Есть много способов, которые помогут повысить качество программы. В этой статье предлагаю взглянуть на один из них – статический анализ кода.

Содержание
- Кратко о статическом анализе кода
- Инструменты и технологии для статического анализа кода
- Анализ потока данных
- Аннотирование методов
- Сопоставление с шаблоном
- Символьное выполнение
- Статический анализ кода на практике
- Примеры найденных ошибок
- Заключение
Кратко о статическом анализе кода
Как вы, наверное, уже знаете, статические анализаторы позволяют проверять код без запуска самой программы. Последнее время популярность статического анализа при разработке набирает обороты, а рынок статического анализа с каждым годом становится больше. Отчасти это связано с тем, что прошла эра линтеров, которые были основаны только на регулярных выражениях.
Сейчас статический анализ поражает своим разнообразием и возможностями. Даже хайп с AI и машинным обучением не прошел мимо анализаторов, и швейцарцы выпустили продукт, обучающийся на открытых репозиториях. Однако надо понимать, что AI в обозримом будущем не заменит классические технологии, применяемые в статических анализаторах, а пополнит их.
Инструменты и технологии для статического анализа кода
Одним из современных статических анализаторов является инструмент PVS-Studio. Этот инструмент позволяет выявлять ошибки и потенциальные уязвимости в исходном коде программ, написанных на языках С, C++, C# и Java. Работает в 64-битных системах на Windows, Linux и macOS и может анализировать код, предназначенный для 32-битных, 64-битных и встраиваемых ARM платформ. Кратко рассмотрим, какие технологии использует PVS-Studio при анализе исходного кода.
Анализ потока данных
Начнем с анализа потока данных. Он позволяет вычислить возможные значения переменных в разных точках программы. Благодаря Data-Flow Analysis можно находить такие ошибки, как выход за границу массива, утечки памяти, разыменование нулевого указателя и т.д.
Аннотирование методов
Ручное и автоматическое аннотирование методов. Оно предоставляет больше информации об используемых методах, чем может быть получено путём анализа только их сигнатуры.
Сопоставление с шаблоном
Сопоставление с шаблоном. Анализатор, проверяя код, может находить заданные заранее паттерны, типичные для какой-либо ошибки. В простейшем варианте этот поиск похож на поиск ошибок с помощью регулярных выражений, однако всё обстоит несколько сложнее. Для поиска ошибок используется обход и анализ дерева разбора. Почему для этих задач неприемлемо использовать регулярные выражения, можно узнать из статьи «Статический анализ и регулярные выражения».
Символьное выполнение
Символьное выполнение. Оно позволяет находить недочеты в коде, даже не зная, какое значение переменных будет в строке с ошибкой. Небольшой пример, чтобы было нагляднее:
void Foo(int A, int B, int C)
{
if(A<B)
{
if(B<C)
{
if(A>C)
{
....
}
}
}
}
Не зная ничего о значениях переменных A, B и C, анализатор PVS-Studio способен понять, что условие (A > C) всегда ложно, и сообщить об этом разработчику. Подробнее с этим и другими принципами, положенными в основу анализатора, можно познакомиться в статье «Технологии, используемые в анализаторе кода PVS-Studio для поиска ошибок и потенциальных уязвимостей».
Я знаю, о чем подумали некоторые читатели этой статьи. Это все, конечно, классно, но зачем нам статический анализ? Приведу пример из своей жизни. У меня был маленький пет-проект – светодиодные костюмы, которые светятся и моргают под музыку (при нажатии кнопки «плей» в программе на компьютере запускается таймер, который и отправляет на светодиоды значение RGB). Однажды, внеся очередные правки в код, я включила костюм и поняла, что он сходит с ума. Костюм хаотично моргал и светился теми цветами, которые я видеть вообще не ожидала, и больше напоминал кошмар эпилептика, чем светодиодную шмотку. На поиск ошибки у меня ушло, наверное, около часа, я перечитывала свой код немыслимое количество раз, а причина оказалась в банальной опечатке в одной цифре… мда.
К слову, ошибку, которую я допустила, успешно находит статический анализ.
private void saveip6_Click(object sender, RoutedEventArgs e)
{
saveIp(ip6.Text.ToString(), 6);
....
}
private void saveip7_Click(object sender, RoutedEventArgs e)
{
saveIp(ip6.Text.ToString(), 6); // Должно быть 7
....
}
Предупреждение PVS-Studio: V3013 It is odd that the body of ‘saveip6_Click’ function is fully equivalent to the body of ‘saveip7_Click’ function (5254, line 5260). MainWindow.xaml.cs 5254
Тут я методом копипасты писала код, сохраняющий ip-адрес контроллеров костюмов из текстбоксов. И, дабы быть честной, признаюсь, что цифра 6 тут из головы. Я не помню, в каком конкретно обработчике событий так неудачно накопипастила. Ну и не важно, самое главное – передать суть.
Однако у меня была довольно небольшая кодовая база и, следовательно, маленький объем всевозможных ошибок и опечаток. Цифры, взятые из книги Стива Макконнелла «Совершенный код», гласят, что с ростом размера проекта растёт и плотность ошибок.

Именно поэтому инструменты статического анализа все больше набирают популярность среди крупных компаний, занимающихся разработкой.
Заметка! Compiler Explorer использует анализатор PVS-Studio.
Статический анализ кода на практике
Давайте теперь перейдём от теории к практике и на примере посмотрим, какие ошибки можно выявлять с помощью статического анализа кода. Для этого возьмём небольшой реальный открытый проект Extended WPF Toolkit и проверим его с помощью PVS-Studio.
Extended WPF Toolkit – это коллекция элементов управления и компонентов для WPF приложений. Проект включает в себя около 600 файлов исходного кода на языке C# и около 112 тысяч строк. Этот бесплатный набор инструментов имеет открытый исходный код и предоставляется в рамках лицензии Microsoft Public License. Также разработчики уже на платной основе предлагают воспользоваться Toolkit Plus Edition и Business Suite, в которых еще больше разнообразных компонентов и элементов управления, несколько тем под Metro и Windows 10 и многое другое.
Впрочем, все эти подробности нам не очень важны. Главное, что это обыкновенный типовой проект, написанный на языке C#. Давайте рассмотрим некоторые из ошибок, который в нём были найдены. Надеюсь, приведённых примеров будет достаточно для получения общего представления о технологии анализа кода. Более полное впечатление вы сможете составить самостоятельно, скачав и запустив анализатор на своих проектах. См. также «Как быстро посмотреть интересные предупреждения, которые выдает анализатор PVS-Studio для C и C++ кода?».
Примеры найденных ошибок
Предупреждение PVS-Studio: V3006 The object was created but it is not being used. The ‘throw’ keyword could be missing: throw new InvalidOperationException(FOO). DockingManager.cs 1129
internal void InternalAddLogicalChild( object element )
{
....
if(_logicalChildren.Select(ch => ch.GetValueOrDefault<object>())
.Contains( element ) )
new InvalidOperationException();
....
}
Это предупреждение анализатора сообщает о том, что был создан экземпляр класса InvalidOperationException, который в коде не используется. Видимо, программист хотел, чтобы при выполнении условия генерировалось исключение, но забыл написать оператор throw, который бы это исключение вызывал.
Предупреждение PVS-Studio: V3083 Unsafe invocation of event ‘PropertyChanged’, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. CheckListsView.xaml.cs 124
public event PropertyChangedEventHandler PropertyChanged;
protected void OnPropertyChanged( string propertyName )
{
if( PropertyChanged != null )
{
PropertyChanged( this, new PropertyChangedEventArgs( propertyName ) );
PropertyChanged( this, new PropertyChangedEventArgs( "ModelDisplay" ) );
}
}
Анализатор предупреждает о том, что был создан потенциально небезопасный вызов обработчика события. Проблема этого кода заключается в том, что одной проверки на null в этом случае недостаточно. В многопоточном приложении между проверкой на null и кодом в then-ветви оператора if может выполниться код в другом потоке, выполняющий отписку от данного события. Если это произойдет, и подписчиков у события не останется, то такой случай приведет к возникновению исключения NullReferenceException.
Для того, чтобы гарантированно произошло безошибочное выполнение вызова события, есть несколько способов переписать этот код. Я приведу один пример, а разработчики сами решат – воспользоваться моим способом, найти другой, и стоит ли вообще с этим кодом что-то делать.
protected void OnPropertyChanged( string propertyName )
{
PropertyChangedEventHandler eventHandler = PropertyChanged;
if( eventHandler != null )
{
eventHandler( this, new PropertyChangedEventArgs( propertyName ) );
eventHandler( this, new PropertyChangedEventArgs( "ModelDisplay" ) );
}
}
В этом примере мы сохраняем ссылку на обработчик события в переменную eventHandler. Теперь, даже если произойдет отписка от события и подписчиков не останется, переменная eventHandler всё равно будет содержать ссылку на первоначальный обработчик и код выполнится корректно.

Подобные проблемы в коде встретились более 30 раз. Все подобные предупреждения в рамках этой статьи смотреть будет скучно, поэтому предлагаю автору проекта самостоятельно попробовать их найти и исправить.
Предупреждение PVS-Studio: V3117 Constructor parameter ‘ignore’ is not used. AnimationRate.cs 59
private AnimationRate( bool ignore )
{
_duration = 0;
_speed = double.NaN;
_rateType = RateType.Speed;
}
Это предупреждение говорит о том, что параметр ignore не используется в этом коде. Судя по названию параметра, это ложное срабатывание и вскоре ‘ignore’ уберут из этого кода. Если это так, то предлагаю использовать атрибут ‘Obsolete’, который используется как раз в таких случаях.
[Obsolete("убрать параметр ignore")]
private AnimationRate( bool ignore )
{
_duration = 0;
_speed = double.NaN;
_rateType = RateType.Speed;
}
Предупреждение PVS-Studio: V3114 IDisposable object ‘reader’ is not disposed before method returns. CSharpFormat.cs 211
protected override string MatchEval( ....) //protected override
{
if( match.Groups[ 1 ].Success ) //comment
{
StringReader reader = new StringReader( match.ToString() );
....
}
}
Анализатор указывает на то, что объект reader класса StringReader реализует интерфейс ‘IDisposable’, но метод Dispose() для этого объекта в коде не был вызван. Тут, на самом деле, возникла двоякая ситуация. Класс StringReader и правда реализует данный интерфейс, но он его унаследовал от базового класса и никакими ресурсами он не владеет, поэтому вызывать Dispose() в этом случае не обязательно.
Предупреждение PVS-Studio: V3030 Recurring check. The ‘Layout.ActiveContent != null’ condition was already verified in line 2319. DockingManager.cs 2327
private void OnLayoutRootPropertyChanged( object sender,
PropertyChangedEventArgs e )
{
....
else if( e.PropertyName == "ActiveContent" )
{
if( Layout.ActiveContent != null )
{
//set focus on active element only after a layout pass is
//completed
//it's possible that it is not yet visible in the visual tree
//if (_setFocusAsyncOperation == null)
//{
// _setFocusAsyncOperation = Dispatcher.BeginInvoke(
// new Action(() =>
// {
if( Layout.ActiveContent != null )
FocusElementManager.SetFocusOnLastElement(
Layout.ActiveContent);
//_setFocusAsyncOperation = null;
// } ), DispatcherPriority.Input );
//}
}
....
}
}
Анализатор обращает внимание на то, что в двух условиях подряд проверяется одно и то же значение на null. Возможно, проверка избыточна, но так же есть и вероятность, что второе условие должно выглядеть иначе. Сложилось впечатление, что этот код просто не дописан.
Предупреждение PVS—Studio:
V3084 Anonymous function is used to unsubscribe from ‘HeaderDragDelta’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 355
V3084 Anonymous function is used to unsubscribe from ‘HeaderIconDoubleClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 356
V3084 Anonymous function is used to unsubscribe from ‘CloseButtonClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 357
public override void OnApplyTemplate()
{
....
if( _windowControl != null )
{
_windowControl.HeaderDragDelta
-= ( o, e ) =>
this.OnHeaderDragDelta( e );
_windowControl.HeaderIconDoubleClicked
-= ( o, e ) =>
this.OnHeaderIconDoubleClick( e );
_windowControl.CloseButtonClicked
-= ( o, e ) =>
this.OnCloseButtonClicked( e );
}
....
if( _windowControl != null )
{
_windowControl.HeaderDragDelta
+= ( o, e ) =>
this.OnHeaderDragDelta( e );
_windowControl.HeaderIconDoubleClicked
+= ( o, e ) =>
this.OnHeaderIconDoubleClick( e );
_windowControl.CloseButtonClicked
+= ( o, e ) =>
this.OnCloseButtonClicked( e );
}
....
}
В этом коде _windowControl отписывается от события, а потом подписывается обратно. Проблема кроется в том, каким образом происходят манипуляции с событиями при помощи лямбда-выражений. Дело в том, что каждое объявление анонимной функции приводит к созданию отдельного экземпляра делегата. Корректный вариант использования анонимных функций при подписке с дальнейшей отпиской на события представляет собой создание и использование переменной, в которую сохранен обработчик-лямбда, например, так:
_event = (o, e) => this.OnHeaderDragDelta (o, e);
Подобные предупреждения анализатора:
- V3084 Anonymous function is used to unsubscribe from ‘Loaded’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 644
- V3084 Anonymous function is used to unsubscribe from ‘HeaderDragDelta’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 327
- V3084 Anonymous function is used to unsubscribe from ‘HeaderIconDoubleClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 328
- V3084 Anonymous function is used to unsubscribe from ‘CloseButtonClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 329
Предупреждение PVS-Studio: V3013 It is odd that the body of ‘OnMaxScaleChanged’ function is fully equivalent to the body of ‘OnMinScaleChanged’ function (656, line 695). Zoombox.cs 656
private static void OnMinScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
Zoombox zoombox = ( Zoombox )o;
zoombox.CoerceValue( Zoombox.MinScaleProperty );
zoombox.CoerceValue( Zoombox.ScaleProperty );
}
private static void OnMaxScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
Zoombox zoombox = ( Zoombox )o;
zoombox.CoerceValue( Zoombox.MinScaleProperty );
zoombox.CoerceValue( Zoombox.ScaleProperty );
}
В этом коде анализатор нашел две функции OnMinScaleChanged и OnMaxScaleChanged, реализованные идентичным образом. При этом в коде было создано свойство зависимости с именем MaxScaleProperty. Есть подозрения, что во втором случае код должен выглядеть так:
private static void OnMaxScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
....
zoombox.CoerceValue( Zoombox.MaxScaleProperty );
....
}
Подобные сообщения анализатора:
- V3013 It is odd that the body of ‘OnCoerceLeft’ function is fully equivalent to the body of ‘OnCoerceTop’ function (299, line 355). WindowControl.cs 299
- V3013 It is odd that the body of ‘OnMouseLeftButtonDown’ function is fully equivalent to the body of ‘OnMouseRightButtonDown’ function (156, line 162). LayoutDocumentControl.cs 156
Предупреждение PVS-Studio: V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions ‘newValue != null’ and ‘newValue == null’. Selector.cs 181
public IList SelectedItems
{
....
private set
{
....
{
....
{
if(((newValue != null) &&
!newValue.Contains(item)) ||
(newValue == null))
{
....
}
}
}
....
}
Данный код является избыточным и его нужно упростить, о чем и сообщает анализатор. Все дело в том, что слева и справа от оператора ‘||’ стоят выражения (newValue != null) и (newValue == null). На первый взгляд кажется, что при упрощении пострадает логика программы, ведь в первом подвыражении проверяется не только наличие какого-либо значения у переменной newValue, но еще и item. Однако если написать так, то не только не пострадает работоспособность программы, но и улучшится читабельность кода:
if (newValue == null || !newValue.Contains(item))
Подобные ошибки, найденные анализатором:
- V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions ‘oldValue != null’ and ‘oldValue == null’. Selector.cs 198
- V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions. cs 85
Предупреждение PVS-Studio: V3051 An excessive type cast. The object is already of the ‘Magnifier’ type. MagnifierManager.cs 62
private void Element_MouseLeave( object sender, MouseEventArgs e )
{
var magnifier = MagnifierManager.GetMagnifier( _element ) as Magnifier;
....
}
public static Magnifier GetMagnifier( UIElement element )
{
return ( Magnifier )element.GetValue( CurrentProperty );
}
Анализатор указывает на то, что программист привел объект к своему же типу. Данная проверка является избыточной. Это не является ошибкой и можно оставить ключевое слово var в объявлении magnifier, но нагляднее будет явно указать тип переменной.
Обычно после описания ошибки идет перечисление всех мест, где попадался подобный ошибочный код, но в этом случае выписать все предупреждения не получится. В коде попалось более 50 (!) подобных предупреждений анализатора (не считая того, что могло попасть на уровень Low, который я смотрела не так внимательно, как остальные), что на мой взгляд чересчур много.
Предупреждение PVS-Studio: V3116 Consider inspecting the ‘for’ operator. It’s possible that the loop will be executed incorrectly or won’t be executed at all. CollectionControl.cs 642
internal void PersistChanges( IList sourceList )
{
....
{
....
{
{
var list = (IList)collection;
list.Clear();
if( list.IsFixedSize )
{
if( sourceList.Count > list.Count )
throw new IndexOutOfRangeException(....);
for(int i = 0; i < sourceList.Count; ++i ) // <=
list[ i ] = sourceList[ i ];
}
....
}
....
}
....
}
Код в цикле for не выполнится ни разу по следующим причинам: сначала программа очищает list, потом сравнивает размер sourceList и list (генерируя исключение, если количество элементов в sourceList больше чем в пустом list), а далее пытается заполнить список list значениями из sourceList через цикл.
Предупреждение PVS-Studio: V3020 An unconditional ‘break’ within a loop. LayoutRoot.cs 542
public void CollectGarbage()
{
bool exitFlag = true;
....
do
{
exitFlag = true;
....
foreach( .... )
{
....
while( singleChild.ChildrenCount > 0 )
{
....
}
exitFlag = false;
break;
}
}
while( !exitFlag );
....
}
Вне зависимости от значения singleChild.ChildrenCount, из-за оператора break выполняется ровно одна итерация цикла foreach. Да и вообще код очень странный, непонятно, стоит ли это расценивать как ошибку, вдруг это так и было задумано…
Заключение
На примере проекта Extended WPF Toolkit мы убедились в значимости статического анализа при создании программного продукта. WPF Toolkit представляет собой совсем небольшой проект, однако на 112 тысяч строк кода попалось довольно много однотипных ошибок, вроде идентично реализованных методов, приведения объектов к своему же типу и т.д. Все эти ошибки легко находятся при помощи статического анализатора кода PVS-Studio, которым можно воспользоваться, скачав пробную версию по ссылке. Если ввести промокод #infocomp в поле «Сообщение», то можно получить лицензию на один месяц вместо 7 дней.
Автор: Екатерина Никифорова


Регулярное использование статического анализа кода в командной разработке
- Введение
- Что такое статический анализ кода
- Для каких проектов актуален статический анализ кода
- Варианты (сценарии) использования статических анализаторов кода
- Что мешает полноценному использованию статического анализатора кода
- Заключение
- Библиографический список
Технологии статического анализа кода применяются в компаниях со зрелыми процессами разработки программного обеспечения. Однако уровень применения и внедрения в процесс разработки инструментов анализа кода может быть различным. Начиная от ручного запуска анализатора «время от времени» или при поиске трудноуловимых ошибок, и кончая ежедневным автоматическим запуском или запуском при добавлении нового исходного кода в систему контроля версий.
В статье рассмотрены различные уровни использования технологий статического анализа кода в командной разработке, показано как «перевести» процесс с одного уровня на другой. В качестве примера в статье используется разрабатываемый авторами анализатор кода PVS-Studio.
Введение
Статический анализатор кода – это инструмент для поиска программных ошибок по исходному коду. Применение такого инструмента помогает избежать выявления программных ошибок еще на этапе разработки, а не на этапах тестирования или использования.
Однако далеко не всегда компаниям удается получить выгоду от подобных инструментов. Причины этого самые разные. Какие-то проекты просто экономически не подходят для внедрения анализатора кода, какие-то проекты не достаточно большие, чтобы эффект был заметен. Поэтому перед внедрением в процесс разработки статического анализа кода необходимо понимать, когда это может принести пользу, а когда – нет.
В статье на основе опыта авторов (занимающихся разработкой, продвижением и продажей собственного статического анализатора кода) сформулированы основные соображения, которыми стоит руководствоваться при внедрении подобных инструментов в процесс разработки.
Что такое статический анализ кода
Статический анализ кода – это технология поиска ошибок в программах путем разбора исходного кода и поиска в нем паттернов (шаблонов) известных ошибок. Эта технология реализуется специальными инструментами, называемыми статическими анализаторами кода.
Слово «статический» означает, что код разбирается без запуска программы на выполнение. Инструменты, которые анализируют программу во время ее работы, называются динамическими анализаторами кода.
Наиболее известные статические анализаторы выпускают компании Coverity, Klocwork, Gimpel Software. Популярные динамические анализаторы делают компании Intel (Intel Parallel Inspector) и Micro Focus (DevPartner Bounds Checker). Необходимо также упомянуть специализированный статический анализатор кода PVS-Studio, разработкой и продвижением которого занимаются авторы статьи.
Результат работы статического анализатора – это список обнаруженных в коде потенциальных проблем с указанием имени файла и конкретной строки. Другими словами, это список ошибок, очень похожий на тот, что выдает компилятор. Термин «потенциальные проблемы» используется здесь не случайно. К сожалению, статический анализатор не может абсолютно точно сказать, является ли эта потенциальная ошибка в коде реальной проблемой. Это может знать только программист. Поэтому, увы (и это неизбежно), анализаторы кода дают ложные срабатывания.
Инструменты для статического анализа кода делятся по типу поддерживаемых языков программирования (Java, C#, C, C++), по диагностируемым проблемам (анализаторы общего назначения или специализированные, например, для разработки 64-битных или параллельных программ).
Для каких проектов актуален статический анализ кода
Статический анализ кода целесообразно применять не во всех проектах, а только в средних и крупных. Дискуссия на тему что считать малым/средним/большим проектом явно выходит за рамки данной статьи, однако по своему опыту мы рекомендуем задуматься о применении статического анализа в проектах, размер которых более 30 человеко-месяцев. Если программный проект меньше указанного размера, то вместо использования статического анализа достаточно иметь в проекте нескольких квалифицированных разработчиков. Команда из двух-четырех квалифицированных сотрудников вполне потянет такой проект и сможет сделать его качественно с программной точки зрения. Но вот если над проектом работают либо больше людей, либо проект длиться более полугода, то надеяться на то, что «надо просто писать без ошибок» достаточно наивно.
Варианты (сценарии) использования статических анализаторов кода
Рассмотрим ситуации, при которых команда разработчиков может прийти к необходимости использовать статический анализ кода. Здесь намеренно рассматривается случай, когда статический анализ только появляется в процессе разработки – ведь если статический анализ давно уже внедрен и используется, то и обсуждать вопросы внедрения не имеет смысла.
Итак, предположим, команда из 5 человек занимается тем, что выполняет перенос кода программного проекта для работы на 64-битных компьютерах. Предположим также, что код проекта написан на C/C++. Заранее скажем, что такие предпосылки сделаны для того, чтобы в примере можно было использовать наш анализатор кода PVS-Studio. Разработчики исправили основные ошибки компиляции, собрали приложение, дистрибутив. Начали тестировать и выяснили, что в программе есть крайне загадочные ошибки, которые проявляются только в 64-битной версии программы. Разработчики идут в Google, вводят «64-bit platform с++ issues» и среди 8.5 млн результатов на первой странице находят ссылку на нашу статью «20 issues of porting C++ code on the 64-bit platform» (в русском варианте «20 ловушек переноса Си++ — кода на 64-битную платформу»), из которой узнают, что оказывается в C/C++ приложениях при разработке 64-битных версий программ проявляются разные незаметные ранее проблемы. Там же они узнают, что есть инструмент PVS-Studio, который позволит эти проблемы найти и исправить. Далее разработчики скачивают инструмент, смотрят на ознакомительную версию, если он их устраивает, то покупают лицензию, находят с помощью инструмента сколько-то ошибок в своем коде, исправляют их, и программа оказывается без ошибок. После чего разработчики считают задачу создания 64-битной версии программы законченной и далее отказываются от использования анализатора, так как считают, что он им не нужен больше.
Другой сценарий, близкий к этому. При разработке Java-приложения команда из 5 разработчиков столкнулась с ошибкой в одном из сторонних модулей. К сожалению, найти ошибку в коде «глазами» не получилось, разработчики скачали ознакомительную версию какого-либо анализатора кода для Java, с его помощью нашли ошибку в этом стороннем модуле, исправили ее, но покупать лицензию на инструмент не стали – ограничения бюджета проекта. Ошибка исправлена, приложение выпущено, лицензия на инструмент не нарушена. Вроде бы все нормально, но и этот вариант использования статического анализатора нельзя назвать правильным.
Третий вариант использования. Разработчики перешли на использование Visual Studio Team Foundation Server, в котором есть возможность запускать анализ кода для файлов, добавляемых в систему контроля версий. Несколько недель спустя, разработчики отключили проверку кода, поскольку добавление нового кода превратилось в игру «убеди анализатор разрешить добавить файл».
Все эти три рассмотренных варианта использования не являются удачными случаями применения статического анализа. И это несмотря на то, что в первых двух случаях анализатор помог найти реальные ошибки в коде, а в третьем код программистов видимо был откровенно плох. В чем же причины этих неудач?
Что мешает полноценному использованию статического анализатора кода
Покажем причины того, что перечисленные выше три варианта использования статического анализа не являются удачными случаями применения.
Если команда применяет специализированный анализатор кода (как в описанном случае для поиска проблем 64-битного кода), то очень велик соблазн отказаться от инструмента после того, как проблемы вроде бы найдены и исправлены. И действительно, если выпущена 64-битная версия программного продукта, может показаться, что дальше использовать специальный инструмент смысла нет. Однако это не так. Если отказаться от использования такого анализатора, то со временем (через несколько месяцев) уже в новом коде будут возникать те ошибки, которые могли бы быть обнаружены с использованием анализатора кода. То есть, хотя 64-битная версия приложения существует и (когда-то) была отлажена, новый код может содержать ошибки, характерные для 64-битных приложений. Вывод по первому сценарию использования – отказ от специализированного анализатора кода после того, как основная работа с ним закончена, приводит к скорому появлению новых программных ошибок подобного типа.
Во втором описанном случае команда решила применить специализированный инструмент только тогда, когда уже стало очевидным наличие трудно обнаруживаемых ошибок в проекте. И после исправления этих ошибок команда отказалась от инструмента. Проблема в этом подходе в том, что трудно обнаруживаемые ошибки снова рано или поздно появятся в проекте. Но, возможно, сначала их теперь уже увидят пользователи, а не разработчики или тестировщики. Вывод по второму сценарию использования совпадает с первым выводом – отказ от инструмента обязательно приведет вновь к появлению трудно обнаруживаемых ошибок.
В третьем сценарии использования, когда из-за трудностей добавления нового кода в систему контроля версий от статического анализа при добавлении кода решено было отказаться, вообще проблема не в статическом анализаторе, а в недостаточном уровне команды. Во-первых, команда не смогла настроить инструмент так, чтобы его сообщения были полезными. А, во-вторых, видимо код действительно был не очень хорошим, раз анализатор выдавал много диагностических сообщений.
Итак, сформулируем основные проблемы, которые мешают использовать постоянно в работе инструменты статического анализа кода:
- Высокая цена инструментов анализа кода не позволяет применять эти инструменты в малых (прежде всего по бюджету) проектах. Надо просто понимать, что есть проекты, в которых статический анализ не подходит не из-за технологических, а из-за экономических причин.
- Инструмент для анализа кода дает много ложных срабатываний. Увы, любой анализатор кода дает ложные срабатывания и зачастую дает их довольно много. Причина здесь кроется в философии подобных инструментов. Лучше выдать десять-сто ложных сообщений, чем пропустить одно настоящее. Надеяться на то, что какие-то анализаторы выдают мало ложных срабатываний не стоит. Лучше выбрать инструмент, который каким-то образом поддерживает возможность работы с ложными срабатываниями. Например, наш анализатор PVS-Studio содержит функцию «Mark as False Alarm». С ее помощью можно разметить ложные срабатывания анализатора прямо в коде. То есть указать, что анализатор не должен выдавать такой-то тип сообщений в такой-то строке.
- Плохая интеграция в среду разработки. Если инструмент для анализа кода не имеет гладкой «бесшовной» интеграции в среду разработки, то вряд ли им будут пользоваться регулярно.
- Отсутствие возможности автоматизированного запуска с помощью командной строки. Это не позволяет выполнять анализ кода всего проекта регулярно, например, во время ежедневных сборок.
- Отсутствие возможности интеграции с системой контроля версий. Хотя в рассмотренном ранее примере проверка нового кода при добавлении его в систему контроля версий послужила отказом от использования подобных инструментов, все-таки сама возможность такой интеграции является полезной.
- Слишком сложные, либо наоборот слишком простые настройки анализатора кода.
Решением здесь является взаимодействие компании, которая хочет использовать технологии статического анализа кода с компанией, которая эти технологии предоставляет. То есть отношения из разряда «купить инструмент и использовать его» переходят в разряд «купить решение, внедрить его и только потом использовать». Нравится это или нет, но в большинстве случаев просто купить «программку-анализатор» и использовать ее с выгодой не удастся. Нужно «подтянуть» процесс разработки в компании и вместе с поставщиком решений для статического анализа внедрить предлагаемый им инструмент в постоянный регулярный процесс командной разработки.
По такой схеме работают лидеры рынка статического анализа вроде Coverity или Klocwork. Это кстати имеет, может быть, не совсем понятное внешнее проявление. У этих компаний не так-то просто получать хоть какую-то ознакомительную версию с сайта. А уж добиться ответа на вопрос «сколько стоит» и вовсе не возможно до тех пор, пока sales-менеджеры не узнают о клиенте максимум информации.
Заключение
Если ваша компания планирует применять статический анализ кода, то необходимо учитывать следующее:
- Внедрение статического анализа кода оказывает влияние на весь процесс разработки.
- Статический анализатор – это не мелкая утилита и не очередная копия Windows, которую можно купить и использовать без каких-либо взаимодействий с поставщиком. Всегда рассчитывайте на то, что необходимо плотно общаться с разработчиками анализатора, а процедура внедрения инструмента требует сил и времени.
- Статический анализатор повышает общую культуру разработки программного обеспечения в команде, но только если команда сама готова к этому повышению. То есть это процесс взаимный.
- Повышение культуры разработки через использование статических анализаторов кода процесс дорогостоящий. К этому надо быть готовым и понимать, что это потребует существенных вложений.
Библиографический список
- Алексей Колосов. Применение статического анализа при разработке программ. http://www.viva64.com/ru/a/0017/.
- Андрей Карпов. Изменения в инфраструктуре инструментов для программистов. http://www.viva64.com/ru/a/0062/.
Присылаем лучшие статьи раз в месяц
3574
Автор: admin
Отредактировано: 26.09.2017
Статический анализ кода — методика анализа качества программных продуктов, во время которого анализируемый продукт не запускается и не выполняется. Для такого анализа используется специализированное программное обеспечение, позволяющее обрабатывать ПО, написанное на полутора десятков разных языков программирования, выявлять в нем ошибки, рекомендовать корректное оформление кода, а также подсчитывать количество показателей, или метрик, обуславливающих качество программного обеспечения. По сути, этот метод является автоматизированным вариантом обзора кода, одного из самых эффективных, но при этом и самых дорогих методов обнаружения ошибок в программе.
Преимущества и недостатки статического анализа кода
Как и любая другая методика, статический анализ кода (читайте подробнее на http://www.a1qa.ru/services/security_testing/) обладает как достоинствами, так и недостатками. К числу первых можно несомненно отнести:
- выявление большого количества ошибок на среднем этапе конструирования ПО даже в тех фрагментах кода, которые невозможно протестировать другими методами;
- независимость от среды и компилятора, что дает возможность обнаруживать скрытые ошибки;
- быстрое обнаружение опечаток и дублирования символов.
Основными недостатками этого метода являются:
- невозможность или большое затруднение выявления ошибок, для обнаружения которых необходимо выполнить программу или ее часть;
- так называемые ложно-позитивные срабатывания — фрагменты правильного кода, тем не менее, вызывающие у анализатора подозрения.
Считается, что просматривание списка ложных срабатываний может рассеивать внимание программиста, что приводит к увеличению возможности пропустить серьезную ошибку.
Как мы используем статический анализ кода для тестирования безопасности
Используя статический анализ кода, можно значительно удешевить процесс выявления и последующего устранения ошибок в программном коде, в том числе и большого списка проблем безопасности. Это одна из причин того, что специалисты компании A1QA активно применяют эту методику для тестирования безопасности системы. Тем не менее, мы рассматриваем такой анализ только как составляющую часть общего подхода к процессу тестирования. Именно в сочетании с другими методами он дает наилучший результат, позволяя свести дефекты и недочеты программного кода к минимуму.
26.09.2017
Рубрики: Разработчику
Тэги: разработчику
Вы тут (типа навигация): IT — блог » Разработчику » Программный способ анализа качества ПО
Статический анализ кода
Разработка программного обеспечения – это не самый простой процесс. Команды программистов находятся под давлением. Качественные релизы должны быть выпущены вовремя. Необходимо соблюдать стандарты кодирования и соответствия требованиям (например, безопасности). А вот ошибки при этом должны быть сведены к минимуму. Вот почему команды разработчиков используют инструменты статического анализа. Здесь мы обсудим статический анализ и преимущества использования инструмента статического анализа кода.

Что такое статический анализ вообще?
Статический анализ можно описать как метод отладки путем автоматического изучения исходного кода перед запуском программы.
А что такое статический анализ кода?
Статический анализ кода — это метод отладки путем изучения исходного кода перед запуском программы. Он производится путем анализа набора кода на основе набора (или нескольких наборов) правил программирования. Статический анализ кода и статический анализ часто используются взаимозаменяемо, наряду с анализом исходного кода.
Этот тип анализа устраняет слабые места в исходном коде, которые могут привести к уязвимостям. Конечно, это также может быть достигнуто с помощью ручного анализа кода. Но использование автоматизированных инструментов гораздо эффективнее.
Статический анализ обычно используется для соблюдения основных принципов программирования — таких как MISRA. И он часто используется для соблюдения отраслевых стандартов — таких как ISO 26262.
На каком этапе выполняется статический анализ кода?
Статический анализ кода выполняется на ранних стадиях разработки, до начала тестирования программного обеспечения. Для организаций, практикующих DevOps, статический анализ кода происходит на этапе «создания».
Статический анализ кода также поддерживает DevOps, создавая автоматизированный контур обратной связи. Разработчики сразу же узнают, есть ли какие-то проблемы в их коде. И эти проблемы будет легче устранить.
А чем разница между статическим анализом и динамическим анализом?
Оба типа обнаруживают дефекты. Большая разница заключается в том, где они находят дефекты в жизненном цикле разработки.
Статический анализ выявляет дефекты перед запуском программы (например, между кодированием и модульным тестированием).
Динамический анализ выявляет дефекты после запуска программы (например, во время модульного тестирования). Однако некоторые ошибки кодирования могут не проявиться во время модульного тестирования. Таким образом, есть дефекты, которые динамическое тестирование может пропустить, что статический анализ кода может найти.
Каковы ограничения статического инструмента анализа кода?
Статический анализ кода используется с определенной целью на определенном этапе разработки. Но у статического инструмента анализа кода есть некоторые ограничения.
Нет понимания намерений разработчика
int calculateArea(int length, int width)
{
return (length + width);
}
Инструмент статического анализа может обнаружить возможное переполнение в этом расчете выше. Но он не может определить, что функция принципиально не делает то, что ожидается!
Некоторые правила кодирования зависят от внешней документации. Или же они открыты для субъективной интерпретации.
Например:
CERT-C MSC04: Используйте комментарии последовательно и в удобочитаемом виде.
Возможны ложные срабатывания.
int divide(void)
{
int x;
if(foo())
{
x = 0;
}
else
{
x = 5;
}
return (10/x);
}
Если мы ничего не знаем о foo(), мы не знаем, какое значение будет иметь ч.
Результат неразрешим. Это означает, что инструменты могут сообщать о дефектах, которые на самом деле не существуют (ложные срабатывания). Или они могут не сообщать о реальных дефектах (ложных негативах).
Каковы преимущества инструментов статического анализа?
Есть несколько преимуществ инструментов статического анализа кода — особенно если вам нужно соответствовать отраслевому стандарту. Лучшие инструменты статического анализа кода обеспечивают скорость, глубину и точность.
- Скорость. Разработчикам требуется время, чтобы выполнить проверку кода вручную. Автоматизированные инструменты работают гораздо быстрее. Статическая проверка кода решает проблемы на ранней стадии. И он точно указывает, где ошибка находится в коде. Таким образом, Вы сможете исправить эти ошибки быстрее. Кроме того, ошибки кодирования, обнаруженные ранее, менее затратны для исправления.
- Глубина. Тестирование не может охватить все возможные пути выполнения кода. Но статический анализатор кода может. Он проверяет код, когда вы работаете над своей сборкой. Вы получите углубленный анализ возможных проблем в вашем коде, основанный на правилах, которые вы применили.
- Точность. Ручные проверки кода подвержены человеческим ошибкам. Автоматизированные инструменты — нет. Они сканируют каждую строку кода, чтобы выявить потенциальные проблемы. Это поможет вам обеспечить высочайшее качество кода-до начала тестирования. В конце концов, когда вы соблюдаете стандарт кодирования, качество имеет решающее значение.
Как выбрать инструмент статического анализа кода
Вот пара вещей, которые следует учитывать при принятии решения о том, какой инструмент подходит именно вам.
- Язык программирования. Анализаторы предназначены для многих различных языков программирования. Поэтому важно выбрать инструмент, поддерживающий ваш язык.
- Стандарты. Одним из основных применений статических анализаторов является соблюдение стандартов. Поэтому, если вы работаете в регулируемой отрасли, где требуется стандарт кодирования, вы должны убедиться, что ваш инструмент поддерживает этот стандарт.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() заметки, теория программирования, инструменты разработки
заметки, теория программирования, инструменты разработки
Регулярное использование статического анализа кода в командной разработке
Время на прочтение
8 мин
Количество просмотров 14K

В преддверии выхода примерно в сентябре статического анализатора от Intel под названием Advisor, который войдет в Intel Parallel Studio 2011, нелишне будет в целом рассказать о технологии статического анализа кода и об ее применении. Дело в том, что по опыту в России статический анализ применяется не часто, видимо из-за того, что у нас не так много сложных программных проектов. Поэтому краткий текст на тему что это и кому может быть полезно, надеюсь, окажется кстати. Ну и кому же как не авторам анализатора PVS-Studio этот текст делать? 
Аннотация
Технологии статического анализа кода применяются в компаниях со зрелыми процессами разработки программного обеспечения. Однако уровень применения и внедрения в процесс разработки инструментов анализа кода может быть различным. Начиная от ручного запуска анализатора «время от времени» или при поиске трудноуловимых ошибок, и кончая ежедневным автоматическим запуском или запуском при добавлении нового исходного кода в систему контроля версий.
В статье рассмотрены различные уровни использования технологий статического анализа кода в командной разработке, показано как «перевести» процесс с одного уровня на другой. В качестве примера в статье используется разрабатываемый авторами анализатор кода PVS-Studio.
Введение
Статический анализатор кода — это инструмент для поиска программных ошибок по исходному коду. Применение такого инструмента помогает избежать выявления программных ошибок еще на этапе разработки, а не на этапах тестирования или использования.
Однако далеко не всегда компаниям удается получить выгоду от подобных инструментов. Причины этого самые разные. Какие-то проекты просто экономически не подходят для внедрения анализатора кода, какие-то проекты не достаточно большие, чтобы эффект был заметен. Поэтому перед внедрением в процесс разработки статического анализа кода необходимо понимать, когда это может принести пользу, а когда — нет.
В статье на основе опыта авторов (занимающихся разработкой, продвижением и продажей собственного статического анализатора кода) сформулированы основные соображения, которыми стоит руководствоваться при внедрении подобных инструментов в процесс разработки.
Что такое статический анализ кода
Статический анализ кода — это технология поиска ошибок в программах путем разбора исходного кода и поиска в нем паттернов (шаблонов) известных ошибок. Эта технология реализуется специальными инструментами, называемыми статическими анализаторами кода.
Слово «статический» означает, что код разбирается без запуска программы на выполнение. Инструменты, которые анализируют программу во время ее работы, называются динамическими анализаторами кода.
Наиболее известные статические анализаторы выпускают компании Coverity, Klocwork, Gimpel Software. Популярные динамические анализаторы делают компании Intel (Intel Parallel Inspector) и Micro Focus (DevPartner Bounds Checker). Необходимо также упомянуть специализированный статический анализатор кода PVS-Studio, разработкой и продвижением которого занимаются авторы статьи.
Результат работы статического анализатора — это список обнаруженных в коде потенциальных проблем с указанием имени файла и конкретной строки. Другими словами, это список ошибок, очень похожий на тот, что выдает компилятор. Термин «потенциальные проблемы» используется здесь не случайно. К сожалению, статический анализатор не может абсолютно точно сказать, является ли эта потенциальная ошибка в коде реальной проблемой. Это может знать только программист. Поэтому, увы (и это неизбежно), анализаторы кода дают ложные срабатывания.
Инструменты для статического анализа кода делятся по типу поддерживаемых языков программирования (Java, C#, C, C++), по диагностируемым проблемам (анализаторы общего назначения или специализированные, например, для разработки 64-битных или параллельных программ).
Для каких проектов актуален статический анализ кода
Статический анализ кода целесообразно применять не во всех проектах, а только в средних и крупных. Дискуссия на тему что считать малым/средним/большим проектом явно выходит за рамки данной статьи, однако по своему опыту мы рекомендуем задуматься о применении статического анализа в проектах, размер которых более 30 человеко-месяцев. Если программный проект меньше указанного размера, то вместо использования статического анализа достаточно иметь в проекте нескольких квалифицированных разработчиков. Команда из двух-четырех квалифицированных сотрудников вполне потянет такой проект и сможет сделать его качественно с программной точки зрения. Но вот если над проектом работают либо больше людей, либо проект длиться более полугода, то надеяться на то, что «надо просто писать без ошибок» достаточно наивно.
Варианты (сценарии) использования статических анализаторов кода
Рассмотрим ситуации, при которых команда разработчиков может прийти к необходимости использовать статический анализ кода. Здесь намеренно рассматривается случай, когда статический анализ только появляется в процессе разработки — ведь если статический анализ давно уже внедрен и используется, то и обсуждать вопросы внедрения не имеет смысла.
Итак, предположим, команда из 5 человек занимается тем, что выполняет перенос кода программного проекта для работы на 64-битных компьютерах. Предположим также, что код проекта написан на C/C++. Заранее скажем, что такие предпосылки сделаны для того, чтобы в примере можно было использовать наш анализатор кода PVS-Studio. Разработчики исправили основные ошибки компиляции, собрали приложение, дистрибутив. Начали тестировать и выяснили, что в программе есть крайне загадочные ошибки, которые проявляются только в 64-битной версии программы. Разработчики идут в Google, вводят «64-bit platform с++ issues» и среди 8.5 млн результатов на первой странице находят ссылку на нашу статью «20 issues of porting C++ code on the 64-bit platform» (в русском варианте «20 ловушек переноса Си++ — кода на 64-битную платформу»), из которой узнают, что оказывается в C/C++ приложениях при разработке 64-битных версий программ проявляются разные незаметные ранее проблемы. Там же они узнают, что есть инструмент PVS-Studio, который позволит эти проблемы найти и исправить. Далее разработчики скачивают инструмент, смотрят на ознакомительную версию, если он их устраивает, то покупают лицензию, находят с помощью инструмента сколько-то ошибок в своем коде, исправляют их, и программа оказывается без ошибок. После чего разработчики считают задачу создания 64-битной версии программы законченной и далее отказываются от использования анализатора, так как считают, что он им не нужен больше.
Другой сценарий, близкий к этому. При разработке Java-приложения команда из 5 разработчиков столкнулась с ошибкой в одном из сторонних модулей. К сожалению, найти ошибку в коде «глазами» не получилось, разработчики скачали ознакомительную версию какого-либо анализатора кода для Java, с его помощью нашли ошибку в этом стороннем модуле, исправили ее, но покупать лицензию на инструмент не стали — ограничения бюджета проекта. Ошибка исправлена, приложение выпущено, лицензия на инструмент не нарушена. Вроде бы все нормально, но и этот вариант использования статического анализатора нельзя назвать правильным.
Третий вариант использования. Разработчики перешли на использование Visual Studio Team Foundation Server, в котором есть возможность запускать анализ кода для файлов, добавляемых в систему контроля версий. Несколько недель спустя, разработчики отключили проверку кода, поскольку добавление нового кода превратилось в игру «убеди анализатор разрешить добавить файл».
Все эти три рассмотренных варианта использования не являются удачными случаями применения статического анализа. И это несмотря на то, что в первых двух случаях анализатор помог найти реальные ошибки в коде, а в третьем код программистов видимо был откровенно плох. В чем же причины этих неудач?
Что мешает полноценному использованию статического анализатора кода
Покажем причины того, что перечисленные выше три варианта использования статического анализа не являются удачными случаями применения.
Если команда применяет специализированный анализатор кода (как в описанном случае для поиска проблем 64-битного кода), то очень велик соблазн отказаться от инструмента после того, как проблемы вроде бы найдены и исправлены. И действительно, если выпущена 64-битная версия программного продукта, может показаться, что дальше использовать специальный инструмент смысла нет. Однако это не так. Если отказаться от использования такого анализатора, то со временем (через несколько месяцев) уже в новом коде будут возникать те ошибки, которые могли бы быть обнаружены с использованием анализатора кода. То есть, хотя 64-битная версия приложения существует и (когда-то) была отлажена, новый код может содержать ошибки, характерные для 64-битных приложений. Вывод по первому сценарию использования — отказ от специализированного анализатора кода после того, как основная работа с ним закончена, приводит к скорому появлению новых программных ошибок подобного типа.
Во втором описанном случае команда решила применить специализированный инструмент только тогда, когда уже стало очевидным наличие трудно обнаруживаемых ошибок в проекте. И после исправления этих ошибок команда отказалась от инструмента. Проблема в этом подходе в том, что трудно обнаруживаемые ошибки снова рано или поздно появятся в проекте. Но, возможно, сначала их теперь уже увидят пользователи, а не разработчики или тестировщики. Вывод по второму сценарию использования совпадает с первым выводом — отказ от инструмента обязательно приведет вновь к появлению трудно обнаруживаемых ошибок.
В третьем сценарии использования, когда из-за трудностей добавления нового кода в систему контроля версий от статического анализа при добавлении кода решено было отказаться, вообще проблема не в статическом анализаторе, а в недостаточном уровне команды. Во-первых, команда не смогла настроить инструмент так, чтобы его сообщения были полезными. А, во-вторых, видимо код действительно был не очень хорошим, раз анализатор выдавал много диагностических сообщений.
Итак, сформулируем основные проблемы, которые мешают использовать постоянно в работе инструменты статического анализа кода:
- Высокая цена инструментов анализа кода не позволяет применять эти инструменты в малых (прежде всего по бюджету) проектах. Надо просто понимать, что есть проекты, в которых статический анализ не подходит не из-за технологических, а из-за экономических причин.
- Инструмент для анализа кода дает много ложных срабатываний. Увы, любой анализатор кода дает ложные срабатывания и зачастую дает их довольно много. Причина здесь кроется в философии подобных инструментов. Лучше выдать десять-сто ложных сообщений, чем пропустить одно настоящее. Надеяться на то, что какие-то анализаторы выдают мало ложных срабатываний не стоит. Лучше выбрать инструмент, который каким-то образом поддерживает возможность работы с ложными срабатываниями. Например, наш анализатор PVS-Studio содержит функцию «Mark as False Alarm». С ее помощью можно разметить ложные срабатывания анализатора прямо в коде. То есть указать, что анализатор не должен выдавать такой-то тип сообщений в такой-то строке.
- Плохая интеграция в среду разработки. Если инструмент для анализа кода не имеет гладкой «бесшовной» интеграции в среду разработки, то вряд ли им будут пользоваться регулярно.
- Отсутствие возможности автоматизированного запуска с помощью командной строки. Это не позволяет выполнять анализ кода всего проекта регулярно, например, во время ежедневных сборок.
- Отсутствие возможности интеграции с системой контроля версий. Хотя в рассмотренном ранее примере проверка нового кода при добавлении его в систему контроля версий послужила отказом от использования подобных инструментов, все-таки сама возможность такой интеграции является полезной.
- Слишком сложные, либо наоборот слишком простые настройки анализатора кода.
Решением здесь является взаимодействие компании, которая хочет использовать технологии статического анализа кода с компанией, которая эти технологии предоставляет. То есть отношения из разряда «купить инструмент и использовать его» переходят в разряд «купить решение, внедрить его и только потом использовать». Нравится это или нет, но в большинстве случаев просто купить «программку-анализатор» и использовать ее с выгодой не удастся. Нужно «подтянуть» процесс разработки в компании и вместе с поставщиком решений для статического анализа внедрить предлагаемый им инструмент в постоянный регулярный процесс командной разработки.
По такой схеме работают лидеры рынка статического анализа вроде Coverity или Klocwork. Это кстати имеет, может быть, не совсем понятное внешнее проявление. У этих компаний не так-то просто получать хоть какую-то ознакомительную версию с сайта. А уж добиться ответа на вопрос «сколько стоит» и вовсе не возможно до тех пор, пока sales-менеджеры не узнают о клиенте максимум информации.
Заключение
Если ваша компания планирует применять статический анализ кода, то необходимо учитывать следующее:
- Внедрение статического анализа кода оказывает влияние на весь процесс разработки.
- Статический анализатор — это не мелкая утилита и не очередная копия Windows, которую можно купить и использовать без каких-либо взаимодействий с поставщиком. Всегда рассчитывайте на то, что необходимо плотно общаться с разработчиками анализатора, а процедура внедрения инструмента требует сил и времени.
- Статический анализатор повышает общую культуру разработки программного обеспечения в команде, но только если команда сама готова к этому повышению. То есть это процесс взаимный.
- Повышение культуры разработки через использование статических анализаторов кода процесс дорогостоящий. К этому надо быть готовым и понимать, что это потребует существенных вложений.
Статический анализ кода
- Обзор кода
- Статический анализ как автоматизация обзоров кода
- Что даёт внедрение статического анализа в процесс разработки?
- Инструменты статического анализа кода
- Сильные стороны статического анализа кода
- Слабые стороны статического анализа кода
- Статическое тестирование безопасности приложений (SAST)
- Как выбрать и внедрить статический анализатор кода
- Примеры ошибок, обнаруживаемых статическим анализом кода
- Другие ресурсы
Статический анализ кода — это процесс выявления недочетов, ошибок и потенциальных уязвимостей в исходном коде программ. Статический анализ можно рассматривать как автоматизированный процесс обзора кода.
Обзор кода
Обзор кода (code review) – один из самых старых и полезных методов выявления дефектов. Он заключается в совместном внимательном чтении исходного кода и высказывании рекомендаций по его улучшению. В процессе чтения кода выявляются ошибки или участки кода, которые могут стать ошибочными в будущем. Также считается, что автор кода во время обзора не должен давать объяснений, как работает та или иная часть программы. Алгоритм работы должен быть понятен непосредственно из текста программы и комментариев. Если это условие не выполняется, то код должен быть доработан.
Как правило, обзор кода хорошо работает, так как программисты намного легче замечают ошибки в чужом коде. Более подробно с методикой обзора кода можно познакомиться в замечательной книге Стива Макконнелла «Совершенный код» (Steve McConnell, «Code Complete»).
Статический анализ как автоматизация обзоров кода
Существенный недостаток методологии совместного обзора кода — это крайне высокая стоимость. Необходимо регулярно собирать нескольких программистов для обзора нового кода или повторного обзора кода после внесения рекомендаций. При этом программисты должны регулярно делать перерывы для отдыха. Если пытаться просматривать сразу большие фрагменты кода, то внимание быстро притупляется, и польза от обзора кода быстро сходит на нет.
Получается, что с одной стороны хочется регулярно осуществлять обзор кода. С другой — это слишком дорого. Компромиссным решением являются инструменты статического анализа кода. Они без устали обрабатывают исходные тексты программ и выдают программисту рекомендации обратить повышенное внимание на определенные участки кода. Конечно, программа не заменит полноценного обзора кода, выполняемого коллективом программистов. Однако соотношение польза/цена делает использование статического анализа полезной практикой, применяемой многими компаниями.
Что даёт внедрение статического анализа в процесс разработки?
- Выявление ошибок в программах и «кода с запахом» (например, непереносимый или сложный для понимания код).
- Обнаружение потенциальных уязвимостей.
- Рекомендации по оформлению кода. Некоторые статические анализаторы позволяют проверять, соответствует ли исходный код принятому в компании стандарту оформления кода. Имеется в виду контроль количества отступов в различных конструкциях, использование пробелов/символов табуляции и так далее.
- Подсчет метрик. Метрика программного обеспечения — это мера, позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций.
- Проверка соответствия текста программы определённым стандартам кодирования (MISRA, CWE, SEI CERT, и т.д.).
- Контроль качества кода во времени. Собирая статистику, можно узнать, растёт или уменьшается плотность ошибок со временем. Это позволяет отвечать на вопросы, какие изменения в процессе разработки проекта пошли на пользу, а какие нет.
Есть и другие способы использования инструментов статического анализа кода. Например, статический анализ можно использовать как метод контроля и обучения новых сотрудников, еще недостаточно знакомых с правилами программирования в компании.
Инструменты статического анализа кода
Существует большое количество коммерческих и бесплатных статических анализаторов кода. Большой список статических анализаторов имеется на сайте Wikipedia: List of tools for static code analysis. Список языков, для которых существуют статические анализаторы кода, также достаточно велик (C, C++, C#, Java, Ada, Fortran, Perl, Ruby, …).
Если вам интересно, как анализаторы кода выявляют ошибки, то вы можете познакомиться с их устройством на примере PVS-Studio: Технологии статического анализа кода PVS-Studio.
Сильные стороны статического анализа кода
Как и у любой другой методологии выявления ошибок, у статического анализа есть свои сильные и слабые стороны. Важно понимать, что нет идеального метода тестирования программ. Для разных классов программного обеспечения разные методики будут давать разные результаты. Добиться высокого качества программы можно, только используя сочетание различных методик.
Главное преимущество статического анализ состоит в возможности существенного снижения стоимости устранения дефектов в программе. Чем раньше ошибка выявлена, тем меньше стоимость ее исправления. Так согласно данным, приведенным в книге Макконнелла «Совершенный Код», исправление ошибки на этапе тестирования обойдется в десять раз дороже, чем на этапе конструирования (написания кода):
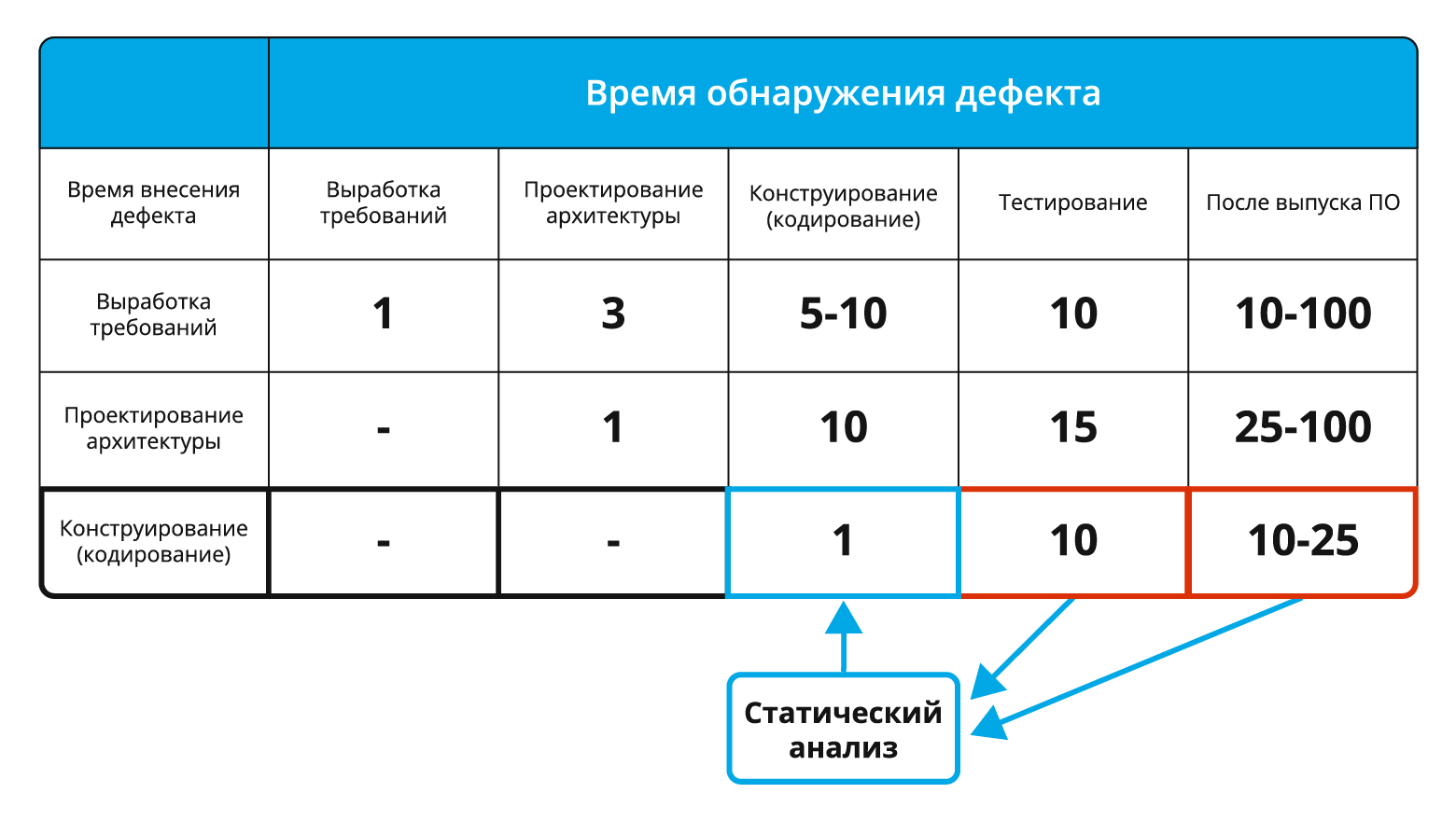
Рисунок 1. Средняя стоимость исправления дефектов в зависимости от времени их внесения и обнаружения (данные для таблицы взяты из книги С. Макконнелла «Совершенный Код»).
Инструменты статического анализа позволяют выявить большое количество ошибок этапа конструирования (написания кода), что существенно снижает стоимость разработки всего проекта. Например, статический анализатор кода PVS-Studio может запускаться в фоновом режиме сразу после компиляции и в случае нахождения потенциальной ошибки уведомит программиста (см. режим инкрементального анализа).
Другие преимущества статического анализа кода:
- Тестирование всего кода. Статические анализаторы проверяют даже те фрагменты кода, которые выполняются крайне редко. Такие участки кода, как правило, не удается протестировать другими методами. Это позволяет находить дефекты в обработчиках редких ситуаций, в обработчиках ошибок или в системе логирования.
- Статический анализ не зависит от используемого компилятора и среды, в которой будет выполняться скомпилированная программа. Это позволяет находить скрытые ошибки, которые могут проявить себя только через несколько лет. Например, это ошибки неопределенного поведения. Такие ошибки могут проявить себя при смене версии компилятора или при использовании других ключей для оптимизации кода. Другой интересный пример скрытых ошибок приводится в статье «Перезаписывать память — зачем?».
- Можно легко и быстро обнаруживать опечатки и последствия использования Copy-Paste. Как правило, нахождение этих ошибок другими способами является крайне неэффективной тратой времени и усилий. Обидно после часа отладки обнаружить, что ошибка заключается в выражении вида «strcmp(A, A)». Обсуждая типовые ошибки, про такие ляпы, как правило, не вспоминают. Но на практике на их выявление тратится существенное время.
Слабые стороны статического анализа кода
- Статический анализ, как правило, слаб в диагностике утечек памяти и параллельных ошибок. Чтобы выявлять подобные ошибки, фактически необходимо виртуально выполнить часть программы. Это крайне сложно реализовать. Также подобные алгоритмы требуют очень много памяти и процессорного времени. Как правило, статические анализаторы ограничиваются диагностикой простых случаев. Более эффективным способом выявления утечек памяти и параллельных ошибок является использование инструментов динамического анализа.
- Программа статического анализа предупреждает о подозрительных местах. Это значит, что на самом деле код может быть совершенно корректен. Это называется ложноположительными срабатываниями. Понять, указывает анализатор на ошибку или выдал ложное срабатывание, может только программист. Необходимость просматривать ложные срабатывания отнимает рабочее время и ослабляет внимание к тем участкам кода, где в действительности содержатся ошибки.
Ошибки, обнаруживаемые статическими анализаторами весьма разнообразны. Вот, например, список диагностик, которые реализованы в инструменте PVS-Studio. Некоторые анализаторы специализируются на определенной области или типах дефектов. Другие, поддерживают определенные стандарты кодирование, например MISRA-C:1998, MISRA-C:2004, Sutter-Alexandrescu Rules, Meyers-Klaus Rules и так далее.
Статическое тестирование безопасности приложений (SAST)
В качестве одной из разновидностей статического анализа можно выделить Static Application Security Testing (SAST). Эти анализаторы ориентированы на выявление потенциальных уязвимостей с целью защитить код приложений от уязвимостей нулевого дня. Другими словами, задача состоит в том, чтобы команда разработчиков сама нашла и устранила дефекты безопасности на этапе написания кода, а не чтобы это позже сделал злоумышленник в своих целях.
Анализатор PVS-Studio также является SAST-решением.
Как выбрать и внедрить статический анализатор кода
Сфера статического анализа активно развивается, появляются новые инструменты, новые стандарты кодирования. В статических анализаторах реализуются новые диагностические правила, некоторые правила устаревают. Разные анализаторы интегрируется с разными IDE, CI, облачными CI и так далее.
В итоге нет возможности всесторонне сравнить статические анализаторы и выбрать «самый лучший». Сложность подтверждается и тем, что в интернете можно найти только поверхностные статьи о сравнении статических анализаторов. Поэтому рационально выбрать и попробовать несколько подходящих под ваши требования: поддержка языков, интеграция с CI/CD, плагины для IDE, поддерживаемые стандарты кодирования и так далее. А затем выбрать тот, который показался вам наиболее удобным и нашёл реальные ошибки в вашем проекте.
Следующий этап: внедрение инструмента в ваш процесс разработки. Про это есть две статьи, в которых хорошо раскрыта эта тема:
- Как внедрить статический анализатор кода в legacy проект и не демотивировать команду.
- Внедряйте статический анализ в процесс, а не ищите с его помощью баги.
Примеры ошибок, обнаруживаемых статическим анализом кода
- Ноль, один, два, Фредди заберёт тебя.
- Зло живёт в функциях сравнения.
- Эффект последней строки.
- Espressif IoT Development Framework: 71 выстрел в ногу.
- Обработка дат притягивает ошибки или 77 дефектов в Qt 6.
- Примеры ошибок, которые может обнаружить PVS-Studio в коде LLVM 15.0.
- Ошибки и подозрительные места в исходниках .NET 6.
Другие ресурсы
- Википедия. «Статический анализ кода».
- Coverity. A Few Billion Lines of Code Later: Using Static Analysis to Find Bugs in the Real World.
- Джон Кармак. Статический Анализ Кода.
- Андрей Карпов. Развитие инструментария С++ программистов: статические анализаторы кода.
- Андрей Карпов, Виктория Ханиева. Использование машинного обучения в статическом анализе исходного кода программ.
- Сергей Васильев. Место SAST в Secure SDLC: 3 причины внедрения в DevSecOps-пайплайн.
Присылаем лучшие статьи раз в месяц
Есть много способов, которые помогут повысить качество программы. В этой статье предлагаю взглянуть на один из них – статический анализ кода.
Содержание
- Кратко о статическом анализе кода
- Инструменты и технологии для статического анализа кода
- Анализ потока данных
- Аннотирование методов
- Сопоставление с шаблоном
- Символьное выполнение
- Статический анализ кода на практике
- Примеры найденных ошибок
- Заключение
Кратко о статическом анализе кода
Как вы, наверное, уже знаете, статические анализаторы позволяют проверять код без запуска самой программы. Последнее время популярность статического анализа при разработке набирает обороты, а рынок статического анализа с каждым годом становится больше. Отчасти это связано с тем, что прошла эра линтеров, которые были основаны только на регулярных выражениях.
Сейчас статический анализ поражает своим разнообразием и возможностями. Даже хайп с AI и машинным обучением не прошел мимо анализаторов, и швейцарцы выпустили продукт, обучающийся на открытых репозиториях. Однако надо понимать, что AI в обозримом будущем не заменит классические технологии, применяемые в статических анализаторах, а пополнит их.
Инструменты и технологии для статического анализа кода
Одним из современных статических анализаторов является инструмент PVS-Studio. Этот инструмент позволяет выявлять ошибки и потенциальные уязвимости в исходном коде программ, написанных на языках С, C++, C# и Java. Работает в 64-битных системах на Windows, Linux и macOS и может анализировать код, предназначенный для 32-битных, 64-битных и встраиваемых ARM платформ. Кратко рассмотрим, какие технологии использует PVS-Studio при анализе исходного кода.
Анализ потока данных
Начнем с анализа потока данных. Он позволяет вычислить возможные значения переменных в разных точках программы. Благодаря Data-Flow Analysis можно находить такие ошибки, как выход за границу массива, утечки памяти, разыменование нулевого указателя и т.д.
Аннотирование методов
Ручное и автоматическое аннотирование методов. Оно предоставляет больше информации об используемых методах, чем может быть получено путём анализа только их сигнатуры.
Сопоставление с шаблоном
Сопоставление с шаблоном. Анализатор, проверяя код, может находить заданные заранее паттерны, типичные для какой-либо ошибки. В простейшем варианте этот поиск похож на поиск ошибок с помощью регулярных выражений, однако всё обстоит несколько сложнее. Для поиска ошибок используется обход и анализ дерева разбора. Почему для этих задач неприемлемо использовать регулярные выражения, можно узнать из статьи «Статический анализ и регулярные выражения».
Символьное выполнение
Символьное выполнение. Оно позволяет находить недочеты в коде, даже не зная, какое значение переменных будет в строке с ошибкой. Небольшой пример, чтобы было нагляднее:
void Foo(int A, int B, int C)
{
if(A<B)
{
if(B<C)
{
if(A>C)
{
....
}
}
}
}
Не зная ничего о значениях переменных A, B и C, анализатор PVS-Studio способен понять, что условие (A > C) всегда ложно, и сообщить об этом разработчику. Подробнее с этим и другими принципами, положенными в основу анализатора, можно познакомиться в статье «Технологии, используемые в анализаторе кода PVS-Studio для поиска ошибок и потенциальных уязвимостей».
Я знаю, о чем подумали некоторые читатели этой статьи. Это все, конечно, классно, но зачем нам статический анализ? Приведу пример из своей жизни. У меня был маленький пет-проект – светодиодные костюмы, которые светятся и моргают под музыку (при нажатии кнопки «плей» в программе на компьютере запускается таймер, который и отправляет на светодиоды значение RGB). Однажды, внеся очередные правки в код, я включила костюм и поняла, что он сходит с ума. Костюм хаотично моргал и светился теми цветами, которые я видеть вообще не ожидала, и больше напоминал кошмар эпилептика, чем светодиодную шмотку. На поиск ошибки у меня ушло, наверное, около часа, я перечитывала свой код немыслимое количество раз, а причина оказалась в банальной опечатке в одной цифре… мда.
К слову, ошибку, которую я допустила, успешно находит статический анализ.
private void saveip6_Click(object sender, RoutedEventArgs e)
{
saveIp(ip6.Text.ToString(), 6);
....
}
private void saveip7_Click(object sender, RoutedEventArgs e)
{
saveIp(ip6.Text.ToString(), 6); // Должно быть 7
....
}
Предупреждение PVS-Studio: V3013 It is odd that the body of ‘saveip6_Click’ function is fully equivalent to the body of ‘saveip7_Click’ function (5254, line 5260). MainWindow.xaml.cs 5254
Тут я методом копипасты писала код, сохраняющий ip-адрес контроллеров костюмов из текстбоксов. И, дабы быть честной, признаюсь, что цифра 6 тут из головы. Я не помню, в каком конкретно обработчике событий так неудачно накопипастила. Ну и не важно, самое главное – передать суть.
Однако у меня была довольно небольшая кодовая база и, следовательно, маленький объем всевозможных ошибок и опечаток. Цифры, взятые из книги Стива Макконнелла «Совершенный код», гласят, что с ростом размера проекта растёт и плотность ошибок.
Именно поэтому инструменты статического анализа все больше набирают популярность среди крупных компаний, занимающихся разработкой.
Заметка! Compiler Explorer использует анализатор PVS-Studio.
Статический анализ кода на практике
Давайте теперь перейдём от теории к практике и на примере посмотрим, какие ошибки можно выявлять с помощью статического анализа кода. Для этого возьмём небольшой реальный открытый проект Extended WPF Toolkit и проверим его с помощью PVS-Studio.
Extended WPF Toolkit – это коллекция элементов управления и компонентов для WPF приложений. Проект включает в себя около 600 файлов исходного кода на языке C# и около 112 тысяч строк. Этот бесплатный набор инструментов имеет открытый исходный код и предоставляется в рамках лицензии Microsoft Public License. Также разработчики уже на платной основе предлагают воспользоваться Toolkit Plus Edition и Business Suite, в которых еще больше разнообразных компонентов и элементов управления, несколько тем под Metro и Windows 10 и многое другое.
Впрочем, все эти подробности нам не очень важны. Главное, что это обыкновенный типовой проект, написанный на языке C#. Давайте рассмотрим некоторые из ошибок, который в нём были найдены. Надеюсь, приведённых примеров будет достаточно для получения общего представления о технологии анализа кода. Более полное впечатление вы сможете составить самостоятельно, скачав и запустив анализатор на своих проектах. См. также «Как быстро посмотреть интересные предупреждения, которые выдает анализатор PVS-Studio для C и C++ кода?».
Примеры найденных ошибок
Предупреждение PVS-Studio: V3006 The object was created but it is not being used. The ‘throw’ keyword could be missing: throw new InvalidOperationException(FOO). DockingManager.cs 1129
internal void InternalAddLogicalChild( object element )
{
....
if(_logicalChildren.Select(ch => ch.GetValueOrDefault<object>())
.Contains( element ) )
new InvalidOperationException();
....
}
Это предупреждение анализатора сообщает о том, что был создан экземпляр класса InvalidOperationException, который в коде не используется. Видимо, программист хотел, чтобы при выполнении условия генерировалось исключение, но забыл написать оператор throw, который бы это исключение вызывал.
Предупреждение PVS-Studio: V3083 Unsafe invocation of event ‘PropertyChanged’, NullReferenceException is possible. Consider assigning event to a local variable before invoking it. CheckListsView.xaml.cs 124
public event PropertyChangedEventHandler PropertyChanged;
protected void OnPropertyChanged( string propertyName )
{
if( PropertyChanged != null )
{
PropertyChanged( this, new PropertyChangedEventArgs( propertyName ) );
PropertyChanged( this, new PropertyChangedEventArgs( "ModelDisplay" ) );
}
}
Анализатор предупреждает о том, что был создан потенциально небезопасный вызов обработчика события. Проблема этого кода заключается в том, что одной проверки на null в этом случае недостаточно. В многопоточном приложении между проверкой на null и кодом в then-ветви оператора if может выполниться код в другом потоке, выполняющий отписку от данного события. Если это произойдет, и подписчиков у события не останется, то такой случай приведет к возникновению исключения NullReferenceException.
Для того, чтобы гарантированно произошло безошибочное выполнение вызова события, есть несколько способов переписать этот код. Я приведу один пример, а разработчики сами решат – воспользоваться моим способом, найти другой, и стоит ли вообще с этим кодом что-то делать.
protected void OnPropertyChanged( string propertyName )
{
PropertyChangedEventHandler eventHandler = PropertyChanged;
if( eventHandler != null )
{
eventHandler( this, new PropertyChangedEventArgs( propertyName ) );
eventHandler( this, new PropertyChangedEventArgs( "ModelDisplay" ) );
}
}
В этом примере мы сохраняем ссылку на обработчик события в переменную eventHandler. Теперь, даже если произойдет отписка от события и подписчиков не останется, переменная eventHandler всё равно будет содержать ссылку на первоначальный обработчик и код выполнится корректно.
Подобные проблемы в коде встретились более 30 раз. Все подобные предупреждения в рамках этой статьи смотреть будет скучно, поэтому предлагаю автору проекта самостоятельно попробовать их найти и исправить.
Предупреждение PVS-Studio: V3117 Constructor parameter ‘ignore’ is not used. AnimationRate.cs 59
private AnimationRate( bool ignore )
{
_duration = 0;
_speed = double.NaN;
_rateType = RateType.Speed;
}
Это предупреждение говорит о том, что параметр ignore не используется в этом коде. Судя по названию параметра, это ложное срабатывание и вскоре ‘ignore’ уберут из этого кода. Если это так, то предлагаю использовать атрибут ‘Obsolete’, который используется как раз в таких случаях.
[Obsolete("убрать параметр ignore")]
private AnimationRate( bool ignore )
{
_duration = 0;
_speed = double.NaN;
_rateType = RateType.Speed;
}
Предупреждение PVS-Studio: V3114 IDisposable object ‘reader’ is not disposed before method returns. CSharpFormat.cs 211
protected override string MatchEval( ....) //protected override
{
if( match.Groups[ 1 ].Success ) //comment
{
StringReader reader = new StringReader( match.ToString() );
....
}
}
Анализатор указывает на то, что объект reader класса StringReader реализует интерфейс ‘IDisposable’, но метод Dispose() для этого объекта в коде не был вызван. Тут, на самом деле, возникла двоякая ситуация. Класс StringReader и правда реализует данный интерфейс, но он его унаследовал от базового класса и никакими ресурсами он не владеет, поэтому вызывать Dispose() в этом случае не обязательно.
Предупреждение PVS-Studio: V3030 Recurring check. The ‘Layout.ActiveContent != null’ condition was already verified in line 2319. DockingManager.cs 2327
private void OnLayoutRootPropertyChanged( object sender,
PropertyChangedEventArgs e )
{
....
else if( e.PropertyName == "ActiveContent" )
{
if( Layout.ActiveContent != null )
{
//set focus on active element only after a layout pass is
//completed
//it's possible that it is not yet visible in the visual tree
//if (_setFocusAsyncOperation == null)
//{
// _setFocusAsyncOperation = Dispatcher.BeginInvoke(
// new Action(() =>
// {
if( Layout.ActiveContent != null )
FocusElementManager.SetFocusOnLastElement(
Layout.ActiveContent);
//_setFocusAsyncOperation = null;
// } ), DispatcherPriority.Input );
//}
}
....
}
}
Анализатор обращает внимание на то, что в двух условиях подряд проверяется одно и то же значение на null. Возможно, проверка избыточна, но так же есть и вероятность, что второе условие должно выглядеть иначе. Сложилось впечатление, что этот код просто не дописан.
Предупреждение PVS—Studio:
V3084 Anonymous function is used to unsubscribe from ‘HeaderDragDelta’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 355
V3084 Anonymous function is used to unsubscribe from ‘HeaderIconDoubleClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 356
V3084 Anonymous function is used to unsubscribe from ‘CloseButtonClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 357
public override void OnApplyTemplate()
{
....
if( _windowControl != null )
{
_windowControl.HeaderDragDelta
-= ( o, e ) =>
this.OnHeaderDragDelta( e );
_windowControl.HeaderIconDoubleClicked
-= ( o, e ) =>
this.OnHeaderIconDoubleClick( e );
_windowControl.CloseButtonClicked
-= ( o, e ) =>
this.OnCloseButtonClicked( e );
}
....
if( _windowControl != null )
{
_windowControl.HeaderDragDelta
+= ( o, e ) =>
this.OnHeaderDragDelta( e );
_windowControl.HeaderIconDoubleClicked
+= ( o, e ) =>
this.OnHeaderIconDoubleClick( e );
_windowControl.CloseButtonClicked
+= ( o, e ) =>
this.OnCloseButtonClicked( e );
}
....
}
В этом коде _windowControl отписывается от события, а потом подписывается обратно. Проблема кроется в том, каким образом происходят манипуляции с событиями при помощи лямбда-выражений. Дело в том, что каждое объявление анонимной функции приводит к созданию отдельного экземпляра делегата. Корректный вариант использования анонимных функций при подписке с дальнейшей отпиской на события представляет собой создание и использование переменной, в которую сохранен обработчик-лямбда, например, так:
_event = (o, e) => this.OnHeaderDragDelta (o, e);
Подобные предупреждения анализатора:
- V3084 Anonymous function is used to unsubscribe from ‘Loaded’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. ChildWindow.cs 644
- V3084 Anonymous function is used to unsubscribe from ‘HeaderDragDelta’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 327
- V3084 Anonymous function is used to unsubscribe from ‘HeaderIconDoubleClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 328
- V3084 Anonymous function is used to unsubscribe from ‘CloseButtonClicked’ event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration. MessageBox.cs 329
Предупреждение PVS-Studio: V3013 It is odd that the body of ‘OnMaxScaleChanged’ function is fully equivalent to the body of ‘OnMinScaleChanged’ function (656, line 695). Zoombox.cs 656
private static void OnMinScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
Zoombox zoombox = ( Zoombox )o;
zoombox.CoerceValue( Zoombox.MinScaleProperty );
zoombox.CoerceValue( Zoombox.ScaleProperty );
}
private static void OnMaxScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
Zoombox zoombox = ( Zoombox )o;
zoombox.CoerceValue( Zoombox.MinScaleProperty );
zoombox.CoerceValue( Zoombox.ScaleProperty );
}
В этом коде анализатор нашел две функции OnMinScaleChanged и OnMaxScaleChanged, реализованные идентичным образом. При этом в коде было создано свойство зависимости с именем MaxScaleProperty. Есть подозрения, что во втором случае код должен выглядеть так:
private static void OnMaxScaleChanged( DependencyObject o,
DependencyPropertyChangedEventArgs e )
{
....
zoombox.CoerceValue( Zoombox.MaxScaleProperty );
....
}
Подобные сообщения анализатора:
- V3013 It is odd that the body of ‘OnCoerceLeft’ function is fully equivalent to the body of ‘OnCoerceTop’ function (299, line 355). WindowControl.cs 299
- V3013 It is odd that the body of ‘OnMouseLeftButtonDown’ function is fully equivalent to the body of ‘OnMouseRightButtonDown’ function (156, line 162). LayoutDocumentControl.cs 156
Предупреждение PVS-Studio: V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions ‘newValue != null’ and ‘newValue == null’. Selector.cs 181
public IList SelectedItems
{
....
private set
{
....
{
....
{
if(((newValue != null) &&
!newValue.Contains(item)) ||
(newValue == null))
{
....
}
}
}
....
}
Данный код является избыточным и его нужно упростить, о чем и сообщает анализатор. Все дело в том, что слева и справа от оператора ‘||’ стоят выражения (newValue != null) и (newValue == null). На первый взгляд кажется, что при упрощении пострадает логика программы, ведь в первом подвыражении проверяется не только наличие какого-либо значения у переменной newValue, но еще и item. Однако если написать так, то не только не пострадает работоспособность программы, но и улучшится читабельность кода:
if (newValue == null || !newValue.Contains(item))
Подобные ошибки, найденные анализатором:
- V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions ‘oldValue != null’ and ‘oldValue == null’. Selector.cs 198
- V3031 An excessive check can be simplified. The ‘||’ operator is surrounded by opposite expressions. cs 85
Предупреждение PVS-Studio: V3051 An excessive type cast. The object is already of the ‘Magnifier’ type. MagnifierManager.cs 62
private void Element_MouseLeave( object sender, MouseEventArgs e )
{
var magnifier = MagnifierManager.GetMagnifier( _element ) as Magnifier;
....
}
public static Magnifier GetMagnifier( UIElement element )
{
return ( Magnifier )element.GetValue( CurrentProperty );
}
Анализатор указывает на то, что программист привел объект к своему же типу. Данная проверка является избыточной. Это не является ошибкой и можно оставить ключевое слово var в объявлении magnifier, но нагляднее будет явно указать тип переменной.
Обычно после описания ошибки идет перечисление всех мест, где попадался подобный ошибочный код, но в этом случае выписать все предупреждения не получится. В коде попалось более 50 (!) подобных предупреждений анализатора (не считая того, что могло попасть на уровень Low, который я смотрела не так внимательно, как остальные), что на мой взгляд чересчур много.
Предупреждение PVS-Studio: V3116 Consider inspecting the ‘for’ operator. It’s possible that the loop will be executed incorrectly or won’t be executed at all. CollectionControl.cs 642
internal void PersistChanges( IList sourceList )
{
....
{
....
{
{
var list = (IList)collection;
list.Clear();
if( list.IsFixedSize )
{
if( sourceList.Count > list.Count )
throw new IndexOutOfRangeException(....);
for(int i = 0; i < sourceList.Count; ++i ) // <=
list[ i ] = sourceList[ i ];
}
....
}
....
}
....
}
Код в цикле for не выполнится ни разу по следующим причинам: сначала программа очищает list, потом сравнивает размер sourceList и list (генерируя исключение, если количество элементов в sourceList больше чем в пустом list), а далее пытается заполнить список list значениями из sourceList через цикл.
Предупреждение PVS-Studio: V3020 An unconditional ‘break’ within a loop. LayoutRoot.cs 542
public void CollectGarbage()
{
bool exitFlag = true;
....
do
{
exitFlag = true;
....
foreach( .... )
{
....
while( singleChild.ChildrenCount > 0 )
{
....
}
exitFlag = false;
break;
}
}
while( !exitFlag );
....
}
Вне зависимости от значения singleChild.ChildrenCount, из-за оператора break выполняется ровно одна итерация цикла foreach. Да и вообще код очень странный, непонятно, стоит ли это расценивать как ошибку, вдруг это так и было задумано…
Заключение
На примере проекта Extended WPF Toolkit мы убедились в значимости статического анализа при создании программного продукта. WPF Toolkit представляет собой совсем небольшой проект, однако на 112 тысяч строк кода попалось довольно много однотипных ошибок, вроде идентично реализованных методов, приведения объектов к своему же типу и т.д. Все эти ошибки легко находятся при помощи статического анализатора кода PVS-Studio, которым можно воспользоваться, скачав пробную версию по ссылке. Если ввести промокод #infocomp в поле «Сообщение», то можно получить лицензию на один месяц вместо 7 дней.
Автор: Екатерина Никифорова
Сейчас все больше говорят о статическом анализе для поиска уязвимостей как необходимом этапе разработки. Однако многие говорят и о проблемах статического анализа. Об этом много говорили на прошлом Positive Hack Days, и по итогам этих дискуссий мы уже писали о том , как устроен статический анализатор. Если вы пробовали какой-нибудь серьезный инструмент, вас могли отпугнуть длинные отчеты с запутанными рекомендациями, сложности настройки инструмента и ложные срабатывания. Так все-таки нужен ли статический анализ?
Наш опыт подсказывает, что нужен. И многие проблемы, которые возникают при первом взгляде на инструмент, вполне можно решить. Попробую рассказать, что может делать пользователь и каким должен быть анализатор, чтобы его использование было полезным, а не вносило «еще один ненужный инструмент, который требуют безопасники».

Про статический анализ
Итак, мы уже говорили о теоретических ограничениях статического анализа. Например, глубокий статический анализ пытается решить экспоненциальные по сложности задачи. Поэтому каждый инструмент ищет компромисс между временем работы, затрачиваемыми ресурсами, количеством найденных уязвимостей и количеством ложных срабатываний.
Зачем вообще нужен глубокий анализ? Любая IDE очень быстро находит ошибки, иногда даже связанные с безопасностью – какие вообще экспоненциальные задачи? Классический пример – SQL-инъекция (да и любая другая инъекция, типа XSS, RCE и подобного), которая проходит через несколько функций (то есть чтение данных от пользователя и выполнение запроса происходят в разных функциях). Для ее поиска нужен межпроцедурный анализ потока данных, а это задача экспоненциальной сложности. Согласитесь, без поиска таких уязвимостей анализ не может считаться глубоким. По этой же причине анализировать нужно код целиком, а не частями – иначе можно упустить межпроцедурные уязвимости.
В последние годы я получил немало опыта общения с (потенциальными) заказчиками разных статических анализаторов. В том числе мы обсуждаем претензии к инструментам по результатам первого использования (пилота). Большинство претензий так или иначе следуют из теоретических ограничений технологии. Помимо этого, инструменты могут просто не иметь нужного пользователю функционала. Однако, по моему мнению, анализаторы могут двигаться (и двигаются) в сторону пользователя в плане решения обозначенных дальше проблем. Но и нужно уметь пользоваться анализаторами, нивелируя последствия этих же проблем – как оказывается, это не так сложно. Давайте по порядку.
Можно представить модельную ситуацию: вы решили попробовать технологию в действии или выбираете статический анализатор – проводите пилот. Конечно, вы не доверяете тестовым примерам вендора и хотите попробовать проанализировать свой код (заодно можно найти реальные уязвимости и исправить их). Вам предоставляют инсталлятор или готовую виртуальную машину с системой на небольшой срок.
Запуск анализа
Сперва надо запустить анализ. Вы заходите в интерфейс, и, вроде бы, все должно быть понятно: загружаем в форму архив с исходным кодом и нажимаем «анализировать». Но нет: вы получаете несколько форм с разными полями, которые нужно как-то заполнить. Надо указать языки программирования, какие-то настройки анализатора, выбрать пакеты уязвимостей (откуда вы знаете, что в них входит?) и так далее. Вы проходите это испытание, и анализ начинается. А, нет – ошибка сканирования. «Формат не соответствует требованиям», «Для данного языка требуется сборка кода», «Не найдено файлов для сканирования»… Если вы не сами писали этот код, надо будет еще идти за помощью к разработчикам.

Разработчик сдает исходный код на тестирование
Отдельного внимания заслуживают требования к сборке кода. Большинство анализаторов для ряда языков требуют, чтобы код собирался во время анализа (JVM-языки — Java, Scala, Kotlin и тому подобные, C/C++, Objective-C, C#). Сами понимаете, какая это боль: воспроизвести окружение большого проекта для сборки на новой машине. С другой стороны, эти требования оправданы, они следуют из технологии анализа и специфики данных языков.
Как решают эти проблемы анализаторы? Во-первых, делают запуск анализа максимально автоматизированным. В идеале, достаточно загрузить файл любого формата, и анализатор сам должен понять, какие там языки, как попробовать провести сборку и как проставить по умолчанию остальные настройки, чтобы результаты были максимально полными. Понятно, что нельзя предусмотреть все – однако можно постараться обрабатывать большую часть случаев.
Требования к сборке нужно делать максимально мягкими. Например, для JVM-языков не нужно требовать сборки во время анализа – достаточно просить подгружать артефакты, то есть собранный код вместе с исходниками (а это существенно проще). Для XCode в случае Objective-C сборку можно автоматизировать для большинства случаев. Если не получилось собрать код, анализатор может попробовать провести частичный анализ. Его результаты будут не настолько полными, но это лучше, чем никаких результатов вообще. Также удобно, если модуль анализа можно поставить на машину к разработчику, где сборка кода уже настроена, при этом архитектура должна позволять вынести остальные модули и интерфейсную часть на другую машину.
Наконец, анализатор должен выдвигать максимально мягкие требования к формату и сам разбираться со входными файлами. Архив с исходным кодом, вложенные архивы, архив из репозитория, ссылка на репозиторий, архив с продуктива, исполняемый файл с продуктива – хорошо, если все это анализатор поддерживает.
Однако не стоит забывать, что анализатор не обладает искусственным интеллектом и всего предусмотреть не может. Поэтому при возникновении ошибок стоит ознакомиться с мануалом – там бывает много полезного по подготовке кода для анализа. Ну, и вся эта работа по запуску сканирования при внедрении анализатора проделывается только один раз для каждой кодовой базы. Чаще всего анализатор вообще встраивается в цикл CI, то есть проблем со сборкой не будет.
Процесс анализа
Ладно, сканирование запустили. Проходит час – результатов нет. Прогресс бар висит где-то посередине, непонятно с каким процентом и каким прогнозом по завершению. Проходит второй час – прогресс сдвинулся на 99 процентов и висит там уже полчаса. Проходит третий час – и анализатор падает, сообщая о нехватке оперативной памяти. Или висит еще час и завершается. Вы могли ожидать, что анализ пройдет с той же скоростью, как ваш checkstyle, и тут ожидания сильно разойдутся с реальностью.

Да, хороший статический анализатор может потреблять немало ресурсов, одну из причин выше я указал: нахождение сложных уязвимостей – экспоненциально сложная задача. Так что чем больше будет ресурсов и чем больше времени, тем качественнее будут результаты (при хорошем движке, конечно). И время анализа, и требуемые ресурсы предсказать действительно трудно – время работы алгоритмов статического анализа сильно зависит от языковых конструкций, от сложности кода, от глубины вызовов – от характеристик, которые сложно заранее просчитать.
Проблема с ресурсами – необходимое зло. Нужно внимательно относиться к выделению необходимых ресурсов, терпеливо ждать окончания сканирования, а также понимать, что точно спрогнозировать необходимые для анализатора ресурсы, даже при заданной кодовой базе, никто не сможет, и надо быть готовым к изменению этих параметров. Более того, требуемые параметры могут измениться даже без обновления кодовой базы – из-за обновления анализатора.
Все же и с этой проблемой анализатор может немного помочь. Он способен разделять по разным машинам ресурсоемкую часть (движки) и интерфейс. Это позволит не загружать машины лишними программами, которые будут тормозить их работу, при этом можно будет пользоваться интерфейсом системы при любой загруженности по сканированиям (например, для просмотра и редактирования результатов). Еще это позволит легко масштабироваться без переустановок всей системы (поднимаем анализатор на новой виртуалке, указываем IP основной машины – и вуаля).
Помимо этого, анализатор может разрешать выбирать глубину анализа, отключать тяжеловесные проверки, использовать инкрементальный анализ (при котором проверяется не весь код, а только изменившийся). Этими вещами нужно пользоваться очень аккуратно, так как они могут сильно влиять на результаты сканирования. Если вы пользуетесь такой функциональностью, рекомендуется с некоторой периодичностью проводить полный анализ.
Результаты анализа
Перейдем к результатам сканирования (долго же мы до них шли). Вы с трепетом ждете количества уязвимостей в окошке анализатора, и очень удивляетесь, увидев его. 156 критических, 1260 среднего и 3210 низкого уровня. Вы заходите на страницу с результатами и утопаете в количестве найденных проблем. Вы выгружаете pdf-отчет – и видите несколько тысяч страниц текста. Угадайте, что скажет разработчик кода, увидев такое полотно?

Безопасник везет разработчику отчет об уязвимостях
Но давайте все-таки попробуем посмотреть результаты, дадим ему шанс. Изучив повнимательнее несколько десятков вхождений, вы начинаете понимать, почему уязвимостей так много. Несколько уязвимости и правда выглядят серьезными, вы понимаете, что их нужно исправлять. Однако сходу вы находите с десяток ложных. А еще – огромное количество уязвимостей в коде библиотек. Не будете же вы исправлять библиотеки! И тут вы понимаете, сколько времени вы потратите на разбор результатов. И эту процедуру надо повторять каждую день, неделю, ну или как минимум каждый релиз. (На самом деле нет).
Начнем с того, что ложность срабатывания можно понимать очень по-разному. Кто-то не будет считать ложными только критические уязвимости, которые можно эксплуатировать прямо сейчас. Кто-то будет считать ложными только откровенные ошибки анализатора. Многое зависит от того, чего вы хотите от инструмента. Мы рекомендуем рассматривать практически все вхождения, так как даже уязвимость низкого уровня, которую сейчас нельзя проэксплуатировать, завтра может обернуться серьезной проблемой – например, при изменениях кода и внешних условий.
Ок, смотреть надо все вхождения, но это все еще огромный объем работы. И вот здесь анализаторы могут помочь очень хорошо. Важнейшая функция анализатора – это умение отслеживать уязвимости между сканированиями одного проекта, при этом отслеживать устойчиво к небольшим изменениям, стандартным для разработки кода. Это снимает проблему того, что длительный разбор уязвимостей нужно повторять: в первый раз вы потратите больше времени, удаляя ложные срабатывания и меняя критичность вхождений, однако далее вам нужно будет просматривать только новые уязвимости, которых будет в разы меньше.
Хорошо, но нужно ли в первый раз просматривать все уязвимости? Мы рекомендуем это делать, но, вообще говоря, это необязательно. Во-первых, анализаторы позволяют фильтровать результаты по директориям и файлам: например, при запуске сканирования вы можете сразу исключить из анализа какие-то компоненты, библиотеки, тестовый код. Это повлияет и на скорость анализа. Во-вторых, анализаторы позволяют фильтровать результаты по уязвимостям, то есть при старте сканирования можно ограничить набор уязвимостей. Наконец, помимо критичности анализатор может выдавать что-то вроде вероятности ложности уязвимости (то есть свою уверенность в данной уязвимости). Используя эту метрику, можно фильтровать результаты.
Отдельно стоит отметить технологию Software Composition Analysis (ее сейчас начинает поддерживать все большее количество инструментов на разном уровне). Технология позволяет обнаруживать использование библиотек в вашем коде, определять названия и версии, показывать известные уязвимости, а также лицензии. Эта технология может отделить библиотечный код от вашего собственного, что также позволит фильтровать результаты.
Получается, с проблемой обильных результатов анализа бороться можно, и это не очень сложно. И хотя первый просмотр результатов действительно может занять время, далее при пересканировании его будет тратиться все меньше. Однако еще раз отмечу, что к любой фильтрации результатов надо относиться осторожно – вы можете пропустить уязвимость. Даже если библиотека является известной, не значит, что в ней нет уязвимости. Если сейчас данная уязвимость обнаруживается плохо (то есть инструмент показывает много ложных срабатываний этой уязвимости), и вы ее отключаете, при обновлении анализатора вы можете пропустить уже настоящую уязвимость.
Проверим анализатор
Разобрались с большим отчетом и ложными срабатываниями. Но вы хотите пойти дальше – убедиться, что анализатор находит те уязвимости, о наличии которых вы точно знаете (вы могли их заложить намеренно, или их нашел другой инструмент).

Для начала важно понимать, что анализатор мог не найти уязвимость по разным причинам. Самое простое – сканирование было неверно сконфигурировано (нужно обращать внимание на сообщения об ошибках). Но и с точки зрения технологии анализа причины могут быть разные. Статический анализатор состоит из двух важных компонентов: движок (в нем кроется вся алгоритмическая сложность и математика) и база правил поиска уязвимостей. Одна ситуация, когда движок позволяет находить уязвимость такого класса, но в базе правил уязвимости нет. В таком случае добавить правило обычно не составляет труда. Совсем другая ситуация, если движок в принципе не поддерживает такие уязвимость – тут доработка может быть очень существенной. Пример я приводил в начале статьи: SQL-инъекцию никогда не найдешь без алгоритмов анализа потока данных.
Статический анализатор должен реализовывать в движке набор алгоритмов, покрывающий доступные классы уязвимостей для данного языка программирования (анализ потока управления, потока данных, интервальный анализ и т.п.). Важным моментом является возможность добавлять в инструмент свои правила поиска уязвимостей – это позволит устранить первую причину пропуска уязвимости.
Таким образом, если вы не нашли имеющуюся уязвимость в результатах сканирования, для начала нужно разобраться в причине пропуска – обычно с этим может помочь вендор. Если причина в базе правил или в конфигурации сканирования, то ситуацию можно достаточно легко устранить. Важнее всего – оценить глубину анализа, то есть то, что в принципе позволяет искать движок.
Компетенции
Прочитав статью до этого места, можно предположить, что для работы с инструментом нужна глубокая экспертиза разработчика, ведь нужно понимать, какие срабатывания ложные, а какие истинные. По моему мнению, все зависит от того, насколько дружественно себя ведет инструмент. Если он предоставляет удобный и понятный функционал, понятные описания уязвимостей с примерами, ссылками и рекомендациями на разных языках, если инструмент показывает трассы для уязвимостей, связанных с анализом потока данных – для работы с ним не потребуется глубокая экспертиза разработчика с пониманием всех тонкостей языка программирования и фреймворков. Однако минимальный бэкграунд в разработке для того, чтобы читать код, все-таки должен быть.
Интеграция в процесс разработки
В конце статьи кратко коснемся одного из самых важных вопросов использования инструмента, а подробно его рассмотрим в следующих статьях. Допустим, вы решили использовать статический анализатор. Однако у вас есть налаженный процесс разработки, как технологический, так и организационный, и его менять не хочется (да никто и не даст).
Инструмент должен иметь полноценный неграфический интерфейс (например, CLI или REST API), с помощью которого вы сможете встроить анализатор в любой свой процесс. Хорошо, если у анализатора есть готовые интеграции с различными компонентами: плагины для IDE или систем сборки, интеграции с системами контроля версий, плагины для CI/CD серверов (Jenkins, TeamCity), интеграции с системами управления проектами (JIRA) или работы с пользователями (Active Directory).
Интеграция статического анализа в процесс разработки (так называемый SDLC) – наиболее эффективный способ использования, если процесс хорошо налажен и все участники договорились и знают, зачем это нужно. Постоянный анализ кода после его изменений или обновлений анализатора позволит находить уязвимости как можно раньше. Разделение ролей разработчиков и специалистов ИБ, четкое указание требований ИБ и мягкая интеграция в текущий процесс (например, в первое время – рекомендательный характер системы) позволит использовать инструмент безболезненно и полезно. Однако никто не отменял и ручное использование инструмента, если ваша модель разработки не подразумевает подобного процесса.
Резюме
В статье собраны основные рекомендации по началу использования статического анализатора. Хороший анализатор работает на порядок лучше любого легковесного чекера, он ищет проблемы принципиально другой сложности. Поэтому нужно считаться с особенностями статического анализа как технологии, но при этом выбирать конкретный инструмент так, чтобы его функционал максимально сглаживал все такие особенности.
Что, если твоя защита — это главная СЛАБОСТЬ? Подпишись на наш ТГ канал и стань супергероем цифрового мира.