In linguistics, according to J. Richard et al., (2002), an error is the use of a word, speech act or grammatical items in such a way that it seems imperfect and significant of an incomplete learning (184). It is considered by Norrish (1983, p. 7) as a systematic deviation which happens when a learner has not learnt something, and consistently gets it wrong. However, the attempts made to put the error into context have always gone hand in hand with either [language learning and second-language acquisition] processe, Hendrickson (1987:357) mentioned that errors are ‘signals’ that indicate an actual learning process taking place and that the learner has not yet mastered or shown a well-structured [linguistic competence|competence] in the target language.
All the definitions seeme to stress either on the systematic deviations triggered in the language learning process, or its indications of the actual situation of the language learner themselves, which will later help monitoring, be it an applied linguist or particularly the language teacher to solve the problem, respecting one of the approaches argued in the Error Analysis (Anefnaf 2017). The occurrence of errors doesn’t only indicate that the learner has not learned something yet, but also it gives the linguist the idea of whether the teaching method applied was effective or it needs to be changed.
According to Corder (1976), errors signify three things: first to the teacher, in that the learner tells the teacher, if they have undertaken a systematic analysis, how far towards that goal the learner has progressed and, consequently, what remains for them to learn; second, they provide the researcher with evidence of how language is learned or acquired, and what strategies or procedures the learner is employing in their discovery of the language; third, (and in a sense this is their most important aspect) they are indispensable to the learner himself/herself, because the making of errors can be regarded as a device the learner uses in order to learn (p. 167). The occurrence of errors is merely a sign of ‘the present inadequacy of our teaching methods’(Corder 1976, p. 163).
There have been two schools of thought when it comes to error analysis and philosophy; the first one, according to Corder (1967) linked the error commitment with the teaching method, arguing that if the teaching method was adequate, the errors would not be committed; the second, believed that we live in an imperfect world and that error correction is something real and the applied linguist cannot do without it no matter what teaching approach they may use.
Errors vs. mistakes[edit]
Chomsky (1965) made a distinguishing explanation of competence and performance on which, later on, the identification of mistakes and errors will be possible, Chomsky stated that ‘’We thus make a fundamental distinction between competence (the speaker-hearer’s knowledge of his language) and performance (the actual use of language in concrete situations)’’ ( 1956, p. 4). In other words, errors are thought of as indications of an incomplete learning, and that the speaker or hearer has not yet accumulated a satisfied language knowledge which can enable them to avoid linguistics misuse. Relating knowledge with competence was significant enough to represent that the competence of the speaker is judged by means of errors that concern the amount of linguistic data they have been exposed to, however, performance which is the actual use of language does not represent the language knowledge that the speaker has. According to J. Richard et al (2002), people may have the competence to produce an infinitely long sentence but when they actually attempt to use this knowledge (to “perform”) there are many reasons why they restrict the number of adjectives, adverbs, and clauses in any one sentence (2002, 392).
The actual state of the speaker somehow involves and influences the speaker’s performance by either causing a good performance or mistakes. Thus, it is quite obvious that there is some kind of interrelationship between competence and performance; somehow, a speaker can perform well if they have had already satisfied linguistic knowledge. As a support to this, Corder (1967) mentioned that mistakes are of no significance to “the process of language learning’’ (P. 167).
Error analysis approach[edit]
Before the rise of error analysis approach, contrastive analysis had been the dominant approach used in dealing and conceptualizing the learners’ errors in the 1950s, this approach had often gone hand in hand with concept of L1 Interference and precisely the interlingual effect (Anefnaf Z. 2017), it claimed that the main cause of committing errors in the process of second language learning is the L1, in other words, the linguistic background of the language learners badly affects the production in the target language or second language.
X. Fang and J. Xue-mei (2007) pointed out that contrastive analysis hypothesis claimed that the principal barrier to second language acquisition is the interference of the first language system with the second language system and that a scientific, structural comparison of the two languages in question would enable people to predict and describe which are problems and which are not. Error analysis approach overwhelmed and announced the decline of the Contrastive Analysis which was only effective in phonology; and, according to J. Richard et al. (2002), EA developed as a branch of Linguistics in the 1960s and it came to light to argue that the mother tongue was not the main and the only source of the errors committed by the learners. In addition, Hashim, A. (1999) mentioned that the language effect is more complex and these errors can be caused even by the target language itself and by the applied communicative strategies as well as the type and quality of the second language instructions.
The aim of EA according to J. Richard et al. (2002) is, first, to identify strategies which learners use in language learning, in terms of the approaches and strategies used in both of teaching and learning. Second, to try to identify the causes of learners’ errors, that is, investigating the motives behind committing such errors as the first attempt to eradicate them. Third, to obtain information on common difficulties in Language Learning, as an aid to teaching or in the preparation of the teaching materials,
The two major causes of error, coined by the error analysis approach, are the Interlingual error which is an error made by the Learner’s Linguistic background and Native language interference, and the Intralingual error which is the error committed by the learners when they misuse some Target Language rules, considering that the error cause lies within and between the target language itself and the Learners false application of certain target language rules.
Error analysis in SLA was established in the 1960s by Corder and colleagues.[1] Error analysis (EA) was an alternative to contrastive analysis, an approach influenced by behaviorism through which applied linguists sought to use the formal distinctions between the learners’ first and second languages to predict errors. Error analysis showed that contrastive analysis was unable to predict a great majority of errors, although its more valuable aspects have been incorporated into the study of language transfer. A key finding of error analysis has been that many learner errors are produced by learners making faulty inferences about the rules of the new language.
Error analysts distinguish between errors, which are systematic, and mistakes, which are not. They often seek to develop a typology of errors. Error can be classified according to basic type: omissive, additive, substitutive or related to word order. They can be classified by how apparent they are: overt errors such as «I angry» are obvious even out of context, whereas covert errors are evident only in context. Closely related to this is the classification according to domain, the breadth of context which the analyst must examine, and extent, the breadth of the utterance which must be changed in order to fix the error. Errors may also be classified according to the level of language: phonological errors, vocabulary or lexical errors, syntactic errors, and so on. They may be assessed according to the degree to which they interfere with communication: global errors make an utterance difficult to understand, while local errors do not. In the above example, «I angry» would be a local error, since the meaning is apparent.
From the beginning, error analysis was beset with methodological problems. In particular, the above typologies are problematic: from linguistic data alone, it is often impossible to reliably determine what kind of error a learner is making. Also, error analysis can deal effectively only with learner production (speaking and writing) and not with learner reception (listening and reading). Furthermore, it cannot account for learner use of communicative strategies such as avoidance, in which learners simply do not use a form with which they are uncomfortable. For these reasons, although error analysis is still used to investigate specific questions in SLA, the quest for an overarching theory of learner errors has largely been abandoned. In the mid-1970s, Corder and others moved on to a more wide-ranging approach to learner language, known as interlanguage.
Error analysis is closely related to the study of error treatment in language teaching. Today, the study of errors is particularly relevant for focus on form teaching methodology.
In second language acquisition, error analysis studies the types and causes of language errors. Errors are classified[2] according to:
- modality (i.e., level of proficiency in speaking, writing, reading, listening)
- linguistic levels (i.e., pronunciation, grammar, vocabulary, style)
- form (e.g., omission, insertion, substitution)
- type (systematic errors/errors in competence vs. occasional errors/errors in performance)
- cause (e.g., interference, interlanguage)
- norm vs. system
Types of errors[edit]
Linguists have always been attempting to describe the types of errors committed by the language learners, and that is exactly the best way to start with, as it helps out the applied linguist to identify where the problem lies. According to Dulay et al. (1982) errors take place when the learner change the surface structure in a particularly systematic manner (p. 150), thus, the error, no matter what form and type it is, represent a damage at the level of the target language production.
Errors have been classified by J. Richard et al. (2002) into two categories. The Interlingual Error and the Intralingual Error, those two elements refer respectively to the negative influence of both the speaker’s native language, and the target language itself.
Interlingual error is caused by the interference of the native language L1 (also known as interference, linguistic interference, and crosslinguistic influence), whereby the learner tends to use their linguistic knowledge of L1 on some Linguistic features in the target language, however, it often leads to making errors. The example, provided by J. Richard et al. (2002) ‘’ the incorrect French sentence Elle regarde les (“She sees them”), produced according to the word order of English, instead of the correct French sentence Elle les regarde (Literally, “She them sees”). (P. 267) shows the type of errors aroused by the negative effect of the native language interference.
Intralingual error is an error that takes place due to a particular misuse of a particular rule of the target language, it is, in fact, quite the opposite of Interlingual error, it puts the target language into focus, the target language in this perspective is thought of as an error cause. Furthermore, J. Richard, et al. (2002) consider it as one which results from ‘’faulty or partial’’ learning of the target language. (p.267) thus the intralingual error is classified as follow:
Overgeneralizations: in linguistics, overgeneralizations error occur when the speaker applies a grammatical rule in cases where it doesn’t apply. Richard et al, (2002) mentioned that they are caused ‘’by extension of target language rules to inappropriate context.’’ (P.185). this kind of errors have been committed while dealing with regular and irregular verbs, as well as the application of plural forms. E.g. (Tooth == Tooths rather than teeth) and (he goes == he goed rather than went).
Simplifications: they result from learners producing simpler linguistic forms than those found in the target language, in other words, learners attempt to be linguistically creative and produce their own poetic sentences/utterances, they may actually be successful in doing it, but it is not necessary the case, Corder (as cited in Mahmoud 2014:276) mentioned that learners do not have the complex system which they could simplify. This kind of errors is committed through both of Omission and addition of some linguistic elements at the level of either the Spelling or grammar. A. Mahmoud (2014) provided examples based on a research conducted on written English of Arabic-speaking second year University students:
- Spelling: omission of silent letters:
- no (= know) * dout (= doubt) * weit (weight)
- Grammar:
- Omission:
- We wait ^ the bus all the time.
- He was ^ clever and has ^ understanding father.
- Addition:
- Students are do their researches every semester.
- Both the boys and the girls they can study together.
- Omission:
Developmental errors: this kind of errors is somehow part of the overgeneralizations, (this later is subtitled into Natural and developmental learning stage errors), D.E are results of normal pattern of development, such as (come = comed) and (break = breaked), D.E indicates that the learner has started developing their linguistic knowledge and fail to reproduce the rules they have lately been exposed to in target language learning.
Induced errors: as known as transfer of training, errors caused by misleading teaching examples, teachers, sometimes, unconditionally, explain a rule without highlighting the exceptions or the intended message they would want to convey. J. Richard et al. (2002) provided an example that occurs at the level of teaching prepositions and particularly ‘’ at ‘’ where the teacher may hold up a box and say ‘’ I am looking at the box ‘’, the students may understand that ‘’ at ‘’ means ‘’ under ‘’, they may later utter ‘’ the cat is at the table ‘’ instead of the cat is under the table.
Errors of avoidance: these errors occur when the learner fail to apply certain target language rules just because they are thought of to be too difficult.
Errors of overproduction: in the early stages of language learning, learners are supposed to have not yet acquired and accumulated a satisfied linguistic knowledge which can enable them to use the finite rules of the target language in order to produce infinite structures, most of the time, beginners overproduce, in such a way, they frequently repeat a particular structure.
Steps[edit]
According to linguist Corder, the following are the steps in any typical EA research:[3]
- collecting samples of learner language
- identifying the errors
- describing the errors
- explaining the errors
- evaluating/correcting the errors
collection of errors:
the nature and quantity of errors is likely to vary depending on whether the data consist of natural, spontaneous language use or careful, elicited language use.
Corder (1973) distinguished two kinds of elicitation:clinical and experimental elicitation.
clinical elicitation involves getting the informant to produce data of any sort, for example by means of general interview or writing a composition.
experimental elicitation involves the use of special instrument to elicit data containing the linguistic features such as a series of pictures which had been designed to elicit specific features.
Bibliography[edit]
- Anefnaf. Z ( 2017) English Learning: Linguistic flaws, Sais Faculty of Arts and Humanities, USMBA, Retrieved from https://www.academia.edu/33999467/English_Learning_in_Morocco_Linguistic_Flaws
- Chomsky, N. (1965). Aspects of the theory of syntax. Cambridge, MA: MIT Press. P. 4
- Corder, Pit. (1967). the significance of learner’s errors. International Review of Applied Linguistics, 161-170
- Dulay, H., Burt, M., & Krashen, S.D. (1982). Language two. New York: Oxford University Press. p. 150
- Edje, J (1989). Mistakes and Correction. London: Longman. P. 26
- Fang, X. & Xue-mei, J. (2007). Error analysis and the EFL classroom teaching: US-China education review, 4(9), pp. 10–14.
- Hashim, A. (1999). Crosslinguistic influence in the written English of Malay undergraduates: Journal of Modern Languages, 12, (1), pp. 59–76.
- Hendrickson, J.M. (1987). Error correction in foreign language teaching: Recent theory, research, and practice. In M.H. Long & J.C. Richards (Eds.), Methodology in TESOL: A book of readings. Boston: Heinle & Heinle. p. 357
- Norrish, J. (1983). Language learners and their errors. London: Macmillan Press. P. 7
- Richards, J. C. & Schmidt, R. (2002). Dictionary of language teaching and applied linguistics (3rd Ed.). London: Longman.
- Richards J. C., & Rodgers T. S.(2001). Approaches and Methods in Language Teaching. (2nd edition), Cambridge University Press: Cambridge, UK. P. 153
See also[edit]
- Error (linguistics)
- Error treatment (linguistics)
- Second language acquisition
References[edit]
- ^ Corder, S. P. (1967). «The significance of learners’ errors». International Review of Applied Linguistics. 5 (1–4): 160–170. doi:10.1515/iral.1967.5.1-4.161.
- ^ Cf. Bussmann, Hadumod (1996), Routledge Dictionary of Language and Linguistics, London: Routledge, s.v. error analysis. A comprehensive bibliography was published by Bernd Spillner (1991), Error Analysis, Amsterdam/Philadelphia: Benjamins.
- ^ Ellis, Rod (1994). The Study of Second Language Acquisition. p. 48. ISBN 9780194371896.
In linguistics, according to J. Richard et al., (2002), an error is the use of a word, speech act or grammatical items in such a way that it seems imperfect and significant of an incomplete learning (184). It is considered by Norrish (1983, p. 7) as a systematic deviation which happens when a learner has not learnt something, and consistently gets it wrong. However, the attempts made to put the error into context have always gone hand in hand with either [language learning and second-language acquisition] processe, Hendrickson (1987:357) mentioned that errors are ‘signals’ that indicate an actual learning process taking place and that the learner has not yet mastered or shown a well-structured [linguistic competence|competence] in the target language.
All the definitions seeme to stress either on the systematic deviations triggered in the language learning process, or its indications of the actual situation of the language learner themselves, which will later help monitoring, be it an applied linguist or particularly the language teacher to solve the problem, respecting one of the approaches argued in the Error Analysis (Anefnaf 2017). The occurrence of errors doesn’t only indicate that the learner has not learned something yet, but also it gives the linguist the idea of whether the teaching method applied was effective or it needs to be changed.
According to Corder (1976), errors signify three things: first to the teacher, in that the learner tells the teacher, if they have undertaken a systematic analysis, how far towards that goal the learner has progressed and, consequently, what remains for them to learn; second, they provide the researcher with evidence of how language is learned or acquired, and what strategies or procedures the learner is employing in their discovery of the language; third, (and in a sense this is their most important aspect) they are indispensable to the learner himself/herself, because the making of errors can be regarded as a device the learner uses in order to learn (p. 167). The occurrence of errors is merely a sign of ‘the present inadequacy of our teaching methods’(Corder 1976, p. 163).
There have been two schools of thought when it comes to error analysis and philosophy; the first one, according to Corder (1967) linked the error commitment with the teaching method, arguing that if the teaching method was adequate, the errors would not be committed; the second, believed that we live in an imperfect world and that error correction is something real and the applied linguist cannot do without it no matter what teaching approach they may use.
Errors vs. mistakes[edit]
Chomsky (1965) made a distinguishing explanation of competence and performance on which, later on, the identification of mistakes and errors will be possible, Chomsky stated that ‘’We thus make a fundamental distinction between competence (the speaker-hearer’s knowledge of his language) and performance (the actual use of language in concrete situations)’’ ( 1956, p. 4). In other words, errors are thought of as indications of an incomplete learning, and that the speaker or hearer has not yet accumulated a satisfied language knowledge which can enable them to avoid linguistics misuse. Relating knowledge with competence was significant enough to represent that the competence of the speaker is judged by means of errors that concern the amount of linguistic data they have been exposed to, however, performance which is the actual use of language does not represent the language knowledge that the speaker has. According to J. Richard et al (2002), people may have the competence to produce an infinitely long sentence but when they actually attempt to use this knowledge (to “perform”) there are many reasons why they restrict the number of adjectives, adverbs, and clauses in any one sentence (2002, 392).
The actual state of the speaker somehow involves and influences the speaker’s performance by either causing a good performance or mistakes. Thus, it is quite obvious that there is some kind of interrelationship between competence and performance; somehow, a speaker can perform well if they have had already satisfied linguistic knowledge. As a support to this, Corder (1967) mentioned that mistakes are of no significance to “the process of language learning’’ (P. 167).
Error analysis approach[edit]
Before the rise of error analysis approach, contrastive analysis had been the dominant approach used in dealing and conceptualizing the learners’ errors in the 1950s, this approach had often gone hand in hand with concept of L1 Interference and precisely the interlingual effect (Anefnaf Z. 2017), it claimed that the main cause of committing errors in the process of second language learning is the L1, in other words, the linguistic background of the language learners badly affects the production in the target language or second language.
X. Fang and J. Xue-mei (2007) pointed out that contrastive analysis hypothesis claimed that the principal barrier to second language acquisition is the interference of the first language system with the second language system and that a scientific, structural comparison of the two languages in question would enable people to predict and describe which are problems and which are not. Error analysis approach overwhelmed and announced the decline of the Contrastive Analysis which was only effective in phonology; and, according to J. Richard et al. (2002), EA developed as a branch of Linguistics in the 1960s and it came to light to argue that the mother tongue was not the main and the only source of the errors committed by the learners. In addition, Hashim, A. (1999) mentioned that the language effect is more complex and these errors can be caused even by the target language itself and by the applied communicative strategies as well as the type and quality of the second language instructions.
The aim of EA according to J. Richard et al. (2002) is, first, to identify strategies which learners use in language learning, in terms of the approaches and strategies used in both of teaching and learning. Second, to try to identify the causes of learners’ errors, that is, investigating the motives behind committing such errors as the first attempt to eradicate them. Third, to obtain information on common difficulties in Language Learning, as an aid to teaching or in the preparation of the teaching materials,
The two major causes of error, coined by the error analysis approach, are the Interlingual error which is an error made by the Learner’s Linguistic background and Native language interference, and the Intralingual error which is the error committed by the learners when they misuse some Target Language rules, considering that the error cause lies within and between the target language itself and the Learners false application of certain target language rules.
Error analysis in SLA was established in the 1960s by Corder and colleagues.[1] Error analysis (EA) was an alternative to contrastive analysis, an approach influenced by behaviorism through which applied linguists sought to use the formal distinctions between the learners’ first and second languages to predict errors. Error analysis showed that contrastive analysis was unable to predict a great majority of errors, although its more valuable aspects have been incorporated into the study of language transfer. A key finding of error analysis has been that many learner errors are produced by learners making faulty inferences about the rules of the new language.
Error analysts distinguish between errors, which are systematic, and mistakes, which are not. They often seek to develop a typology of errors. Error can be classified according to basic type: omissive, additive, substitutive or related to word order. They can be classified by how apparent they are: overt errors such as «I angry» are obvious even out of context, whereas covert errors are evident only in context. Closely related to this is the classification according to domain, the breadth of context which the analyst must examine, and extent, the breadth of the utterance which must be changed in order to fix the error. Errors may also be classified according to the level of language: phonological errors, vocabulary or lexical errors, syntactic errors, and so on. They may be assessed according to the degree to which they interfere with communication: global errors make an utterance difficult to understand, while local errors do not. In the above example, «I angry» would be a local error, since the meaning is apparent.
From the beginning, error analysis was beset with methodological problems. In particular, the above typologies are problematic: from linguistic data alone, it is often impossible to reliably determine what kind of error a learner is making. Also, error analysis can deal effectively only with learner production (speaking and writing) and not with learner reception (listening and reading). Furthermore, it cannot account for learner use of communicative strategies such as avoidance, in which learners simply do not use a form with which they are uncomfortable. For these reasons, although error analysis is still used to investigate specific questions in SLA, the quest for an overarching theory of learner errors has largely been abandoned. In the mid-1970s, Corder and others moved on to a more wide-ranging approach to learner language, known as interlanguage.
Error analysis is closely related to the study of error treatment in language teaching. Today, the study of errors is particularly relevant for focus on form teaching methodology.
In second language acquisition, error analysis studies the types and causes of language errors. Errors are classified[2] according to:
- modality (i.e., level of proficiency in speaking, writing, reading, listening)
- linguistic levels (i.e., pronunciation, grammar, vocabulary, style)
- form (e.g., omission, insertion, substitution)
- type (systematic errors/errors in competence vs. occasional errors/errors in performance)
- cause (e.g., interference, interlanguage)
- norm vs. system
Types of errors[edit]
Linguists have always been attempting to describe the types of errors committed by the language learners, and that is exactly the best way to start with, as it helps out the applied linguist to identify where the problem lies. According to Dulay et al. (1982) errors take place when the learner change the surface structure in a particularly systematic manner (p. 150), thus, the error, no matter what form and type it is, represent a damage at the level of the target language production.
Errors have been classified by J. Richard et al. (2002) into two categories. The Interlingual Error and the Intralingual Error, those two elements refer respectively to the negative influence of both the speaker’s native language, and the target language itself.
Interlingual error is caused by the interference of the native language L1 (also known as interference, linguistic interference, and crosslinguistic influence), whereby the learner tends to use their linguistic knowledge of L1 on some Linguistic features in the target language, however, it often leads to making errors. The example, provided by J. Richard et al. (2002) ‘’ the incorrect French sentence Elle regarde les (“She sees them”), produced according to the word order of English, instead of the correct French sentence Elle les regarde (Literally, “She them sees”). (P. 267) shows the type of errors aroused by the negative effect of the native language interference.
Intralingual error is an error that takes place due to a particular misuse of a particular rule of the target language, it is, in fact, quite the opposite of Interlingual error, it puts the target language into focus, the target language in this perspective is thought of as an error cause. Furthermore, J. Richard, et al. (2002) consider it as one which results from ‘’faulty or partial’’ learning of the target language. (p.267) thus the intralingual error is classified as follow:
Overgeneralizations: in linguistics, overgeneralizations error occur when the speaker applies a grammatical rule in cases where it doesn’t apply. Richard et al, (2002) mentioned that they are caused ‘’by extension of target language rules to inappropriate context.’’ (P.185). this kind of errors have been committed while dealing with regular and irregular verbs, as well as the application of plural forms. E.g. (Tooth == Tooths rather than teeth) and (he goes == he goed rather than went).
Simplifications: they result from learners producing simpler linguistic forms than those found in the target language, in other words, learners attempt to be linguistically creative and produce their own poetic sentences/utterances, they may actually be successful in doing it, but it is not necessary the case, Corder (as cited in Mahmoud 2014:276) mentioned that learners do not have the complex system which they could simplify. This kind of errors is committed through both of Omission and addition of some linguistic elements at the level of either the Spelling or grammar. A. Mahmoud (2014) provided examples based on a research conducted on written English of Arabic-speaking second year University students:
- Spelling: omission of silent letters:
- no (= know) * dout (= doubt) * weit (weight)
- Grammar:
- Omission:
- We wait ^ the bus all the time.
- He was ^ clever and has ^ understanding father.
- Addition:
- Students are do their researches every semester.
- Both the boys and the girls they can study together.
- Omission:
Developmental errors: this kind of errors is somehow part of the overgeneralizations, (this later is subtitled into Natural and developmental learning stage errors), D.E are results of normal pattern of development, such as (come = comed) and (break = breaked), D.E indicates that the learner has started developing their linguistic knowledge and fail to reproduce the rules they have lately been exposed to in target language learning.
Induced errors: as known as transfer of training, errors caused by misleading teaching examples, teachers, sometimes, unconditionally, explain a rule without highlighting the exceptions or the intended message they would want to convey. J. Richard et al. (2002) provided an example that occurs at the level of teaching prepositions and particularly ‘’ at ‘’ where the teacher may hold up a box and say ‘’ I am looking at the box ‘’, the students may understand that ‘’ at ‘’ means ‘’ under ‘’, they may later utter ‘’ the cat is at the table ‘’ instead of the cat is under the table.
Errors of avoidance: these errors occur when the learner fail to apply certain target language rules just because they are thought of to be too difficult.
Errors of overproduction: in the early stages of language learning, learners are supposed to have not yet acquired and accumulated a satisfied linguistic knowledge which can enable them to use the finite rules of the target language in order to produce infinite structures, most of the time, beginners overproduce, in such a way, they frequently repeat a particular structure.
Steps[edit]
According to linguist Corder, the following are the steps in any typical EA research:[3]
- collecting samples of learner language
- identifying the errors
- describing the errors
- explaining the errors
- evaluating/correcting the errors
collection of errors:
the nature and quantity of errors is likely to vary depending on whether the data consist of natural, spontaneous language use or careful, elicited language use.
Corder (1973) distinguished two kinds of elicitation:clinical and experimental elicitation.
clinical elicitation involves getting the informant to produce data of any sort, for example by means of general interview or writing a composition.
experimental elicitation involves the use of special instrument to elicit data containing the linguistic features such as a series of pictures which had been designed to elicit specific features.
Bibliography[edit]
- Anefnaf. Z ( 2017) English Learning: Linguistic flaws, Sais Faculty of Arts and Humanities, USMBA, Retrieved from https://www.academia.edu/33999467/English_Learning_in_Morocco_Linguistic_Flaws
- Chomsky, N. (1965). Aspects of the theory of syntax. Cambridge, MA: MIT Press. P. 4
- Corder, Pit. (1967). the significance of learner’s errors. International Review of Applied Linguistics, 161-170
- Dulay, H., Burt, M., & Krashen, S.D. (1982). Language two. New York: Oxford University Press. p. 150
- Edje, J (1989). Mistakes and Correction. London: Longman. P. 26
- Fang, X. & Xue-mei, J. (2007). Error analysis and the EFL classroom teaching: US-China education review, 4(9), pp. 10–14.
- Hashim, A. (1999). Crosslinguistic influence in the written English of Malay undergraduates: Journal of Modern Languages, 12, (1), pp. 59–76.
- Hendrickson, J.M. (1987). Error correction in foreign language teaching: Recent theory, research, and practice. In M.H. Long & J.C. Richards (Eds.), Methodology in TESOL: A book of readings. Boston: Heinle & Heinle. p. 357
- Norrish, J. (1983). Language learners and their errors. London: Macmillan Press. P. 7
- Richards, J. C. & Schmidt, R. (2002). Dictionary of language teaching and applied linguistics (3rd Ed.). London: Longman.
- Richards J. C., & Rodgers T. S.(2001). Approaches and Methods in Language Teaching. (2nd edition), Cambridge University Press: Cambridge, UK. P. 153
See also[edit]
- Error (linguistics)
- Error treatment (linguistics)
- Second language acquisition
References[edit]
- ^ Corder, S. P. (1967). «The significance of learners’ errors». International Review of Applied Linguistics. 5 (1–4): 160–170. doi:10.1515/iral.1967.5.1-4.161.
- ^ Cf. Bussmann, Hadumod (1996), Routledge Dictionary of Language and Linguistics, London: Routledge, s.v. error analysis. A comprehensive bibliography was published by Bernd Spillner (1991), Error Analysis, Amsterdam/Philadelphia: Benjamins.
- ^ Ellis, Rod (1994). The Study of Second Language Acquisition. p. 48. ISBN 9780194371896.
Как сделать анализ ошибок, чтобы сделать все ваши модели лучше
Перевод
Ссылка на автора

Введение
Существует множество способов улучшить готовые модели машинного обучения. Есть вещи, которые вы можете сделать как с моделями, так и с данными, чтобы получить лучшие результаты, чем со стандартной версией модели scikit-learn. Существует разработка функций, настройка гиперпараметров и выбор правильной функции стоимости. Если мы углубимся в глубокое обучение, то подойдем к идеям сетевых архитектур, трансферного обучения и многим другим. Как ученый, работающий с данными, это одни из первых и самых важных вещей, которые вы узнаете о построении моделей. Такие инструменты, как случайный поиск и поиск по сетке, должны быть в наборе инструментов каждого ученого, чтобы помочь оптимизировать этот процесс и построить наилучшую возможную модель.
Когда вы работаете над проектом, большинство людей делают все то, что я изложил выше, а затем, с помощью перекрестной проверки или разделения теста поезда, получают некоторую метрику оценки. Эти шаги повторяются до тех пор, пока не будет получена наилучшая возможная метрическая оценка, и модель не будет признана достойной использования. Это ни в коем случае не плохой путь. Обычно это приводит к отличным моделям, которые обеспечивают ценность так, как они должны. Однако, приложив немного дополнительных усилий, вы сможете сделать каждую модель, которую вы когда-либо построите, лучше. Мы можем сделать это с помощью анализа ошибок.
Анализ ошибок
Что это такое?
При построении модели вы можете сделать это случайно или намеренно. Случайный подход к построению модели заманчиво. Это требует меньше усилий и все же приносит результаты. Случайный подход был бы в том случае, когда после каждой итерации модели вы решаете попробовать что-то новое, чтобы сделать это лучше, не задумываясь о том, почему. Это просто так: идея пришла вам в голову, которая может улучшить счет Ф1, так почему бы не попробовать? Это легко и работает.

Преднамеренный подход к построению модели использует анализ ошибок. Анализ ошибок требует от вас копаться в результатах вашей модели после каждой итерации. Вы просматриваете данные и прогнозы на уровне наблюдений и формируете гипотезы о том, почему ваша модель не оправдалась при определенных прогнозах. Затем вы проверяете свою гипотезу, изменяя модель таким образом, чтобы исправить эту ошибку, и начинаете следующую итерацию. Каждая итерация моделирования занимает больше времени с анализом ошибок, но окончательные результаты лучше и, скорее всего, будут быстрее.
Правильный способ сделать анализ ошибок
Не существует установленного способа выполнения анализа ошибок. Это исследовательский и требует творчества и знаний в области. При этом я собираюсь рассказать вам о шагах, которые я обычно делаю, когда делаю это. Надеемся, что это даст вам отправную точку, чтобы найти отличные идеи от ошибок в вашей модели.
Процесс анализа ошибок
С каждой итерацией модели я начинаю с начала этих шагов и прохожу их, пока не найду что-то, что должно быть исправлено. Я делаю свою гипотезу, меняю свою модель и начинаю процесс снова, пока не буду удовлетворен. В этом разделе я расскажу вам о шагах, которые я предпринимаю, о некоторых вещах, которые вы можете найти неправильно, и о некоторых возможных решениях для них. Мы будем работать от самого высокого уровня данных до самого маленького уровня, ища ошибки на этом пути.
Ошибки уровня данных
Это тип анализа ошибок, который, вероятно, является наиболее распространенным, и большинство людей делают. Я хотел бы начать с рассмотрения ошибок модели в масштабе всех данных.
Чрезмерная фитинг / Под облегать
Проверьте, не перегружена ли ваша модель. Мой любимый способ сделать это — использовать кривые обучения, такие как приведенные ниже.

Как правило, я обнаружил на практике, что лучше всего сначала переписать, а затем использовать методы регулирования, чтобы вернуть модель в хорошее место.
Потенциальные исправления:
- Если переопределение, то регуляризация L1 или L2 или больше данных
- Если подгонка, то более сложная модель или больше функций
Распределение прогноза
Убедитесь, что распределение ваших данных выглядит примерно так же, как распределение ваших прогнозов. Если они не похожи друг на друга, у нас есть некоторые проблемы.
Потенциальные исправления:
- Удаление выбросов из данных
- Использование другой функции стоимости
Ошибки уровня группы
Как только ошибки уровня данных будут устранены, мы можем рассмотреть ошибки по группам. Целью этой части анализа ошибок является выявление групп, в которых модель работает плохо. Некоторые знания предметной области могут быть полезны при принятии решения о создании групп. Я бы предложил начать с очевидных групп, которые уже существуют в данных, а затем перейти к созданию групп из интуиции. Например, я мог бы начать с рассмотрения ошибок предсказания по категориальным переменным, а затем перейти к разбивке числовых переменных на корзины для изучения Когда я смотрю на группы, есть несколько конкретных вещей, на которые я всегда обращаю внимание.
За / Под Предсказаниями
Проверьте, есть ли какие-либо конкретные группы, для которых модель переоценивает или недооценивает большую часть времени. Если модель всегда переоценивает определенную группу, это похоже на то, что мы можем научить ее исправить. Также примите к сведению, если группам, которые работают плохо, не хватает данных.
Потенциальные исправления:
- Наказывать за чрезмерные прогнозы для этой группы
- Методы передискретизации при отсутствии данных
- Сбор данных, если данных не хватает
Большие средние ошибки
Проверьте, не вносит ли какая-либо группа вклада в общую ошибку больше, чем все остальные группы. Это важно отметить по нескольким причинам. Во-первых, мы явно хотим знать, что не так, чтобы это можно было исправить. Во-вторых, это важно для интерпретируемостии применение модели. Если модель работает хорошо во всех группах, кроме одной, вы можете просто использовать эту модель для всего, кроме этой группы, если это невозможно исправить.
Потенциальные исправления:
- К-стратифицированная перекрестная проверка для обеспечения групповых наблюдений в каждом расколе
- Методы передискретизации при отсутствии данных
- Сбор данных — это отсутствие данных
Индивидуальные ошибки
Теперь мы приступаем к мельчайшим деталям. Как только мы выполнили весь анализ ошибок более высокого уровня, пришло время погрузиться в ошибки каждого наблюдения. Мне нравится делать это, просматривая 20 лучших ошибок из моих прогнозов. В отличие от анализов более высокого уровня, у меня нет предложений по типичным ошибкам, которые вы можете найти. Вы должны пройти наблюдения и посмотреть на данные и прогноз и определить, был ли прогноз действительным. Иногда модель делала хороший прогноз, и цель этого наблюдения была просто шаткой. Это ошибки, с которыми мы можем жить. Если вы не думаете, что наблюдение кажется разумным, спросите себя, почему. Какую информацию упустила модель, которая должна была помочь ей сделать лучший прогноз? Пройдите несколько наблюдений в поисках закономерностей того, что может быть причиной ошибок. Вы можете найти что-то, что вы пропустили, прежде чем вы могли бы исправить. Вы можете обнаружить, что иногда ваша модель просто портится, и нет никаких причин, чтобы вы могли это увидеть. С этого момента вы либо продолжаете настраивать свою модель, решаете получить больше данных или считаете свою модель хорошей.
Реализуйте это
Анализ ошибок занимает много времени и требует много размышлений. Потратьте время на поиск и изучение причин, по которым ваша модель работает плохо. Шаблон для хорошего анализа ошибок таков:
- Найти ошибки
- Создайте гипотезу о том, что может исправить ошибки
- Проверка гипотезы
- Повторение
Выполнение этих шагов с небольшим творческим потенциалом и терпением поможет вам построить лучшую модель, чем вы могли бы с помощью одной лишь гипер-настройки.
Если у вас есть какие-либо вопросы о том, как сделать эффективный анализ ошибок, оставьте мне комментарий ниже, и я отвечу!
Типы
ошибок: лексическая (недопустимые
символы)
синтаксическая
(в синтаксическом анализаторе)
семантическая
(происходит на этапе семантического
анализа; пример – несоответствие типа
операнда конкретной операции)
логическая
(возникает во время выполнения; пример
— зацикливание)
Обработчик
ошибок должен:
Точно
определить место и тип ошибки,быстро
восстановиться после ошибки для
продолжения анализа
эффективно
работать при анализе корректных программ
Выделяют
несколько стратегий действия после
обнаружения ошибок:
режим
паники транслятор
пропускает символы из входной строки
до обнаружения символа из синхронизирующего
множества Недостатки:Пропускаемое
множество символов может быть очень
большим, Появление цепной реакции,
позднее проявление ошибки
уровень
фразы Недостатки:Для
каждого случая необходимо писать свою
процедуру ошибок
продукции
ошибок Добавляется
ошибочная ситуация, тогда синтаксический
анализатор обнаруживает ошибку,
локализует ее, восстанавливается и
работает дальше.
Недостатки:Описывает
только ограниченные и ранее известные
типы ошибок
глобальная
коррекция необходимо
минимально видоизменить программу,
чтобы она преобразовалась в синтаксически
корректную Недостатки:Сложность
реализации
20 Семантика языка, методы описания и анализа.
-
Фаза
контроля типов -
Идентификация.
Работа с таблицами -
Идентификация.
Работа с типами -
Причины
использования промежуточных языков в
компиляторах -
Различные
формы представления промежуточных
языков (ПЯ) в компиляторах:-
Атрибутивные
деревья разбора -
Прямая
и обратная польские записи -
Триады/тетрады
-
RTL
-
На
этапе семантического анализа можно:
Проверить
соответствие типов
Проверить
управление (различных переходов)
Проверить
единственность (чтобы один раз объявлялась
переменная или функция)
Проверить
имена (чтобы имя встречалось определенное
количество раз)
Сравнение
может быть статическим
(на этапе трансляции) и динамическим
(во время выполнения).
Приведение
типов
Расширяющее
(short
-> long)
Сужающее
(long
-> short)
Формализм
атрибутных грамматик оказался очень
удобным средством для описания семантики
языков программирования
21 Понятие атрибутивные грамматики
входит
в раздел синтаксически управляемые
грамматики.
Для
каждого символа грамматики вводится
атрибут val
Вместе
с правилами грамматики записываются
семантические правила, которые вычисляют
значение этих атрибутов.Процесс
построения дерева разбора, а затем
вычисления атрибутов (нетерминал к
терминалу) и называется синтаксически
управляемой трансляцией
Атрибутивная
грамматика содержит:Синтаксические
правила. Для каждого элемента грамматики
– множество атрибутов.Для каждого
правила – множество семантических
правил
Атрибуты
бывают:Синтезируемые.Наследуемые
Семантическая
часть правила состоит из локальных
объявлений и семантических действий.
В качестве семантических действий
допускаются как атрибутные присваивания,
так и составные операторы.
Метка
в семантической части правила привязывает
выполнение оператора к обходу дерева
разбора сверху-вниз слева направо.
Конструкция i : оператор означает,
что оператор должен быть выполнен сразу
после обхода i-й компоненты правой части.
Конструкция i E : оператор
означает, что оператор должен быть
выполнен, только если порождение i-й
компоненты правой части пусто. Конструкция
i A : оператор означает, что
оператор должен быть выполнен после
разбора каждого повторения i-й компоненты
правой части (имеется в виду конструкция
повторения).
Для математики популярная поговорка «умные люди учатся на чужих ошибках» практически не работает, так как ошибка в большинстве случаев является необходимой и полезной, ведь она позволяет определить пробелы в знаниях школьника и своевременно их устранить. Главное – правильно относится к ошибке и ее правильно ее использовать.
Тем более обидно получать глупые ошибки, которые вызваны невнимательностью обучающихся, пропусками переменных, случайными потерями знаков, скобок и другими различными ляпами.
Для того чтобы снизить вероятность ошибок, необходимо использовать различные методики предупреждения типичных ошибок, что будет в итоге способствовать повышению уровня математической подготовки школьников.
Разбор, анализ и проработка ошибок и неточностей, допущенных при выполнении задания
Организация работы обучающихся, направленной на анализ и исправление допущенных недочетов называется работой над ошибками. Ее основной целью является разбор, анализ и проработка ошибок и неточностей, допущенных при выполнении задания. Правильно организованная работа обучающихся обеспечивает:
-
дифференцированный подход к обучению;
-
является профилактикой будущих ошибок;
-
позволяет своевременно ликвидировать пробелы в знаниях и навыках детей;
-
формирует умение систематизировать и обобщать, закреплять полученные знания.
Грамотный, творческий подход учителя к организации работы над ошибками создает условия для развития адекватного отношения обучающегося к ошибкам, умение работать с ними.
Можно говорить о том, что, после проведения работы над ошибками итоговая оценка отражает действительный уровень усвоения знаний и умений обучающихся. Существует практика, когда некоторые учителя практикуют выставление оценок за каждую проведенную работу. При этом, часто бывает, что после работы над ошибками, отметка за проверяемую работу повышается (как правило на один бал).
Обычно, работа над ошибками проводится в классе, под руководством учителя, но может проводиться и дома, возможно, под контролем родителей. Если учитель считает возможным дать выполнение работы над ошибками в качестве домашнего задания, он должен убедиться, что все обучающиеся знают и помнят основной алгоритм действий по выполнению работы. Целесообразно, каждому ребенку выдать памятку с порядком выполнения действий. Кроме этого, необходимо предварительно, на уроке провести общий анализ допущенных ошибок.
В классе, работу над ошибками проводят, как правило, после контрольных, самостоятельных или творческих работ. Работе над ошибками может быть посвящен, как весь урок, так и его часть. Это зависит от характера и количества видов ошибок, от уровня самостоятельности обучающихся и т.п. По усмотрению учителя возможны: фронтальная, групповая, парная, индивидуальная работа.
Основные этапы и формы организации работы над ошибками на уроке
При работе на уроке выделяют несколько основных этапов:
-
консультация;
-
коррекция знаний и умений;
-
диагностика результатов;
-
оценочная деятельность.
По усмотрению учителя возможны: фронтальная, групповая, индивидуальная работа.
Рассмотрим несколько вариантов проведения работы над ошибками
В начале урока, после проведения общего анализа проверенной работы, учитель просит поднять руку тех обучающихся, которые допустили ошибки при выполнении первого задания. К доске приглашается один из обучающихся, который будет выполнять и комментировать аналогичное задание у доски. Обучающийся определяется либо по его желанию, либо по решению учителя. Остальные обучающиеся выполняют работу у себя в тетрадях. Затем все самостоятельно решают задание проверочной работы. Таким образом, дети прорешивая аналогичное задание, прорабатывают ошибки, допущенные не только ими самими, но и остальными обучающимися. Такой подход целесообразен, когда в данном задании большинство обучающихся допустили ошибки.
Следующая форма работы используется, когда один, или несколько обучающихся допустили ошибки в задании, которое большинство обучающихся выполнили правильно. При данной форме организации урока один обучающийся выполняет работу над своими ошибками у доски, остальные обучающиеся исправляют свои недочеты в тетрадях или выполняют индивидуальные задания. С одной стороны, этот метод позволяет экономить время, затрачиваемое на данную деятельность, с другой — учитель не может контролировать деятельность других детей. Для исправления возникшей ситуации, нужно обеспечить каждому обучающемуся возможность обратиться к учителю за помощью, за консультацией.
Бывают ситуации, когда часть обучающихся выполнила проверочную работу на «отлично», т.е. возникает необходимость организовать деятельность этих обучающихся, и, одновременно организовать выполнение работы над ошибками остальными обучающимися. В этом случае, есть несколько вариантов организации работы на уроке.
Во-первых, «отличникам» можно предложить выполнение индивидуальных заданий повышенного или углубленного уровней, творческие задания, работу по подготовке, например, информационного сообщения к следующему уроку. С остальными обучающимися проводится работа над ошибками.
Во-вторых, обучающихся, показавших высокий уровень усвоения учебного материала, можно привлечь к консультированию других детей. В этом случае возможна организация групповой и (или) парной работы.
Имеют место случаи, когда педагог, в целях экономии времени, выделяет только типичные ошибки, допущенные обучающимися при выполнении проверочной работы, и на уроке проводят работу только таким видом ошибок. В этом случае работа организовывается фронтально, анализ и исправление типичных ошибок и недочетов выполняет весь класс вместе. При этом у доски работают обучающиеся по желанию, по очереди или по решению учителя, в зависимости от того, кто какие ошибки допустил.
Алгоритм действий по выполнению работы над ошибками
Алгоритм действий по проведению работы над ошибками определяется учителем самостоятельно, исходя из особенностей класса, общего уровня обученности и т.д.
Например, алгоритм действий обучающегося может выглядеть следующим образом:
- просмотреть всю работу, обратить внимание на исправления учителя;
- найти ошибку, выписать задание, в котором она допущена, проанализировать причину ее возникновения:
-
ошибка в вычислении – перерешать;
-
ошибка в применении формулы (правила, закона) — вспомнить нужную формулу (правило, закон) по данной теме, применить при решении;
-
ошибка в построении рисунка – повторить материал в учебнике и выполнить рисунок правильно;
- решить аналогичное задание
Памятка-помощник
В практике работы некоторых учителей встречается использование памяток, которые изготавливаются педагогом и раздаются каждому обучающемуся. Памятки могут быть индивидуальными. Работа с памятками выполняется под контролем педагога.
В памятке пронумерованы и записаны основные группы ошибок в виде:
Тема «….».
Примеры.
- …
Если учитель планирует проводить работу над ошибками, с использованием памяток, то при проверке работы на полях тетради, напротив задания, в котором допущена ошибка, ставится номер, соответствующего задания в памятке. Это не только облегчает работу обучающихся, но и совершенствует систему обучения. Обучающийся неоднократно обращается к данной памятке, что способствует лучшему запоминанию учебного материала.
Проверка и подведение итогов работы над ошибками
В конце работы над ошибками необходимо провести проверку. Существует несколько форм ее организации.
-
самопроверка;
-
парная работа;
-
групповая работа, когда «сильные» обучающиеся выступают в роли консультантов;
-
фронтальная работа со всем классом.
Во всех случаях, необходимо обеспечить возможность каждому обучающемуся консультирования и помощи учителя, если возникают трудности.
В конце работы над ошибками, как и в конце любого урока, необходимо провести рефлексию. Дети анализируют свои ошибки, отмечают, как изменились собственные умения, отмечают моменты, которые остались не понятны, говорят о том, что вызвало трудности и высказывают свои предложения.
Следует отметить, что проведение работы над ошибками является обязательным и систематическим действием после каждой контрольной и проверочной работы. При этом необходимо обращать внимание и прорабатывать все ошибки, допущенные обучающимися, тщательно проводить отбор задач и примеров для отработки знаний и умений, для закрепления пройденного материала.
Превентивная деятельность учителя по предупреждению ошибок
Большая часть ошибок, допускаемых обучающимися, не связана с отсутствием или наличием знаний, хотя, конечно, доведение до уровня автоматизма ряда вычислительных операций позволяет существенно снизить вероятность появления ошибок. Однако при этом необходимо, чтобы обучающийся все равно руководствовался нужными правилами и постоянно сохранял концентрацию внимания.
Знание определенных правил нужно и для того, чтобы обучающийся мог проверить правильность решения и дать его обоснование. В тоже время многие школьники воспринимают курс алгебры в качестве набора правил, которые абсолютно не связаны между собой, поэтому они заучиваются исключительно для решения какой-то конкретной задачи, а по истечению незначительного промежутка времени просто забываются. В этой связи требуется организовывать процесс обучения правилам с использованием приемов, которые активизируют рефлексивную деятельность школьников по предупреждению и исправлению ошибок, возникающих при формальном усвоении правил.
Если процесс поиска и исправления ошибок сделать максимально поучительным для обучающихся, то анализ ошибок может стать эффективным средством для развития познавательного интереса к математике.
Наиболее распространенными ошибками являются:
-
незнание или непонимание правил, формул и определений;
-
неправильное применение формул или неумение правильно применять определения и правила;
-
совершение вычислительных ошибок;
-
невнимательное чтение условий задачи;
-
отказ от использования свойств фигур при решении геометрических задач;
-
неправильное раскрытие скобок;
-
совершение логических ошибок при решении текстовых задач;
-
применение формул сокращенного умножения.
К основным причинам совершения ошибок по математике относят:
-
пропуски уроков, в результате чего появляются пробелы в знаниях;
-
поверхностное изучение нового материала;
-
повышенная усталость, вызванная чрезмерной нагрузкой или недостаточным сном, в результате чего понижается скорость мышления и снижается уровень внимания;
-
неаккуратный почерк, из-за чего учитель часто не понимает, что написал обучающийся;
-
скорость работы. При этом на появление ошибок влияет как высокая скорость работы, из-за которой обучающийся просто не стремиться вникнуть в суть задания, так и медленная. В последнем случае замедленная скорость мыслительных операций не позволяет обучающемуся в полной мере контролировать себя, а из-за «зависания» нужная информация просто удаляется из «оперативной памяти»;
-
полное либо кратковременное переключение внимания с одной деятельности на другую;
-
низкая мотивация, в результате которой теряется внимание и появляются ошибки.
Объяснение и предупреждение ошибок
Для предупреждения ошибок и сведения их к минимуму используются следующие профилактические мероприятия и действия:
-
постоянный разбор наиболее распространенных ошибок в классе;
-
предлагаемые обучающимся письменные задания должны быть максимально удобны для восприятия, то есть грамотно сформулированными и понятными;
-
подбор заданий и упражнений, которые будут вызывать у детей интерес и повышенное внимание;
-
учитель должен при объяснении нового материала стараться предугадать возможные ошибки обучающихся и разработать систему заданий, которые позволят правильно усвоить новые понятия;
-
использование правил удобных для запоминания и исключающих двойную их трактовку.
Кроме того, учитель математики должен помнить, что систематическое и планомерное повторение является основным инструментом для ликвидации пробелов знаний.
Также рекомендуется при объяснении нового материала активно применять определения и теоремы, которые изучались ранее. Так, при изучении темы «Теоремы сложения» целесообразно организовать повторение ряда теоретических вопросов:
-
Изменение тригонометрических функций при возрастании и убывании аргумента.
-
Четные и нечетные функции.
-
Таблицы значений тригонометрических функций.
-
Знаки тригонометрических функций.
Дополнительно выполняются следующие задания:
-
Необходимо определить четность и нечестность тригонометрических функций:
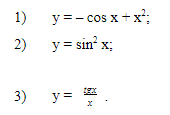
-
Найдите область определения функции y = x2 – 6x + 10.
-
Определите, при каких значениях x, функции y = sin x и y = cos x принимают одинаковые значения?
Перед тем как приступить к изучению темы «Первообразная и интеграл», следует повторить все формулы дифференцирования. После этого обучающиеся выполняют самостоятельную работу (время решения – 10-15 минут), во время которой школьникам предлагаются карточки-задания, где «опущены» один-два компонента из формулы дифференцирования, а также приведены две функции, производные которых необходимо найти.
Затем проводиться проверка работы и анализ совершенных ошибок, что необходимо для выявления пробелов в знаниях и проведения работы по их устранению.
Список литературы:
- Азиев И.К. Индивидуальные задания для устранения ошибок. // Журнал «Математика в школе» – 1993 г. – №5, с. 9.
- Амонашвили Ш.А. Воспитательная и образовательная функции оценки обучения школьников: Экспериментальное педагогическое исследование. – М.: Педагогика, 1984. – 296 с.
- Бабанский Ю.К. Педагогика. М.: Просвещение, 1983.
- Волович И.Б. Наука обучать: Технология преподавания математики. – М.: LINKA-PRESS. 1995. – 280 с.
- Груденов Я.И. Совершенствование методики работы учителя математики: Кн. для учителя. – М.: Просвещение, 1990. – 224 с.
- Груденов Я.И. Психолого-дидактические основы методике обучения математики. – газета «Математика», 1987 г. с. 91-96.
- Гуцанович С.А. Дидактические основы математического развития учащихся: Монография. – Минск: БГПУ им. М. Танка, 1999. – 301 с.
- Давыдов В. В. Проблемы развивающего обучения. Опыт теоретического и экспериментального исследования / В. В. Давыдов. – М.: Педагогика, 1986. – 239 с.
- Далингер В.А. Методика реализации внутрипредметных связей при обучении математике: Кн. для учителя. – М.: Просвещение, 1991. – 80 с.
- Далингер В.А. Обучение учащихся доказательству теорем: Учебное пособие. – Омск: Омский пед. ин-т, 1990. – 127 с.
- Действующие учебники и учебные пособия по математике для средней школы.
- Журналы «Математика в школе» за 1970-1990 гг.
- Колягин Ю.М. Задачи в обучении математике: Математические задачи как средство обучения и развития учащихся: в 2ч. – М.: Просвещение, 1977. – ч.2. – 144 с.
- Колягин Ю.М. Задачи в обучении математике: Обучение математике через задачи и обучение решению задач: в 2ч. – М.: Просвещение, 1977. – ч.2. – 144 с.
- Метельский Н.В. Дидактика математики. – Минск: Изд-во БГУ, 1982–254с.
- Методика преподавания математики в средней школе: Общая методика: учеб. пособие; сост. Р. С. Черкасов, А. А. Столяр. – М.: Просвещение, 1985. – 336 с.
- Новик И.А. Формирование методической культуры учителя математики в педвузе. – Мн.: БГПУ им. М. Танка, 2002. – 193 с.
- Новик, И. А. Практикум по методике преподавания математики / И. А. Новик. – Минск: Выш. шк., 1984. – 175 с.
- Оганесян В.А. Принципы отбора основного содержания обучения математике в средней школе. – Ереван: Луис, 1984. – 215 с.
- Рогановский, Н. М. Методика преподавания математики в средней школе: учеб. пособие / Н. М. Рогановский. – Минск: Выш. шк., 1990. – 267 с.
- Селевко, Г. К. Современные образовательные технологии: учеб. пособие / Г. К. Селевко. – М.: Народное образование, 1998. – 256 с.
- Столяр, А. А. Педагогика математики: учеб. пособие / А. А. Столяр. – Минск: Выш. шк., 1986. – 414 с.
- Темербекова, А. А. Методика преподавания математики: учеб. пособие / А. А. Темербекова. – М.: ВЛАДОС, 2003. – 176 с.
- Фридман, Л. М. Психолого-педагогические основы обучения математике в школе / Л. М. Фридман. – М.: Просвещение, 1983. – 160 с.
- Шнейдерман М.В. Анализ ошибок и затруднений учащихся V классов // Журнал «Математика в школе» – 1999 г. – №6, с. 21.
- Эрдниев, П. М. Обучение математике в школе. Укрупнение дидактических единиц / П. М. Эрдниев, Б. Л. Эрдниев. – М.: Столетие, 1996. – 320 с.
- Якиманская И.С. Личностно-ориентированное обучение в современной школе – М., 1996. – 347 с.
- Якиманская И.С. Психологические основы математического образования. – М.: Acadiia, 2004.
- Ярский А.С. Что делать с ошибками // Журнал «Математика в школе» – 1998 г. – №2, с. 8-14.
|
|

Макеты страниц
1. Прямой анализ ошибок.
Общий эффект влияния ошибок обычно учитывают следующим образом. Изучают воздействие ошибок входных данных, метода и округлений на получаемый результат у к пытаются оценить некоторую меру близости у к истинному решению у. Такой метод исследования называяют прямым анализом ошибок В большинстве случаев в данной книге мы будем следовать этому традиционному пути. Во многих (но далеко не во всех) случаях оценки погрешности удается получить; однако довольно часто они оказываются сильно завышенными и приводят к неоправданному пессимизму в оценке качества приближенного решения. Реальная величина погрешности у — у часто значительно меньше, чем ее оценка, рассчитанная на самый неблагоприятный случай и выведенная с помощью прямого анализа. Особенно трудным является прямой анализ вычислительной погрешности.
2. Обратный анализ ошибок.
В последнее время получил широкое распространение другой подход к оценке влияния ошибок. Оказывается, что довольно часто приближенное решение у можно трактовать как точное решение той же задачи, но отвечающее возмущенным
исходным данным х. Оценка величины такого эквивалентного возмущения и является целью обратного анализа ошибок.
В прикладных задачах входные данные, как правило, содержат погрешности. Обратный анализ показывает, что ошибки, внесенные в решение в процессе его вычисления, оказываются равносильными некоторым дополнительным ошибкам, внесенным во входные данные. Сопоставление величины эквивалентного возмущения и уровня ошибок входных данных позволяет судить о качестве найденного решения. На рис. 3.5 представлена графическая иллюстрация обратного анализа ошибок. Здесь данное х таково, что решением задачи, соответствующим х, является у — результат приближенного решения задачи с входным данным х. На рисунке заштрихована область неопределенности входного данного; в пределах этой области входные данные для решающего задачу неразличимы. В представленном случае х оказалось внутри этой области, поэтому результат у следует признать вполне приемлемым.

Рис. 3.5
Каждый из указанных двух подходов к оценке погрешности имеет свои достоинства и полезным является разумное их сочетание.
Пример 3.32. Пусть на  -разрядной десятичной ЭВМ вычисляется корень уравнения
-разрядной десятичной ЭВМ вычисляется корень уравнения

При вводе в ЭВМ последние два коэффициента будут округлены до шести значащих цифр и уравнение примет вид

Допустим, что некоторый алгоритм, примененный к этому уравнению, дал значение приближенного решения  Следуя логике прямого анализа
Следуя логике прямого анализа
ошибок, чтобы оценить качество полученного приближения нужно было бы задаться вопросом: насколько отличается  от истинного решения х уравнения
от истинного решения х уравнения  Мы поступим иначе. Подставляя
Мы поступим иначе. Подставляя  в левую часть уравнения (3.22), получим значение
в левую часть уравнения (3.22), получим значение  Заметим теперь, что
Заметим теперь, что  является точным решением уравнений
является точным решением уравнений

которые после округления коэффициентов совпадают с уравнением (3.22) и становятся неотличимы от исходного уравнения. Найденное решение следует признать превосходным с точки зрения «философии» обратного анализа ошибок, так как оно является точным решением задачи, лежащей в пределах области неопределенности задачи (3.22). Рассчитывать на то, что после записи уравнения в виде (3.22) удастся получить лучший ответ, просто бессмысленно. Конечно, это немного обидно, особенно если учесть, что исходное уравнение в действительности есть развернутая запись уравнения  и истинным значением корня является
и истинным значением корня является 
Представляется, что значение обратного анализа ошибок недостаточно осознанно, в особенности среди непрофессиональных вычислителей. Этот подход показывает на возможность иного взгляда на оценку качества приближенного решения, а, значит, и на качество многих вычислительных алгоритмов. Сложившийся стереотип заставляет искать приближенное решение у математической задачи, мало отличающееся от ее истинного решения у. Однако для большинства практических задач в силу неопределенности в постановке и входных данных в действительности существует и область неопределенности решения (см. рис. 3.5). Поскольку эта область неизвестна, оценить степень близости вычисленного решения у к ней очень трудно. Гораздо проще, быть может, получить ответ на аналогичный вопрос для входного данного х, соответствующего решению у. Поэтому можно сформулировать цель вычислений и так: «найти точное решение задачи, которая мало отличается от поставленной задачи» или же так: «найти решение задачи с входным данным х, находящимся в пределах области неопределенности заданного входного данного 
Пример 3-33. Пусть для задачи Коши

где  найдено приближенное решение
найдено приближенное решение  Как оценить его качество?
Как оценить его качество?
Условие  очевидно, выполнено. Подставляя
очевидно, выполнено. Подставляя  в левую часть уравнения, убеждаемся, что
в левую часть уравнения, убеждаемся, что  удовлетворяет уравнению (3.23) с коэффициентом
удовлетворяет уравнению (3.23) с коэффициентом  и 2.586 вместо а. Обратим внимание на то, что «истинное» значение
и 2.586 вместо а. Обратим внимание на то, что «истинное» значение  коэффициента а нам в действительности неизвестно и
коэффициента а нам в действительности неизвестно и  лишь некоторое его приближение. Числовой параметр 2.6 в лучшем случае получен округлением «истинного» значения, и, следовательно, а может отличаться от
лишь некоторое его приближение. Числовой параметр 2.6 в лучшем случае получен округлением «истинного» значения, и, следовательно, а может отличаться от  и на 0.05. Так как
и на 0.05. Так как  то в силу естественной неопределенности в постановке задачи функция
то в силу естественной неопределенности в постановке задачи функция  с позиции обратного анализа ошибок может считаться таким же равноправным решением поставленной задачи, как и найденное сколь угодно точно решение задачи (3.23). Во всяком случае теперь для того, чтобы отказаться от найденного приближенного решения, нужны довольно веские аргументы.
с позиции обратного анализа ошибок может считаться таким же равноправным решением поставленной задачи, как и найденное сколь угодно точно решение задачи (3.23). Во всяком случае теперь для того, чтобы отказаться от найденного приближенного решения, нужны довольно веские аргументы.
Подчеркнем, что в основе методов решения некорректных и плохо обусловленных задач также лежит существенное переосмысление постановок вычислительных задач.
3. Статистический анализ ошибок.
Даже для простых алгоритмов строгий анализ влияния ошибок округления очень сложен. При большом числе выполняемых операций гарантированные оценки погрешности, рассчитанные на самый неблагоприятный случай, как правило, бывают сильно завышенными.
Можно надеяться на то, что появляющиеся в реальном вычислительном процессе ошибки округления случайны и их взаимное влияние приводит к определенной компенсации результирующей ошибки. Статистический анализ ошибок, исходящий из предположения об их случайности, направлен на исследование не максимально возможных, а наиболее вероятных ошибок.
Для сравнения покажем отличие в результатах на примере задачи вычисления суммы  большого числа положительных слагаемых. Гарантированная оценка погрешности дает значение относительной погрешности
большого числа положительных слагаемых. Гарантированная оценка погрешности дает значение относительной погрешности  растущее пропорционально
растущее пропорционально  . В то же время статистический анализ показывает, что если ошибки округления являются случайными с нулевым средним значением, то
. В то же время статистический анализ показывает, что если ошибки округления являются случайными с нулевым средним значением, то  растет пропорционально
растет пропорционально  т.е. гораздо медленнее. К сожалению, на тех ЭВМ, где округление производится усечением, последнее предположение не выполнено, так как ошибки округления смещены в одну сторону и поэтому имеют ненулевое среднее значение. Здесь
т.е. гораздо медленнее. К сожалению, на тех ЭВМ, где округление производится усечением, последнее предположение не выполнено, так как ошибки округления смещены в одну сторону и поэтому имеют ненулевое среднее значение. Здесь  растет опять пропорционально
растет опять пропорционально 
4. Некоторые нестрогие способы анализа.
Распространенным
методом оценки влияния вычислительной погрешности является расчет с обычной и удвоенной точностью. Если результаты двух вычислений получаются существенно различными, это является свидетельством плохой обусловленности алгоритма. В то же время есть надежда на то, что совпадающие в ответах цифры верны.
Примерно такие же суждения о чувствительности решения к ошибкам округления можно сделать, если провести вычисления на двух различных вычислительных машинах или использовать различные компиляторы. Разумеется, такое исследование имеет смысл провести на одном-двух типичных примерах до начала массовых однотипных расчетов.
Влияние ошибок во входных данных на результат вычислений можно увидеть, если решить задачу несколько раз, изменяя случайным образом входные данные в пределах ошибки их задания. Проделав такой эксперимент несколько раз, можно грубо оценить погрешность решения, вызванную погрешностями входных данных.
1
Оглавление
- ПРЕДИСЛОВИЕ
- Глава 1. МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ И РЕШЕНИЕ ИНЖЕНЕРНЫХ ЗАДАЧ С ПРИМЕНЕНИЕМ ЭВМ
- § 1.2. Основные этапы решения инженерной задачи с применением ЭВМ
- § 1.3. Вычислительный эксперимент
- § 1.4. Дополнительные замечания
- Глава 2. ВВЕДЕНИЕ В ЭЛЕМЕНТАРНУЮ ТЕОРИЮ ПОГРЕШНОСТЕЙ
- § 2.1. Источники и классификация погрешностей результата численного решения задачи
- § 2.2. Приближенные числа. Абсолютная и относительная погрешности
- 2. Правила записи приближенных чисел.
- 3. Округление.
- § 2.3. Погрешности арифметических операций над приближенными числами
- § 2.4. Погрешность функции
- § 2.5. Особенности машинной арифметики
- 2. Представление целых чисел.
- 3. Представление вещественных чисел.
- 4. Арифметические операции над числами с плавающей точкой.
- 5. Удвоенная точность.
- 6. Вычисление машинного эпсилон.
- § 2.6. Дополнительные замечания
- Глава 3. ВЫЧИСЛИТЕЛЬНЫЕ ЗАДАЧИ, МЕТОДЫ И АЛГОРИТМЫ. ОСНОВНЫЕ ПОНЯТИЯ
- § 3.2. Обусловленность вычислительной задачи
- 2. Примеры плохо обусловленных задач.
- 3. Обусловленность задачи вычисления значения функции одной переменной.
- 4. Обусловленность задачи вычисления интеграла …
- 5. Обусловленность задачи вычисления суммы ряда.
- § 3.3. Вычислительные методы
- § 3.4. Корректность вычислительных алгоритмов
- § 3.5. Чувствительность вычислительных алгоритмов к ошибкам округления
- § 3.6. Различные подходы к анализу ошибок
- § 3.7. Требования, предъявляемые к вычислительным алгоритмам
- § 3.8. Дополнительные замечания
- Глава 4. МЕТОДЫ ОТЫСКАНИЯ РЕШЕНИЙ НЕЛИНЕЙНЫХ УРАВНЕНИЙ
- § 4.2. Обусловленность задачи вычисления корня
- § 4.3. Метод бисекции
- § 4.4. Метод простой итерации
- § 4.5. Обусловленность метода простой итерации
- § 4.6. Метод Ньютона
- § 4.7. Модификации метода Ньютона
- § 4.8. Дополнительные замечания
- Глава 5. ПРЯМЫЕ МЕТОДЫ РЕШЕНИЯ СИСТЕМ ЛИНЕЙНЫХ АЛГЕБРАИЧЕСКИХ УРАВНЕНИЙ
- § 5.2. Нормы вектора и матрицы
- § 5.3. Типы используемых матриц
- § 5.4. Обусловленность задачи решения системы линейных алгебраических уравнений
- § 5.5 Метод Гаусса
- § 5.6. Метод Гаусса и решение систем уравнений с несколькими правыми частями, обращение матриц, вычисление определителей
- § 5.7. Метод Гаусса и разложение матрицы на множители. LU-разложение
- § 5.8. Метод Холецкого (метод квадратных корней)
- § 5.9. Метод прогонки
- § 5.10. QR-разложение матрицы. Методы вращений и отражений
- § 5.11. Итерационное уточнение
- § 5.12. Дополнительные замечания
- Глава 6. ИТЕРАЦИОННЫЕ МЕТОДЫ РЕШЕНИЯ СИСТЕМ ЛИНЕЙНЫХ АЛГЕБРАИЧЕСКИХ УРАВНЕНИЙ
- § 6.1. Метод простой итерации
- § 6.2. Метод Зейделя
- § 6.3. Метод релаксации
- § 6.4. Дополнительные замечания
- Глава 7. МЕТОДЫ ОТЫСКАНИЯ РЕШЕНИЙ СИСТЕМ НЕЛИНЕЙНЫХ УРАВНЕНИЙ
- § 7.2. Метод простой итерации
- § 7.3. Метод Ньютона для решения систем нелинейных уравнений
- 7.4. Модификации метода Ньютона
- § 7.5. О некоторых подходах к решению задач локализации и отыскания решений систем нелинейных уравнений
- § 7.6. Дополнительные замечания
- Глава 8. МЕТОДЫ РЕШЕНИЯ ПРОБЛЕМЫ СОБСТВЕННЫХ ЗНАЧЕНИЙ
- § 8.2. Степенной метод
- § 8.3. Метод обратных итераций
- § 8.4. QR-алгоритм
- § 8.5. Дополнительные замечания
- Глава 9. МЕТОДЫ ОДНОМЕРНОЙ МИНИМИЗАЦИИ
- § 9.2. Обусловленность задачи минимизации
- § 9.3. Методы прямого поиска. Оптимальный пассивный поиск. Метод деления отрезка пополам. Методы Фибоначчи и золотого сечения
- § 9.4. Метод Ньютона и другие методы минимизация гладких функций
- § 9.5. Дополнительные замечания
- Глава 10. МЕТОДЫ МНОГОМЕРНОЙ МИНИМИЗАЦИИ
- § 10.1. Задача безусловной минимизации функции многих переменных
- § 10.2. Понятие о методах спуска. Покоординатный спуск
- § 10.3. Градиентный метод
- § 10.4. Метод Ньютона
- § 10.5. Метод сопряженных градиентов
- § 10.6. Метода минимизации без вычисления производных
- § 10.7. Дополнительные замечания
- Глава 11. ПРИБЛИЖЕНИЕ ФУНКЦИЙ И СМЕЖНЫЕ ВОПРОСЫ
- § 11.2. Интерполяция обобщенными многочленами
- § 11.3. Полиномиальная интерполяция. Многочлен Лагранжа
- § 11.4. Погрешность интерполяции
- § 11.5. Интерполяция с кратными узлами
- § 11.6. Минимизация оценки погрешности интерполяции. Многочлены Чебышева
- § 11.7. Конечные разности
- § 11.8. Разделенные разности
- § 11.9. Интерполяционный многочлен Ньютона. Схема Эйткена
- § 11.10. Обсуждение глобальной полиномиальной интерполяции. Понятие о кусочно-полиномиальной интерполяции
- § 11.11. Интерполяция сплайнами
- § 11.12. Понятие о дискретном преобразовании Фурье и тригонометрической интерполяции
- § 11.13. Метод наименьших квадратов
- § 11.14. Равномерное приближение функций
- § 11.15. Дробно-рациональные аппроксимации и вычисление элементарных функций
- § 11.16. Дополнительные замечания
- Глава 12. ЧИСЛЕННОЕ ДИФФЕРЕНЦИРОВАНИЕ
- § 12.1. Простейшие формулы численного дифференцирования
- § 12.2. О выводе формул численного дифференцирования
- § 12.3. Обусловленность формул численного дифференцирования
- § 12.4. Дополнительные замечания
- Глава 13. ЧИСЛЕННОЕ ИНТЕГРИРОВАНИЕ
- 13.2. Квадратурные формулы интерполяционного типа
- § 13.3. Квадратурные формулы Гаусса
- § 13.4. Апостериорные оценки погрешности. Понятие об адаптивных процедурах численного интегрирования
- § 13.5. Вычисление интегралов в нерегулярных случаях
- § 13.6. Дополнительные замечания
- Глава 14. ЧИСЛЕННЫЕ МЕТОДЫ РЕШЕНИЯ ЗАДАЧИ КОШИ ДЛЯ ОБЫКНОВЕННЫХ ДИФФЕРЕНЦИАЛЬНЫХ УРАВНЕНИЙ
- § 14.1. Задача Коши для дифференциального уравнения первого порядка
- § 14.2. Численные методы решения задачи Коши. Основные понятия и определения
- § 14.3. Использование формулы Тейлора
- § 14.4. Метод Эйлера
- § 14.5. Модификации метода Эйлера второго порядка точности
- § 14.6. Методы Рунге-Кутты
- § 14.7. Линейные многошаговые методы. Методы Адамса
- § 14.8. Устойчивость численных методов решения задачи Коши
- § 14.9. Неявный метод Эйлера
- § 14.10. Решение задачи Коши для систем обыкновенных дифференциальных уравнений и дифференциальных уравнений m-го порядка
- § 14.11. Жесткие задачи
- § 14.12. Дополнительные замечания
- Глава 15. РЕШЕНИЕ ДВУХТОЧЕЧНЫХ КРАЕВЫХ ЗАДАЧ
- § 15.1. Краевые задачи для одномерного стационарного уравнения теплопроводности
- § 15.2. Метод конечных разностей: основные понятия
- § 15.3. Метод конечных разностей: аппроксимации специального вида
- § 15.4. Понятие о проекционных и проекционно-разностных методах. Методы Ритца и Гадеркина. Метод конечных элементов
- § 15.5. Метод пристрелки
- § 15.6. Дополнительные замечания
Анализ ошибок
Анализ ошибок — это процесс идентификации, классификации и изучения ошибок в различных областях деятельности с целью улучшения производительности и предотвращения повторения ошибок.
Цели анализа ошибок
Основная цель анализа ошибок состоит в том, чтобы выявить причины ошибок и разработать план действий по их предотвращению. Кроме того, анализ ошибок может помочь определить характеристики системы или процесса, которые приводят к нарушениям и выявить области для улучшения производительности.
Процесс анализа ошибок
Процесс анализа ошибок включает следующие этапы:
- Сбор данных — включает в себя сбор информации о всех ошибочных действиях или ситуациях, которые произошли.
- Классификация ошибок — определение типа ошибки, которое позволяет идентифицировать причины ошибки.
- Определение причины ошибки — включает в себя выявление факторов, которые привели к ошибки на основе ее классификации.
- Разработка плана к действий по предотвращению ошибок — разработка плана по предотвращению ошибок, который должен помочь устранить причины ошибок, выявленные в процессе анализа.
- Реализация плана — применение плана действий для предотвращения ошибок.
- Оценка результатов — оценка эффективности плана действий по предотвращению ошибок.
Виды ошибок
В зависимости от области деятельности, ошибки могут классифицироваться по различным критериям. Некоторые из наиболее распространенных типов ошибок включают:
- Технические ошибки — это ошибки, связанные с техническими аспектами конкретной системы или процесса, такие как отказ оборудования, неправильная настройка конфигурации и т.д.
- Организационные ошибки — ошибки, связанные с организационными аспектами работы компании, например, определение неправильного порядка работы или неправильное распределение обязанностей.
- Человеческие ошибки — ошибки, связанные с поведением людей, такие как неправильно выполненное действие, что может привести к несчастному случаю.
- Ошибки данных — ошибки, связанные с неверной или неполной информацией, например, ошибка при вводе данных в базу данных.
Заключение
В целом, анализ ошибок является важным инструментом для любой компании, особенно тех, которые сталкиваются с непредвиденными ситуациями, вызывающими ошибки в работе. Он поможет улучшить производительность и качество работы, а также позволит предотвратить повторение ошибок и снизить потенциальные риски.
Смотри также:
- Как
- Арсенал-2008 из Тулы разгромил соперников в старте ЮФЛ
- Юношеская футбольная лига приветствует тульский клуб Арсенал-2008
- Как команда Арсенал-2008 из Тулы начинает свой путь в Юношеской футбольной лиге
- Кризис «Арсенала»: почему команда упустила +2 второй раз подряд?
- Упускает первое за 19 лет чемпионство: причины и последствия
- Стратегии
- Что нужно изменить для выигрыша чемпионства
- Как обезопасить себя от провала в следующем чемпионате
В математике анализ ошибок — это изучение вида и количества ошибка или неопределенность, которая может присутствовать в решении проблемы. Эта проблема особенно актуальна в прикладных областях, таких как численный анализ и статистика.
Содержание
- 1 Анализ ошибок в численном моделировании
- 1.1 Прямой анализ ошибок
- 1.2 Обратный анализ ошибок
- 2 Приложения
- 2.1 Глобальная система позиционирования
- 2.2 Моделирование молекулярной динамики
- 2.3 Проверка научных данных
- 3 См. Также
- 4 Ссылки
- 5 Внешние ссылки
Анализ ошибок в числовом моделирование
При численном моделировании или моделировании реальных систем анализ ошибок связан с изменениями в выходных данных модели, поскольку параметры модели меняются примерно на среднее.
Например, в системе, моделируемой как функция двух переменных z = f (x, y) { displaystyle scriptstyle z , = , f (x, y)}






В численном анализе анализ ошибок включает в себя как прямой анализ ошибок, так и обратный анализ ошибок .
Прямой анализ ошибок
Прямой анализ ошибок включает анализ функции z ‘= Е’ (a 0, a 1,…, an) { displaystyle scriptstyle z ‘= f’ (a_ {0}, , a_ {1}, , dots, , a_ {n}) }



Обратный анализ ошибок
Обратный анализ ошибок включает в себя анализ аппроксимационной функции z ′ = f ′ (a 0, a 1, …, An) { displaystyle scriptstyle z ‘, = , f’ (a_ {0}, , a_ {1}, , dots, , a_ {n})}


Обратный анализ ошибок, теория которого была разработана и популяризированный Джеймсом Х. Уилкинсоном, может использоваться для установления числовой устойчивости алгоритма, реализующего числовую функцию. Основной подход состоит в том, чтобы показать, что хотя вычисленный результат из-за ошибок округления не будет в точности правильным, это точное решение ближайшей проблемы со слегка нарушенными входными данными. Если требуемое возмущение невелико, порядка неопределенности входных данных, то результаты в некотором смысле являются настолько точными, насколько данные «заслуживают». Затем алгоритм определяется как обратная стабильность. Стабильность — это мера чувствительности к ошибкам округления данной числовой процедуры; Напротив, номер условия функции для данной проблемы указывает на внутреннюю чувствительность функции к небольшим возмущениям на ее входе и не зависит от реализации, используемой для решения проблемы.
Приложения
Глобальная система позиционирования
Анализ ошибок, вычисленных с использованием глобальной системы позиционирования, важен для понимания того, как работает GPS, и для понимания того, что следует ожидать ошибок по величине. Глобальная система позиционирования исправляет ошибки часов приемника и другие эффекты, но остаются остаточные ошибки, которые не исправляются. Система глобального позиционирования (GPS) была создана Министерством обороны США (DOD) в 1970-х годах. Он стал широко использоваться для навигации как военными США, так и населением.
Моделирование молекулярной динамики
В моделировании молекулярной динамики (MD) возникают ошибки из-за неадекватной выборки фазового пространства или редко происходящих событий, которые приводят к статистическим ошибка из-за случайных колебаний в измерениях.
Для серии из M измерений флуктуирующего свойства A среднее значение будет:
- ⟨A⟩ = 1 M ∑ μ = 1 M A μ. { displaystyle langle A rangle = { frac {1} {M}} sum _ { mu = 1} ^ {M} A _ { mu}.}

Когда эти измерения M независимы, дисперсия среднего равна:
- σ 2 (⟨A⟩) = 1 M σ 2 (A), { displaystyle sigma ^ {2} ( langle A rangle) = { frac {1 } {M}} sigma ^ {2} (A),}

, но в большинстве моделей МД существует корреляция между величиной A в разное время, поэтому дисперсия среднего будет недооценена как эффективное количество независимых измерений фактически меньше M. В таких ситуациях мы перепишем дисперсию как:
- σ 2 (⟨A ⟨) = 1 M σ 2 A [1 + 2 ∑ μ (1 — μ M) ϕ μ], { Displaystyle sigma ^ {2} ( langle A rangle) = { frac {1} {M}} sigma ^ {2} A left [1 + 2 sum _ { mu} left (1 — { frac { mu} {M}} right) phi _ { mu} right],}
![sigma ^ {2 } ( langle A rangle) = frac {1} {M} sigma ^ {2} A left [1 + 2 sum_ mu left (1 - frac { mu} {M} right) phi _ { mu} right],](https://wikimedia.org/api/rest_v1/media/math/render/svg/588033e9f979f2f317e5e04b0008795f3160e6c9)
где ϕ μ { displaystyle phi _ { mu}}
- ϕ μ = ⟨A μ A 0⟩ — ⟨A⟩ 2 ⟨A 2⟩ — ⟨A⟩ 2. { displaystyle phi _ { mu} = { frac { langle A _ { mu} A_ {0} rangle — langle A rangle ^ {2}} { langle A ^ {2} rangle — langle A rangle ^ {2}}}.}

Затем мы можем использовать функцию автокорреляции для оценки шкалы ошибок. К счастью, у нас есть гораздо более простой метод, основанный на.
Проверка научных данных
Измерения обычно имеют небольшую погрешность, а повторные измерения одного и того же элемента обычно приводят к небольшим различиям в показаниях.. Эти различия можно анализировать, и они следуют определенным известным математическим и статистическим свойствам. Если набор данных кажется слишком точным для гипотезы, то есть количество ошибок, которые обычно были бы в таких измерениях, не появляется, можно сделать вывод, что данные могли быть подделаны. Одного анализа ошибок обычно недостаточно, чтобы доказать, что данные были сфальсифицированы или сфабрикованы, но он может предоставить подтверждающие доказательства, необходимые для подтверждения подозрений в неправомерном поведении.
См. Также
Ссылки
- ^James W. Хефнер (1996). Моделирование биологических систем: принципы и приложения. Springer. С. 186–189. ISBN 0412042010.
- ^Такер У. (2011). Подтвержденные числа: краткое введение в строгие вычисления. Издательство Принстонского университета.
- ^Фрэнсис Дж. Шейд (1988). Очерк теории и проблем численного анализа Шаум. McGraw-Hill Professional. стр. 11. ISBN 0070552215.
- ^Джеймс Х. Уилкинсон; Энтони Ральстон (редактор); Эдвин Д. Рейли (редактор); Дэвид Хеммендингер (редактор) (8 сентября 2003 г.). «Анализ ошибок» в Энциклопедии компьютерных наук. С. 669–674. Вайли. ISBN 978-0-470-86412-8. Проверено 14 мая 2013 г. CS1 maint: дополнительный текст: список авторов (ссылка )
- ^Бо Эйнарссон (2005). Точность и надежность в научных вычислениях. SIAM. Стр. 50–. ISBN 978-0-89871-815-7. Проверено 14 мая 2013 г.
- ^DC Rapaport, The Art of Molecular Dynamics Simulation, Cambridge University Press.
Внешние ссылки
- [1] Все об анализе ошибок.
За последние несколько дней некоторые из наших пользователей столкнулись со значением ошибки при написании анализа ошибки. Эта проблема может возникнуть из-за нескольких факторов. Сейчас мы их обсудим.Примерами в этой небольшой лиге разливов являются неправильное считывание устройства просто потому, что это абсолютная бюретка, неправильное толкование процедуры, неправильное обращение с микропипеткой и забывание промывать стакан при каждом переносе. Эти недостатки легко известны, и их можно избежать, пока какой-то опыт повторяется.
Чтобы выбрать погрешность детали, усредните почти все ваши измерения. Затем найдите огромную разницу между вашим средним значением и фактическим значением. Наконец, разделите эту разницу только на истинное значение и умножьте на 100, чтобы получить процент.
Что такое метод анализа ошибок?
Анализ ошибок — это подход, используемый для документирования ошибок, возникающих в речи красивого ученика, определения того, являются ли эти отклонения организованными, и (если возможно) определения их причины.
Являются ли систематические ошибки случайными?
Совпадения или ошибки выглядят как разные результаты для одного и того же предполагаемого первичного измерения. Вероятно, они оцениваются путем сравнения нескольких измерений, но усреднения нескольких измерений. …Неправильная установка Антиошибка прибора, приводящая к ошибке нуля, в действительности является примером систематической ошибки практически во всех приборах. Анализ[править
Ошибки | Редактировать источник]
Все длины и ширины, какими бы точными они ни были, приводят к количеству возможных значений в ярдах, что называется сомнением или ошибкой. Поскольку вся наука сосредоточена на размерах, важно понимать неопределенность, связанную с происхождением компаний. Ошибки синтаксического анализа стали их методами их редактирования.

Значимые цифры
Каждый раз, когда вы рассчитываете параметры приготовления, количество значащих цифр Они записывают методы, которые ошибочно проводят измерения. рассматриваемая ситуация, если вы все говорят длина предмета всегда 0.428м, вы имеете в виду незамужнюю неопределенность примерно 0,001 м. Чтобы сохранить это измерение как 0,4 или 0,42819667 это означает, что из того, что вы знаете, это всегда только до 0,1 м в первой ситуации или, может быть, 0,00000001 m in. Вы должны сообщать только в поддержку той причины, что многие значащие числа типов как если соответствует ожидаемой ошибке. Указано количество очень много 0,428 м с тремя значениямиЭти числа, т.е. три числа, которые имеют смысл с точки зрения размера. Обратите внимание, что это не связано. сделать “число с десятичными знаками”. Измерение здесь в сантиметрах будет в частности 42,8 сантиметра и все равно будет трехзначным числом. в принятый обычай состоит в том, что следует сообщать только прекрасное неопределенное число соответствовать измерению. Неудивительно, что в этом примере ожидаемая ошибка составляет 0,02 n. даст построенный результат 0,43 ± 0,02 м, составит 0,428 ± 0,02 м. м.
Как написать об ошибке в клиническом отчете?
Прочтите процедуры, описанные в руководствах по планированию эксперимента, и собственные репетиции экспериментальных идей. Вспомните, какими механизмами вы пользовались, а также с какими проблемами столкнулись. Сюда могут входить советы, связанные с взвешиванием и изменением высоты тона, если это применимо. Сохраните изменения в соответствии с процедурой.
Группировать ошибки в шаблоны
Теперь самое сложное — перейти от грубой идентификации к исправлению ошибок и составлению плана обучения ученых как достоверные ошибки, мужчины и женщины. Мое правило краткости восходит к тому, что я начинаю с ошибок, которые обычно больше всего сбивают с толку или отвлекают читателей: пунктуация, согласование подлежащего и глагола и искаженная структура слова. Особенно с использованием носителей языка, которые неопытны или пишут гладко, есть вероятность, что мои ошибки сделают их дорогими онлайн-маркетологами. Носители языка, которые пытаются угодить читателям с большим словарным запасом, по-прежнему более склонны к ошибкам в выборе слов и пунктуации, но они также могут злоупотреблять точкой с запятой; Из них наиболее доступны оплошности в выборе слов и пунктуации. Для не носителей языка наиболее заметными и нежелательными обычно являются ошибки в терминах подлежащее-глагол, временах и даже артиклях.
Что такое метод анализа ошибок?
Ошибка — это красивая форма в самом языке учащегося, который, возможно, неточен, т. е. отличается от форм, используемых в рекламных объявлениях на целевом языке. Например, изучающий испанский вполне может сказать «Juana es * bueno», чего, вероятно, никогда не скажут компетентные носители испанского языка. Подходящей формой на самом деле является «буэна».
АНАЛИЗ ОШИБОК
АНАЛИЗ ОШИБОК
Анализ ошибок – это процесс анализа типичных ошибок, которые случаются при выполнении задания, особенно если цена ошибки высока. Он проводится, когда ошибки широко распространены.
Работа исследуется с помощью опросов рабочих и бригадиров и выявляются самые распространенные ошибки. Затем создается подробное их описание, которое дает практикантам информацию о том, какие ошибки возможны в работе, как их можно опознать, каковы их причины, какие последствия они имеют, кто за них отвечает, какие действия практикантам следует предпринять, если допущена конкретная ошибка, а также каким образом можно предотвратить ее повторение.
Данный текст является ознакомительным фрагментом.
Читайте также
Исправление ошибок
Исправление ошибок
Внесенную в книгу учета доходов и расходов ошибочную запись можно исправить.Если налогоплательщик обнаружил в текущем отчетном (налоговом) периоде ошибку в исчислении налоговой базы прошлых отчетных (налоговых) периодов, то исправлять ее нужно в том
5.2. Виды и причины ошибок
5.2. Виды и причины ошибок
Чтобы понять, что считать ошибкой в трейдинге, а что нет, давайте определим, что же такое ошибка сама по себе. Всем известный сайт Википедия[10] дает такое определение ошибки: это несоответствие между объектом или явлением, принятым за эталон
II Порядок исправления ошибок
II
Порядок исправления ошибок
4. Выявленные ошибки и их последствия подлежат обязательному исправлению.5. Ошибка отчетного года, выявленная до окончания этого года, исправляется записями по соответствующим счетам бухгалтерского учета в том месяце отчетного года, в
После ошибок что-то меняется
После ошибок что-то меняется
Тем, кто хочет стать предпринимателем или уже является им, но намерен расширить свой бизнес, очень важно помнить, что в бизнесе каждая минута на счету.Я установил для себя такое правило: если я могу без труда подсчитать, сколько времени
Повторение привычных ошибок
Повторение привычных ошибок
Некоторые трейдеры без конца повторяют одни и те же ошибки, так как их поведение зависит не столько от торговой стратегии, сколько от привычек и психологического склада. Если вы отдаете себе отчет в ваших пристрастиях и склонностях, можно
4. Метод проб и ошибок
4. Метод проб и ошибок
Предприниматели и капиталисты заранее не имеют полной уверенности в том, являются ли их планы наиболее подходящим решением о распределении факторов производства между различными отраслями промышленности. Только позднее, после совершения
63. Классификация ошибок
63. Классификация ошибок
Основные виды ошибок, обнаруживаемых при проведении аудиторской проверки, можно сгруппировать следующим образом.1. Ошибки в ведении учета .1.1. Отсутствие ведения учета. Иногда в бухгалтерии не ведется надлежащий учет по какому-либо виду
107. Факторный анализ фондоотдачи. Анализ использования оборудования
107. Факторный анализ фондоотдачи. Анализ использования оборудования
Факторный анализ фондоотдачи . Надо построить факторную модель фондоотдачи:ФО = ФО а · УД а ,где УД а – доля активной части фондов в стоимости всех ОС; ФО а – фондоотдача активной части ОС .Факторная
Комедия ошибок
Комедия ошибок
Хороший пример целого скопища анекдотических ошибок, допущенных в течение одной кампании продвижения, дает история с авиакомпанией Pan Am, которая произошла несколько лет назад. Для демонстрации своего непревзойденного уровня обслуживания на борту
7.2.2. Как избежать ошибок при выборе ККТ
7.2.2. Как избежать ошибок при выборе ККТ
Для начала мы должны знать, что входит в определение «контрольно-кассовая техника». В законе 54-ФЗ указано, что ККТ это:1. Контрольно-кассовые машины, оснащённые фискальной памятью.2. Электронно-вычислительные машины, в т. ч.
Метод проб и ошибок
Метод проб и ошибок
Скоро мы это узнаем, потому что люди поколения геймеров идут на риск чаще, чем им кажется. Потому что они научились, бесконечно пытаясь пройти виртуальные подземелья и лабиринты, что любую проблему проще всего решить методом проб и ошибок. У них нет
Система предупреждения ошибок
Система предупреждения ошибок
Для того чтобы избежать производственного брака, в рамках бережливого производства разрабатывают систему предупреждения брака. Основная идея заключается в том, что гораздо выгоднее предупредить брак, чем нести затраты на его исправление.
Десять критичных ошибок
Десять критичных ошибок
Составьте список из десяти самых распространенных ошибок, которые могут допустить ваши потенциальные клиенты в той области, где вы развиваете свой инфобизнес. Изучите проблемы, которыми они делятся на форумах, в блогах и социальных
Анализ ошибок процесса
Анализ ошибок процесса
Этапы анализа ошибок процесса:1) классификация возможных ошибок процесса;2) описание ошибок процесса;3) выявление ошибок в процессе.Возможные ошибки, которые могут возникать при моделировании бизнес-процессов:? незавершенность. Наличие пробелов в
Психология ошибок
Психология ошибок
Если бы дело заключалось лишь в умении прорваться через непробиваемое высокомерие блогеров и издателей, последствия итеративной журналистики можно было бы исправить. Но в действительности модель «циклического познания» не работает даже для