функции Excel ГПР.
Подробнее об этом читайте с статье «ГПР в Excel на примере скользящей средней».
Прогноз = средние продажи за последние 4 месяца + сезонность:
=СРЗНАЧ(AV4:AY4(средние продажи за 4 последних месяца))+ГПР(AZ3 (искомый номер месяца);$D$8:$O$9 (зафиксированная ссылка на таблицу с сезонностью);2 (номер строки);0)
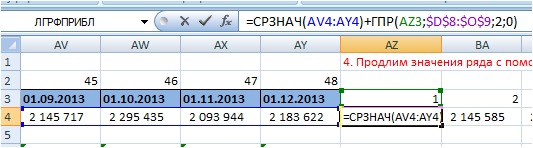
5. Рассчитаем модель прогноза для каждого момента времени t.
К скользящей средней прибавим аддитивную сезонность начиная с 5 периода:
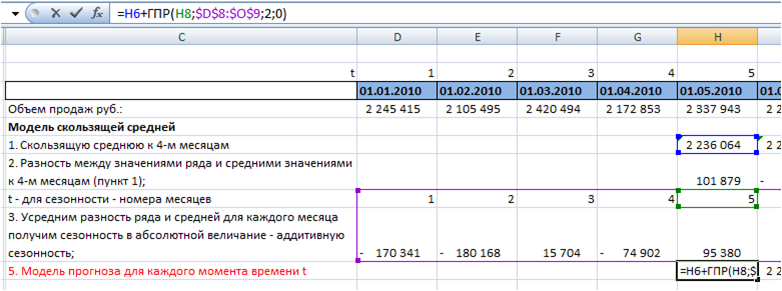
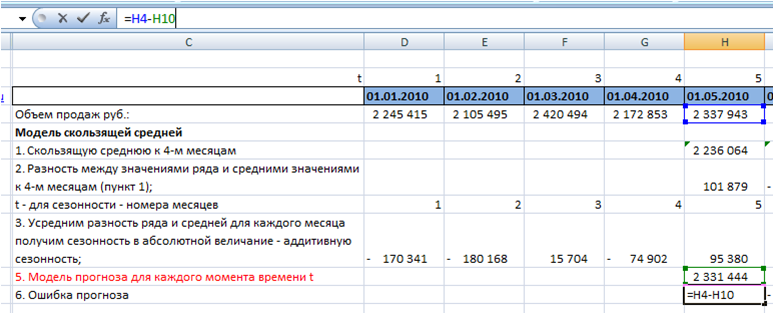
6. Рассчитаем значение ошибки для каждого месяца.
Для этого из объема продаж вычтем значение прогнозной модели:
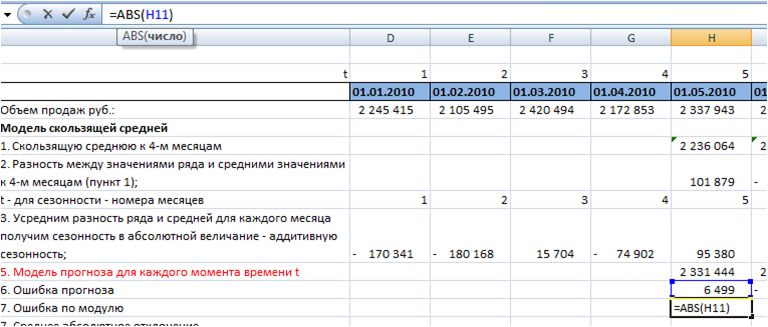
7. Определим среднее абсолютное отклонение.
Для каждого момента времени t рассчитаем ошибку по модулю с помощью формулы Excel =ABS(H11 (ссылка на ошибку)):
Среднее абсолютное отклонение равно средней ошибке по модулю:
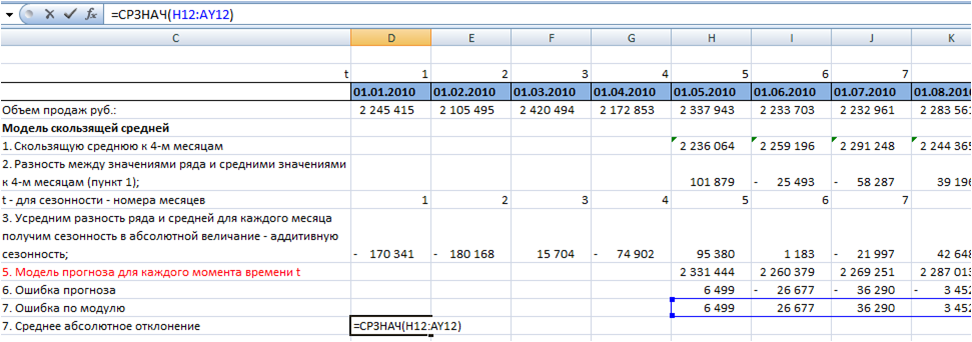
Среднее абсолютное отклонение для модели скользящей средней к 4-м месяцам с аддитивной сезонностью у нас равно 55 475
Теперь рассчитаем прогноз с помощью «Логарифмического тренда с сезонностью».
- Выделим логарифмический тренд;
- Рассчитаем сезонность;
- Рассчитаем значение модели;
- Рассчитаем ошибку прогноза и Среднее абсолютное отклонение.
Скачайте файл с примером
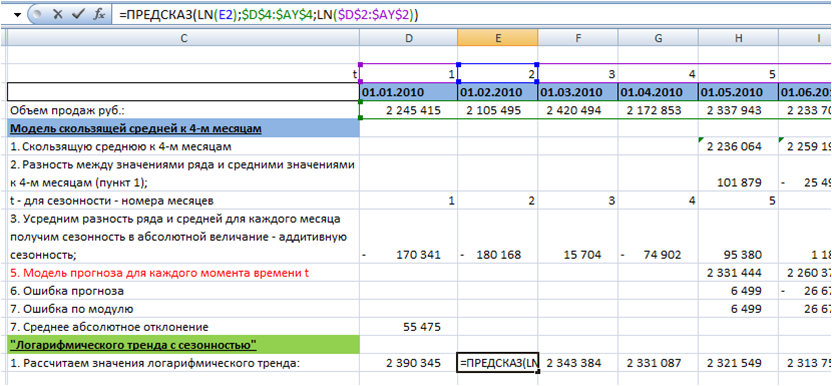
1. Выделим логарифмический тренд.
О всех возможных способах выделения логарифмического тренда в Excel вы можете узнать в нашей статье «5 способов расчета логарифмического тренда в Excel. + О логарифмическом тренде и его применении».
Рассчитаем значения тренда с помощью функции =ПРЕДСКАЗ(LN(D2(номер периода));$D$4:$AY$4 (зафиксированная ссылка на диапазон с объемами продаж);LN($D$2:$AY$2 (зафиксированная ссылка на диапазон с номерами периодов)))
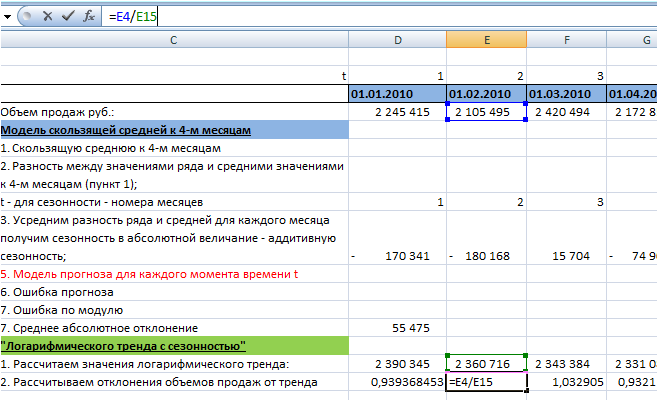
2. Рассчитываем отклонения объемов продаж от тренда (объем продаж делим на значения тренда):
3. Определяем сезонность с помощью формул Excel =СУММЕСЛИ() и =СЧЁТЕСЛИ()
Подробнее о формулах Excel СУММЕСЛИ и СЧЁТЕСЛИ читайте с статье «Формулы Excel «СУММЕСЛИ» и «СЧЕТЕСЛИ» при расчете сезонности»:
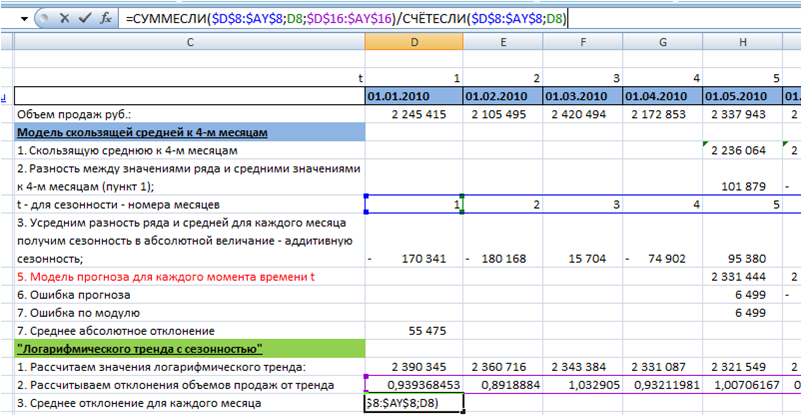
Т.к. полученная сезонность в среднем равна 1, то нормирующий коэффициент вводить не нужно, и среднее отклонение у нас будет равно сезонности по месяцам.
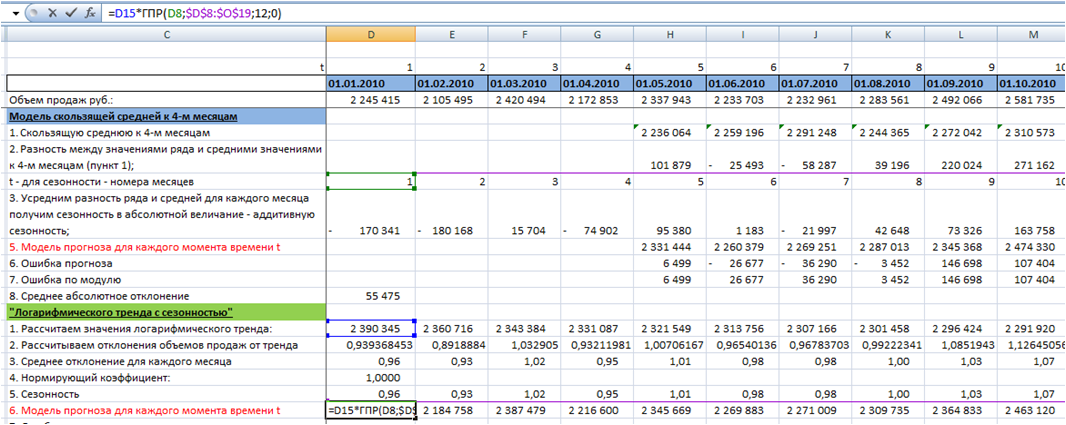
4. Определим значения модели прогноза для каждого момента времени t, для этого значения тренда умножим на сезонность. Сезонность подтянем с помощью функции ГПР (см. статью «Функция ГПР в Excel»):
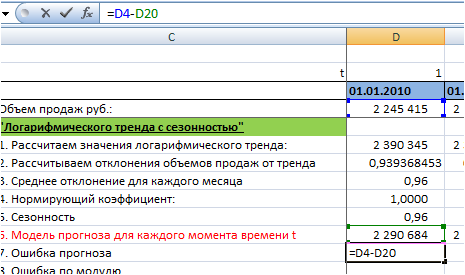
5. Определим ошибку прогноза для каждого момента времени t. Для этого из объема продаж вычтем значение модели прогноза для каждого момента времени t:
6. Рассчитаем ошибку по модулю с помощью функции =ABS(D21″ссылка на ошибку»):
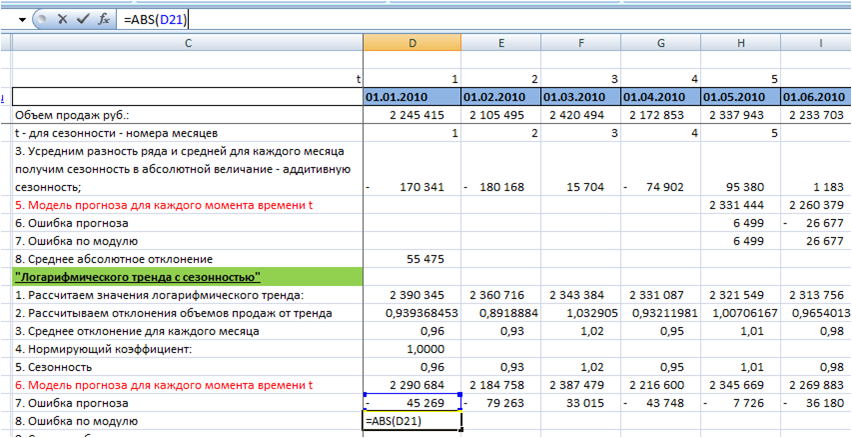
7. Получим среднее абсолютное отклонение по модулю — среднее значение ошибки по модулю:
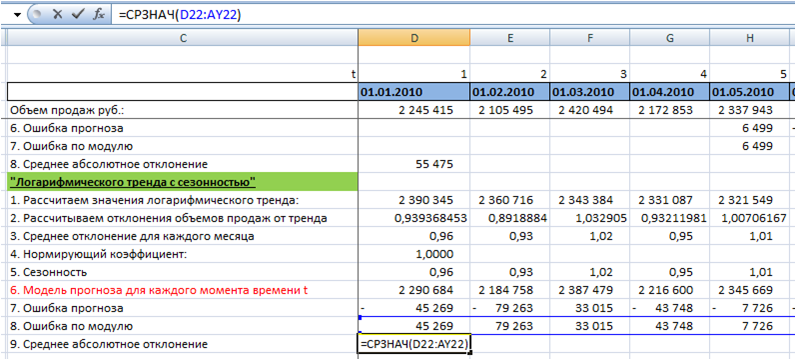
Среднее абсолютное отклонение для модели «Логарифмического тренда с сезонностью» у нас равно 70 412
Оценим эффективность использования в рамках года одной модели относительно другой.
Среднее абсолютное отклонение для модели
- «Логарифмического тренда с сезонностью» = 70 412 руб.
- «Скользящей средней к 4-м месяцам с аддитивной сезонностью» = 55 475 руб.
Итак модель скользящей средней делает более точный прогноз по сравнение с логарифмическим трендом для этого ряда в месяц на 14 937 руб. = 70 412 руб. — 55 475 руб.
В результате для нас это означает экономию оборотных средств на 14 937 руб. в месяц на обслуживание модели и 179 242 руб. в год, т.е. 14 937 руб. в месяц = 14 937 руб. * 12 месяцев =179 242 руб.
Т.е. в год мы получаем дополнительные оборотные средства в размере 179 242 руб.
Вот так вот за счет оценки точности прогноза и использования модели, которая дает меньшую ошибку прогноза, вы получаете дополнительные оборотные средства — 179 242 руб. в год.
Скачайте файл с примером
Коллеги, эти 2 модели я выбрал наугад, давайте теперь оценим модель, которую автоматически подберет Forecast4AC PRO. И оценим, какой эффект в год нам это даст.
В настройках программы во вкладке «Доп. возможности» ставим галочку «MAD — Среднее абсолютное отклонение» и отключаем модели экспоненциального сглаживания (т.к. они дают ошибку для данного ряда больше чем скользящая средняя и трендовые модели):
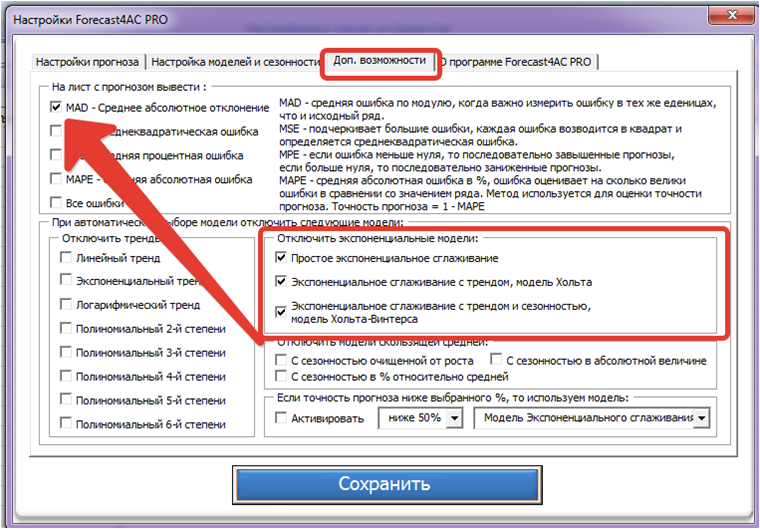
Сохраняем и рассчитываем прогноз с помощью Forecast4AC PRO с автоматическим выбором модели.
Автоматически программа выбрала модель Средняя за 2 предыдущих периода + Сезонность относительно средней в абсолютной величине (т.е. аддитивная сезонность). Среднее абсолютное отклонение для этой модели у нас получилось равным 39 882 руб.
|
Экономия оборотных средств модели Forecast4AC PRO относительно модели скользящей к 4-м месяцам в год руб.: |
187 115 руб. |
|
Экономия оборотных средств модели Forecast4AC PRO относительно модели Логарифмический тренд с сезонностью в год руб.: |
366 357 руб. |
Оцените точность моделей прогнозирования, которые вы используете сейчас, рассчитайте проноз с помощью Forecast4AC PRO и оцените сумму оборотных средств, которую вы можете сэкономить за счет использования нашей программы.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Прогнозирование и планирование
1 2 3 4 5 6 7 8 9 10 11
 По учету прогнозного фона различают прогнозы:
По учету прогнозного фона различают прогнозы:
Некоторые ответы приведены ниже. Для гарантированной сдачи тестов можете заказать у нас полное прохождение тестов.
| Номер вопроса: | 2 | 5 | 6 |
| Ответ: | 1 | 3 | 1 |
Заказать прохождение тестов
Важным этапом прогнозирования
социально-экономических явлений
является оценка точности и надежности
прогнозов.
Эмпирической мерой точности прогноза,
служит величина его ошибки, которая
определяется как разность между
прогнозными (![]() )
)
и фактическими (уt)
значениями исследуемого показателя.
Данный подход возможен только в двух
случаях:
а) период упреждения известен, уже
закончился и исследователь располагает
необходимыми фактическими значениями
прогнозируемого показателя;
б) строится ретроспективный прогноз,
то есть рассчитываются прогнозные
значения показателя для периода времени
за который уже имеются фактические
значения. Это делается с целью проверки
разработанной методики прогнозирования.
В данном случае вся имеющаяся информация
делится на две части в соотношении 2/3
к 1/3. Одна часть информации (первые 2/3
от исходного временного ряда) служит
для оценивания параметров модели
прогноза. Вторая часть информации
(последняя 1/3 части исходного ряда)
служит для реализации оценок прогноза.
Полученные, таким образом, ретроспективно
ошибки прогноза в некоторой степени
характеризуют точность предлагаемой
и реализуемой методики прогнозирования.
Однако величина ошибки ретроспективного
прогноза не может в полной мере и
окончательно характеризовать используемый
метод прогнозирования, так как она
рассчитана только для 2/3 имеющихся
данных, а не по всему временному ряду.
В случае если, ретроспективное
прогнозирование осуществлять по связным
и многомерным динамическим рядам, то
точность прогноза, соответственно,
будет зависеть от точности определения
значений факторных признаков, включенных
в многофакторную динамическую модель,
на всем периоде упреждения. При этом,
возможны следующие подходы к
прогнозированию по связным временным
рядам: можно использовать как фактические,
так и прогнозные значения признаков.
Все показатели оценки точности
статистических прогнозов условно можно
разделить на три группы:
-
аналитические;
-
сравнительные;
-
качественные.
Аналитические показатели точности
прогноза позволяют количественно
определить величину ошибки прогноза.
К ним относятся следующие показатели
точности прогноза:
Абсолютная ошибка прогноза (D*)
определяется как разность между
эмпирическим и прогнозным значениями
признака и вычисляется по формуле:
![]() , (16.1)
, (16.1)
где уt– фактическое
значение признака;
![]() —
—
прогнозное значение признака.
Относительная ошибка прогноза (d*отн)
может быть определена как отношение
абсолютной ошибки прогноза (D*):
-
к
фактическому значению признака (уt):

(16.2)
— к прогнозному
значению признака (![]() )
)

(16.3)
Абсолютная и относительная ошибки
прогноза являются оценкой проверки
точности единичного прогноза, что
снижает их значимость в оценке точности
всей прогнозной модели, так как на
изучаемое социально-экономическое
явление подвержено влиянию различных
факторов внешнего и внутреннего
свойства. Единично удовлетворительный
прогноз может быть получен и на базе
реализации слабо обусловленной и
недостаточно адекватной прогнозной
модели и наоборот – можно получить
большую ошибку прогноза по достаточно
хорошо аппроксимирующей модели.
Поэтому на практике иногда определяют
не ошибку прогноза, а некоторый
коэффициент качества прогноза (Кк),
который показывает соотношение между
числом совпавших (с) и общим числом
совпавших (с) и несовпавших (н) прогнозов
и определяется по формуле:
![]() (16.4)
(16.4)
Значение Кк= 1 означает, что имеет
место полное совпадение значений
прогнозных и фактических значений и
модель на 100% описывает изучаемое
явление. Данный показатель оценивает
удовлетворительный вес совпавших
прогнозных значений в целом по временному
ряду и изменяющегося в пределах от 0 до
1.
Следовательно, оценку точности получаемых
прогнозных моделей целесообразно
проводить по совокупности сопоставлений
прогнозных и фактических значений
изучаемых признаков.
Средним показателем точности прогноза
является средняя абсолютная ошибка
прогноза (![]() ),
),
которая определяется как средняя
арифметическая простая из абсолютных
ошибок прогноза по формуле вида:
 , (16.5)
, (16.5)
де n– длина временного
ряда.
Средняя абсолютная ошибка прогноза
показывает обобщенную характеристику
степени отклонения фактических и
прогнозных значений признака и имеет
ту же размерность, что и размерность
изучаемого признака.
Для оценки точности прогноза используется
средняя квадратическая ошибка прогноза,
определяемая по формуле:
 (16.6)
(16.6)
Размерность средней квадратической
ошибки прогноза также соответствует
размерности изучаемого признака. Между
средней абсолютной и средней квадратической
ошибками прогноза существует следующее
примерное соотношение:
![]() (16.7)
(16.7)
Недостатками средней абсолютной и
средней квадратической ошибками
прогноза является их существенная
зависимость от масштаба измерения
уровней изучаемых социально-экономических
явлений.
Поэтому на практике в качестве
характеристики точности прогноза
определяют среднюю ошибку аппроксимации,
которая выражается в процентах
относительно фактических значений
признака, и определяется по формуле
вида:
![]() (16.8)
(16.8)
Данный показатель является относительным
показателем точности прогноза и не
отражает размерность изучаемых
признаков, выражается в процентах и на
практике используется для сравнения
точности прогнозов полученных как по
различным моделям, так и по различным
объектам. Интерпретация оценки точности
прогноза на основе данного показателя
представлена в следующей таблице:
-
 ,%
,%Интерпретация
точности< 10
10 – 20
20 – 50
> 50
Высокая
Хорошая
Удовлетворительная
Не удовлетворительная
В качестве сравнительного показателя
точности прогноза используется
коэффициент корреляции между прогнозными
и фактическими значениями признака,
который определяется по формуле:
 , (16.9)
, (16.9)
где
![]() —
—
средний уровень ряда динамики прогнозных
оценок.
Используя данный коэффициент в оценке
точности прогноза следует помнить, что
коэффициент парной корреляции в силу
своей сущности отражает линейное
соотношение коррелируемых величин и
характеризует лишь взаимосвязь между
временным рядом фактических значений
и рядом прогнозных значений признаков.
И даже если коэффициент корреляции R= 1, то это еще не предполагает полного
совпадения фактических и прогнозных
оценок, а свидетельствует лишь о наличии
линейной зависимости между временными
рядами прогнозных и фактических значений
признака.
Одним из показателей оценки точности
статистических прогнозов является
коэффициент несоответствия (КН), который
был предложен Г. Тейлом и может
рассчитываться в различных модификациях:
-
Коэффициент несоответствия (КН1),
определяемый как отношение средней
квадратической ошибки к квадрату
фактических значений признака:
 (16.10)
(16.10)
КН = о, если
 ,
,
то есть полное совпадение фактических
и прогнозных значений признака.
КН = 1, если при прогнозировании получают
среднюю квадратическую ошибку адекватную
по величине ошибке, полученной одним
из простейших методов экстраполяции
неизменности абсолютных цепных
приростов.
КН > 1, когда прогноз дает худшие
результаты, чем предположение о
неизменности исследуемого явления.
Верхней границы коэффициент несоответствия
не имеет.
2.Коэффициент несоответствия КН2определяется как отношение средней
квадратической ошибки прогноза к сумме
квадратов
отклонений
фактических значений признака от
среднего уровня исходного временного
ряда за весь рассматриваемый период:
 , (16.11)
, (16.11)
где ![]() — средний уровень исходного ряда
— средний уровень исходного ряда
динамики.
Если КН > 1, то прогноз на уровне среднего
значения признака дал бы лучший
результат, чем имеющийся прогноз.
3.Коэффициент несоответствия (КН3),
определяемый как отношение средней
квадратической ошибке прогноза к сумме
квадратов отклонений фактических
значений признака от теоретических,
выравненных по уравнению тренда:
 , (16.12)
, (16.12)
где ![]() — теоретические уровни временного ряда,
— теоретические уровни временного ряда,
полученные по
модели тренда.
Если КН > 1, то прогноз методом
экстраполяции тренда дает хороший
результат.

Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
.
SD – стандартное отклонение

где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже. Скачать пример расчета в Excel >>>
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:

где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Источник: сайт http://uppravuk.net/
From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]

It is thus an arithmetic average of the absolute errors 


Quantity disagreement and allocation disagreement[edit]
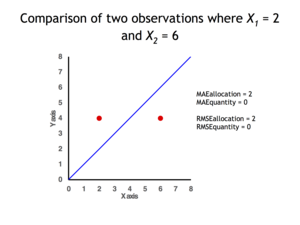
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]

Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an 
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is

Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of

as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising 

Proof:
The Loss functions for classification is
![{displaystyle {begin{aligned}L&=mathbb {E} [|y-a||X=x]&=int _{-infty }^{infty }|y-a|f_{Y|X}(y),dy&=int _{-infty }^{a}(a-y)f_{Y|X}(y),dy+int _{a}^{infty }(y-a)f_{Y|X}(y),dyend{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e953e54457072620a7c2764db0801f69c4e883d)
Differentiating with respect to a gives

This means

Hence

See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]
It is thus an arithmetic average of the absolute errors
Quantity disagreement and allocation disagreement[edit]
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]
Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is
Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of
as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising
Proof:
The Loss functions for classification is
Differentiating with respect to a gives
This means
Hence
See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
Оценка ошибки прогнозирования временного ряда
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE.
Пусть ошибка есть разность:
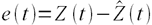 ,
,
где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах
 .
.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
ME – средняя ошибка
 .
.
SD – стандартное отклонение
 , где ME – есть средняя ошибка, определенная по формуле выше.
, где ME – есть средняя ошибка, определенная по формуле выше.
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.